Hadoop全分布式模式安装
一、准备
1、准备至少三台linux服务器,并安装JDK
关闭防火墙如下
systemctl stop firewalld.service
systemctl disable firewalld.service
2、使用xshell工具,连接三台机器上,同时输入命令操作三台机器,只要如图勾选上即可
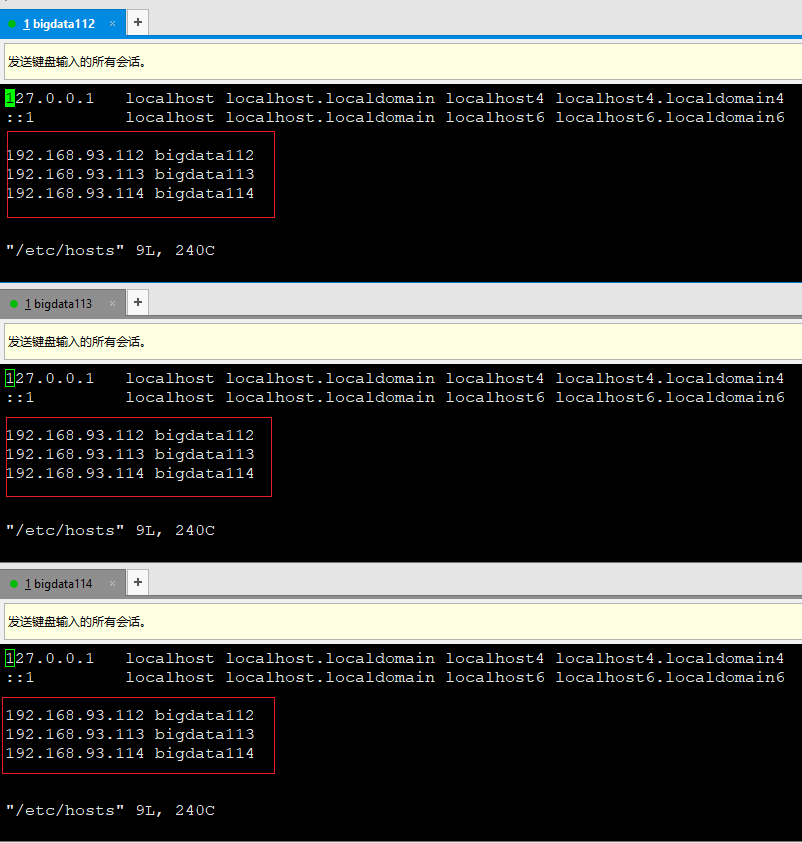
1)配置域名与Ip映射关系 vi /etc/hosts
2)配置免密登陆,需每台机器上都生成密钥对,将各自的公钥传输到其他机器上
输入命令:ssh-keygen -t rsa 回车生成密钥对
ssh-copy-id -i .ssh/id_rsa.pub root@bidata112
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata113
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata114
3)保证集群的时间同步
date -s 小时:分钟
二、在主节点上安装hadoop (bigdata112)
1、上传并解压hadoop
2、配置/etc/hadoop下的几个文件,hadoop-env.sh,
export JAVA_HOME=/root/training/jdk1.8.0_144
3、hdfs-site.xml
<!--配置数据块的冗余度,默认是3-->
<!--原则冗余度跟数据节点个数保持一致,最大不要超过3-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--是否开启HDFS的权限检查,默认是true-->
<!--使用默认值,后面会改为false-->
<!--
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
-->
4、core-site.xml
<!--配置HDFS主节点的地址,就是NameNode的地址-->
<!--9000是RPC通信的端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata112:9000</value>
</property>
<!--HDFS数据块和元信息保存在操作系统的目录位置-->
<!--默认是Linux的tmp目录,一定要修改-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
5、mapred-site.xml
<!--MR程序运行容器或者框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6、yarn-site.xml
<!--配置Yarn主节点的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata112</value>
</property>
<!--NodeManager执行MR任务的方式是Shuffle洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
7、slaves 配置从节点地址
bigdata113
bigdata114
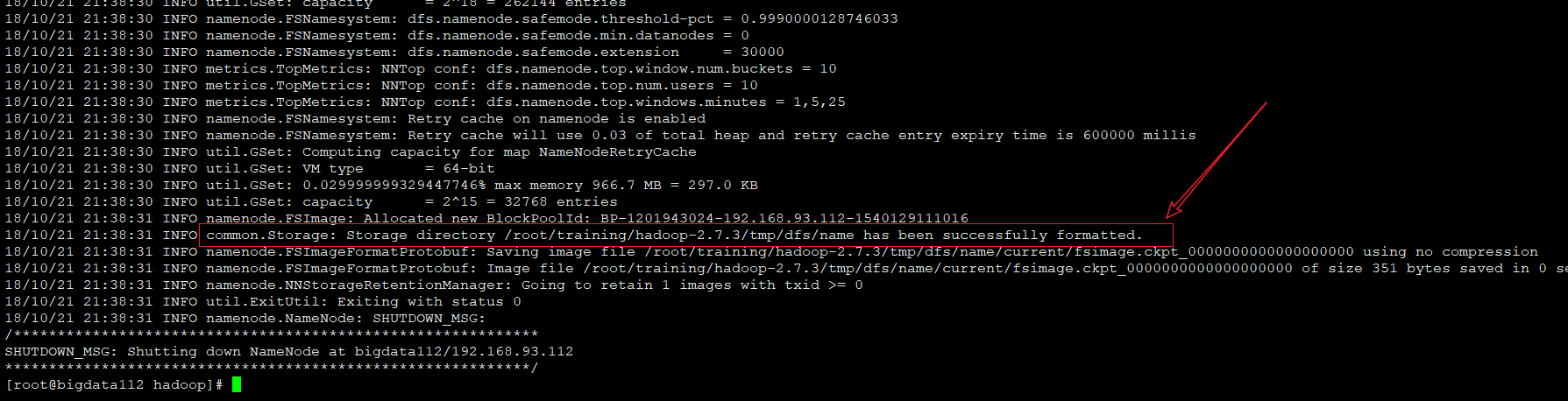
8、对namenode进行格式化
hdfs namenode -format
出现红色部分表示格式化成功
三、把安装好的hadoop复制到从节点
scp -r hadoop-2.7.3/ root@bigdata113:/root/training
scp -r hadoop-2.7.3/ root@bigdata114:/root/training
四、在主节点上启动集群
start-all.sh
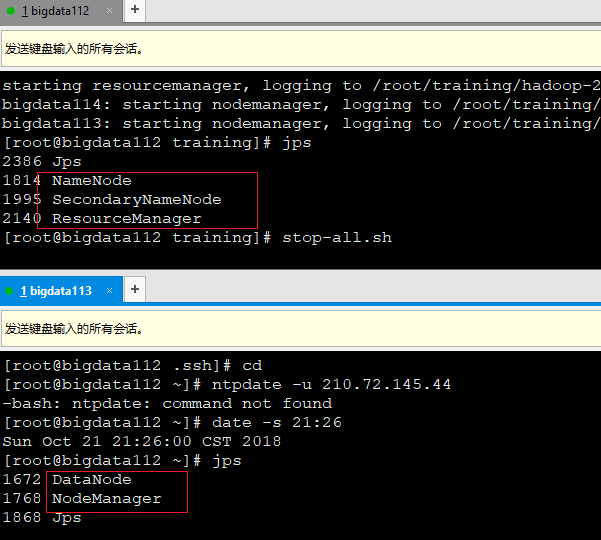
到此全分布式模式安装结束,并能成功启动服务
Hadoop全分布式模式安装的更多相关文章
- Hadoop完全分布式模式安装部署
在Linux上搭建Hadoop系列:1.Hadoop环境搭建流程图2.搭建Hadoop单机模式3.搭建Hadoop伪分布式模式4.搭建Hadoop完全分布式模式 注:此教程皆是以范例讲述的,当然你可以 ...
- 初学者值得拥有【Hadoop伪分布式模式安装部署】
目录 1.了解单机模式与伪分布模式有何区别 2.安装好单机模式的Hadoop 3.修改Hadoop配置文件---五个核心配置文件 (1)hadoop-env.sh 1.到hadoop目录中 2.修 ...
- Hadoop伪分布式模式安装
一.Hadoop介绍 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上:而且 ...
- VMware workstation 下Hadoop伪分布式模式安装
详细过程: 1.VMware安装: 2.centos 6 安装 3.jdk下载安装配置 4.Hadoop 安装配置 1.VMware Workstation 安装: https://www.vmwar ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- HBase入门基础教程之单机模式与伪分布式模式安装(转)
原文链接:HBase入门基础教程 在本篇文章中,我们将介绍Hbase的单机模式安装与伪分布式的安装方式,以及通过浏览器查看Hbase的用户界面.搭建HBase伪分布式环境的前提是我们已经搭建好了Had ...
- Hadoop伪分布式模式搭建
title: Hadoop伪分布式模式搭建 Quitters never win and winners never quit. 运行环境: Ubuntu18.10-server版镜像:ubuntu- ...
随机推荐
- Game Engine Architecture
- 加载动画插件spin.js的使用随笔
背景: 在请求后台的“漫长”等待过程中,为了提升用户体验,需要一个类似 的加载动画效果,让用户明确现在处于请求过程中,而不是机子down掉或者网站死了 静态demo(未与后台交互): HTML代码如 ...
- windows7桌面小工具打不开的解决方案
将任务管理器中的sidebar.exe结束任务: 将C:\Users\用户名\AppData\Local\Microsoft\Windows Sidebar下的settings.ini的文件名修改为任 ...
- JS等号的小注释
一言以蔽之:一个等号是赋值操作,==先转换类型再比较,===先判断类型,如果不是同一类型直接为false.
- centos7 python3 Saltstack配置
Python安装完毕后,提示找不到ssl模块 pip is configured with locations that require TLS/SSL, however the ssl module ...
- Understanding NFS Caching
Understanding NFS Caching Filesystem caching is a great tool for improving performance, but it is im ...
- PAT (Basic Level) Practise (中文)- 1012. 数字分类 (20)
http://www.patest.cn/contests/pat-b-practise/1012 给定一系列正整数,请按要求对数字进行分类,并输出以下5个数字: A1 = 能被5整除的数字中所有偶数 ...
- Unity学习之路——主要类
学习https://blog.csdn.net/VRunSoftYanlz/article/details/78881752 1.Component类gameObject:组件附加的游戏对象.组件总是 ...
- PAT 乙级 1051
题目 题目地址:PAT 乙级 1051 思路 最近做题发现一个比较明显的现象——总是在做简单题的过程中出现这样那样的小问题,究其原因我认为还是有很多细节性的知识没有掌握,这是在以后的学习过程中需要注意 ...
- HDU-4848-Such Conquering
这题就是深搜加剪枝,有一个很明显的剪枝,因为题目中给出了一个deadline,所以我们一定要用这个deadline来进行剪枝. 题目的意思是求到达每个点的时间总和,当时把题看错了,卡了好久. 剪枝一: ...