spark实战之网站日志分析
前面一篇应该算是比较详细的介绍了spark的基础知识,在了解了一些spark的知识之后相必大家对spark应该不算陌生了吧!如果你之前写过MapReduce,现在对spark也很熟悉的话我想你再也不想用MapReduce去写一个应用程序了,不是说MapReduce有多繁琐(相对而言),还有运行的效率等问题。而且用spark写出来的程序比较优雅,这里我指的是scala版的,如果你用java版的spark去写一个应用程序,对比scala版的,想必你肯定会爱上scala这门语言的,哈哈哈(以上纯属个人观点,具体场景具体对待)
实现目标1:根据采集的日志信息,统计总的pv量 。
需求分析:在大数据领域,采集数据的常采用的手段就是怼网站进行埋点然后根据需求收集相关的数据,这里我们用的是最基本的日志信息来做处理,数据来源于某网站,可以分享出来给大家使用,完了后我会将代码还有数据 文件放到GitHub上供大家下载。首先我们来看看日志文件(access.log)的格式:

这是标准的一条日志信息,当然我们如果是统计网站的pv总量的话不需要考虑对日志进行清洗的工作。以下是pv统计的代码:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} //todo:利用Spark程序统计运营商pv总量
object PV extends App{
//创建sparkConf对象
private val sparkConf: SparkConf = new SparkConf().setAppName("PV").setMaster("local[2]")
//创建SparkContext对象
private val sc: SparkContext = new SparkContext(sparkConf)
//设置输出的日志级别
sc.setLogLevel("WARN")
//读取日志数据
private val dataRDD: RDD[String] = sc.textFile("E:\\access.log")
//统计pv总量====方式一:计算有多少行及pv总量
private val finalResult1: Long = dataRDD.count()
println(finalResult1)
//方式二:每一条日志信息记为一条数据1
private val pvOne: RDD[(String, Int)] = dataRDD.map(x=>("PV",))
//对pv根据key进行累加
private val resultPV: RDD[(String, Int)] = pvOne.reduceByKey(_+_)
//打印pv总量
resultPV.foreach(x=>println(x))
//关闭资源
sc.stop()
}
结果如下:

实现目标2:根据采集的日志信息,统计总的uv量 。
需求分析:目标数据文件还是access.log,比较简单,直接看代码:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
//todo:利用spark统计运营商uv总量
object UV extends App{
//创建sparkConf对象
private val sparkConf: SparkConf = new SparkConf().setAppName("PV").setMaster("local[2]")
//创建SparkContext对象
private val sc: SparkContext = new SparkContext(sparkConf)
//设置输出的日志级别
sc.setLogLevel("WARN")
//读取日志数据
private val dataRDD: RDD[String] = sc.textFile("E:\\access.log")
//切分每一行,获取对应的ip地址
private val ips: RDD[String] = dataRDD.map(_.split(" ")())
//去重
private val ipNum: Long = ips.distinct().count()
println(ipNum)
//g关闭资源
sc.stop()
}
结果 如下:

实现目标3:根据采集的日志信息,统计访问最多的前五位网站降序排列 TopN。
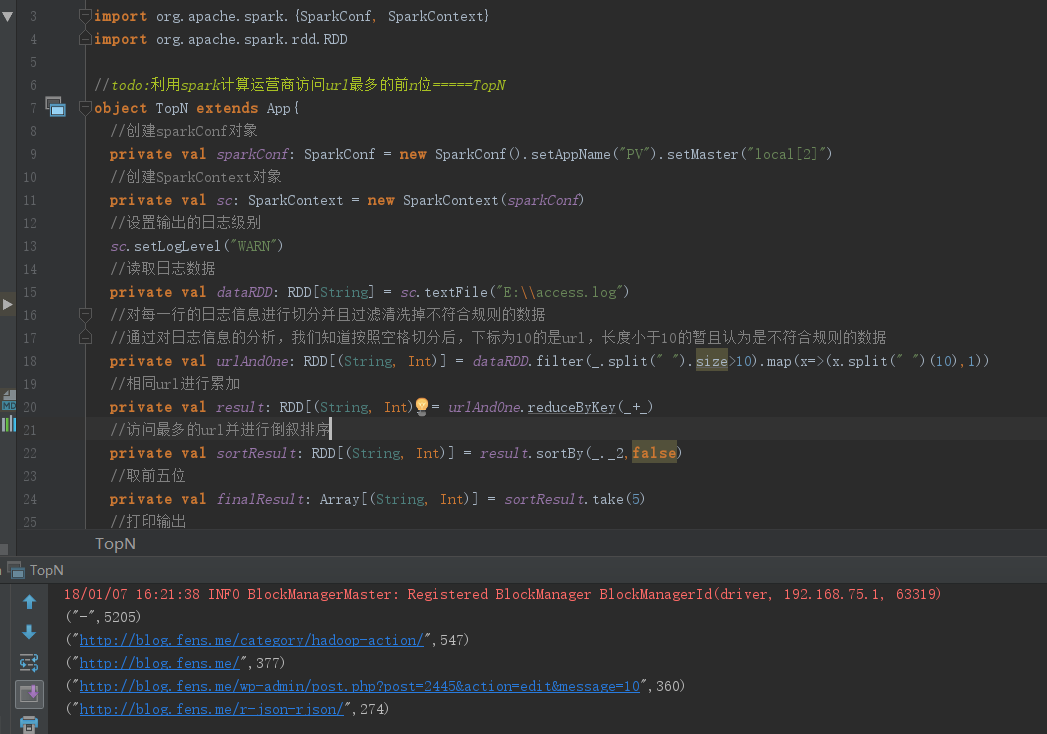
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
//todo:利用spark计算运营商访问url最多的前n位=====TopN
object TopN extends App{
//创建sparkConf对象
private val sparkConf: SparkConf = new SparkConf().setAppName("PV").setMaster("local[2]")
//创建SparkContext对象
private val sc: SparkContext = new SparkContext(sparkConf)
//设置输出的日志级别
sc.setLogLevel("WARN")
//读取日志数据
private val dataRDD: RDD[String] = sc.textFile("E:\\access.log")
//对每一行的日志信息进行切分并且过滤清洗掉不符合规则的数据
//通过对日志信息的分析,我们知道按照空格切分后,下标为10的是url,长度小于10的暂且认为是不符合规则的数据
private val urlAndOne: RDD[(String, Int)] = dataRDD.filter(_.split(" ").size>).map(x=>(x.split(" ")(),))
//相同url进行累加
private val result: RDD[(String, Int)] = urlAndOne.reduceByKey(_+_)
//访问最多的url并进行倒叙排序
private val sortResult: RDD[(String, Int)] = result.sortBy(_._2,false)
//取前五位
private val finalResult: Array[(String, Int)] = sortResult.take()
//打印输出
finalResult.foreach(println)
sc.stop()
}
运行结果:
spark实战之网站日志分析的更多相关文章
- 基于Spark的网站日志分析
本文只展示核心代码,完整代码见文末链接. Web Log Analysis 提取需要的log信息,包括time, traffic, ip, web address 进一步解析第一步获得的log信息,如 ...
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
网站日志分析项目案例(一)项目介绍:当前页面 网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html 网站日志分析项目案例 ...
- Spark SQL慕课网日志分析(1)--系列软件(单机)安装配置使用
来源: 慕课网 Spark SQL慕课网日志分析_大数据实战 目标: spark系列软件的伪分布式的安装.配置.编译 spark的使用 系统: mac 10.13.3 /ubuntu 16.06,两个 ...
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:当前页面 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:http://www.cnbl ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- Hadoop学习笔记—20.网站日志分析项目案例
1.1 项目来源 本次要实践的数据日志来源于国内某技术学习论坛,该论坛由某培训机构主办,汇聚了众多技术学习者,每天都有人发帖.回帖,如图1所示. 图1 项目来源网站-技术学习论坛 本次实践的目的就在于 ...
- Apache 网站日志分析
1.获得访问前 10 位的 ip 地址 [root@apache ~]# cat access_log |awk '{print $1}'|sort|uniq -c|sort -nr|head -10 ...
- Spark 实践——基于 Spark Streaming 的实时日志分析系统
本文基于<Spark 最佳实践>第6章 Spark 流式计算. 我们知道网站用户访问流量是不间断的,基于网站的访问日志,即 Web log 分析是典型的流式实时计算应用场景.比如百度统计, ...
随机推荐
- python3+Appium自动化06-屏幕截图
截图方法 save_screenshot() 该方法直接保存当前屏幕截图到当前脚本所在文件位置 driver.save_screenshot('login.png') get_screenshot_a ...
- 【tf.keras】tf.keras加载AlexNet预训练模型
目录 从 PyTorch 中导出模型参数 第 0 步:配置环境 第 1 步:安装 MMdnn 第 2 步:得到 PyTorch 保存完整结构和参数的模型(pth 文件) 第 3 步:导出 PyTorc ...
- Spring4.x、SpringMVC和DButils整合
tomcat 8.Spring 4.X.JDK1.8 需要jar包: 1)日志组件:log4j # debug < info < warn < error log4j.rootLog ...
- Oracle11G的用户解锁、卸载以及基础操作
Oracle用户解锁 [以下操作,必须以超级管理员身份登录,才能修改]oracle安装后,会默认生成很多个用户 以超级管理员身份登录,请注意,其中的空格符:[ sys是一个超级管理员,有最大的权限,d ...
- HDU 5465——Clarke and puzzle——————【树状数组BIT维护前缀和+Nim博弈】
Clarke and puzzle Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others ...
- 傻瓜式的go modules的讲解和代码,及gomod能不能引入另一个gomod和gomod的use of internal package xxxx not allowed
一 国内关于gomod的文章,哪怕是使用了百度 -csdn,依然全是理论,虽然golang的使用者大多是大神但是也有像我这样的的弱鸡是不是? 所以,我就写个傻瓜式教程了. github地址:https ...
- LitePal——安卓数据库library
简介:一个让开发者使用SQLite数据库更加容易的库文件 LitePal for Android,项目地址:点击打开 LitePal是一个开源的android库,它让开发者使用SQLite数据变得容易 ...
- mybatis-plus 异常 Invalid bound statement (not found)
最近吧项目中添加使用了mybatis-plus,发现操作sql的时候出现异常: Invalid bound statement (not found) ,异常位置位于mybatis-plus的jar中 ...
- tomcat的备份脚本
reference:Crontab的20个例子 先科普一下date的使用方法,在sh脚本中经常会使用得到 date -d<字符串>:显示字符串所指的日期与时间.字符串前后必须加上双引号: ...
- 工作中遇到的有关echarts地图和百度地图的问题
工作中遇到的有关echarts地图和百度地图的问题 *** 前言:在做项目中需要制作一个场景是左边是柱状图,右边是地图,地图上悬浮一个按钮可以切换echarts地图和百度地图.*** 功能: 在点击左 ...