MapReduce(二)
MapReduce(二)
mapreduce 将Text转化为对象进行处理数据。
根据一来说,将date,classname,name,subject,score变为对象属性
我的数据是:是有重复的。
package com.huhu.day02;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class Score implements WritableComparable<Score> {
private String date;
private String classname;
private String name;
private String subject;
private int score;
public Score() {
super();
// TODO Auto-generated constructor stub
}
public Score(String date, String classname, String name, String subject, int score) {
super();
this.date = date;
this.classname = classname;
this.name = name;
this.subject = subject;
this.score = score;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getClassname() {
return classname;
}
public void setClassname(String classname) {
this.classname = classname;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSubject() {
return subject;
}
public void setSubject(String subject) {
this.subject = subject;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "Score [date=" + date + ", classname=" + classname + ", name=" + name + ", subject=" + subject
+ ", score=" + score + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((classname == null) ? 0 : classname.hashCode());
result = prime * result + ((date == null) ? 0 : date.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + score;
result = prime * result + ((subject == null) ? 0 : subject.hashCode());
return result;
}
@Override
public void readFields(DataInput in) throws IOException {
this.date = in.readUTF();
this.classname = in.readUTF();
this.name = in.readUTF();
this.subject = in.readUTF();
this.score = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.date);
out.writeUTF(this.classname);
out.writeUTF(this.name);
out.writeUTF(this.subject);
out.writeInt(this.score);
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Score other = (Score) obj;
if (classname == null) {
if (other.classname != null)
return false;
} else if (!classname.equals(other.classname))
return false;
if (date == null) {
if (other.date != null)
return false;
} else if (!date.equals(other.date))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (score != other.score)
return false;
if (subject == null) {
if (other.subject != null)
return false;
} else if (!subject.equals(other.subject))
return false;
return true;
}
@Override
public int compareTo(Score o) {
if (this.date.equals(o.date)) {
if (this.classname.equals(o.classname)) {
if (this.name.equals(o.name)) {
if (this.subject.equals(o.subject)) {
return this.score - o.score;
} else {
return this.subject.compareTo(o.subject);
}
} else {
return this.name.compareTo(o.name);
}
} else {
return this.classname.compareTo(o.classname);
}
} else {
return this.date.compareTo(o.date);
}
}
}该自定义类使用实现了WritableComparable<>类是为了序列化该类然后进入mapreduce方法中,实现compareTo是为了mapreduce根据key排序,当该int字段返回 0 证明key相同。如果返回大于1则是升序,返回小于1降序。
package com.huhu.day02;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ScoreCount extends ToolRunner implements Tool {
public static class MyMapper extends Mapper<LongWritable, Text, Score, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(" ");
Score score = null;
if (line.length == 5) {
score = new Score(line[0], line[1], line[2], line[3], Integer.parseInt(line[4]));
}
context.write(score, NullWritable.get());
}
}
public static class MyReduce extends Reducer<Score, NullWritable, Score, Text> {
@Override
protected void reduce(Score key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
int count = 1;
for (NullWritable v : values) {
context.write(key, new Text(count + "-------" ));
count++;
}
}
}
@Override
public Configuration getConf() {
return new Configuration();
}
@Override
public void setConf(Configuration arg0) {
}
@Override
public int run(String[] other) throws Exception {
Job job = Job.getInstance(getConf(), "ScoreCount");
job.setJarByClass(ScoreCount.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Score.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Score.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(other[0]));
FileOutputFormat.setOutputPath(job, new Path(other[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
if (other.length != 2) {
System.out.println("your input args number is fail,you need input <in> and <out>");
System.exit(0);
}
ToolRunner.run(conf, new ScoreCount(), other);
}
}此时输出的结果是:此时equalse和compareTo方法都有

数据相同的可以认识,然后后面的计数器就赋予它原来的值,而不是累加。
让我们去掉equals方法再测试一遍。

发现并没有什么不同,好的,那我们去掉将compareto的方法的内容去掉,直接返回1;
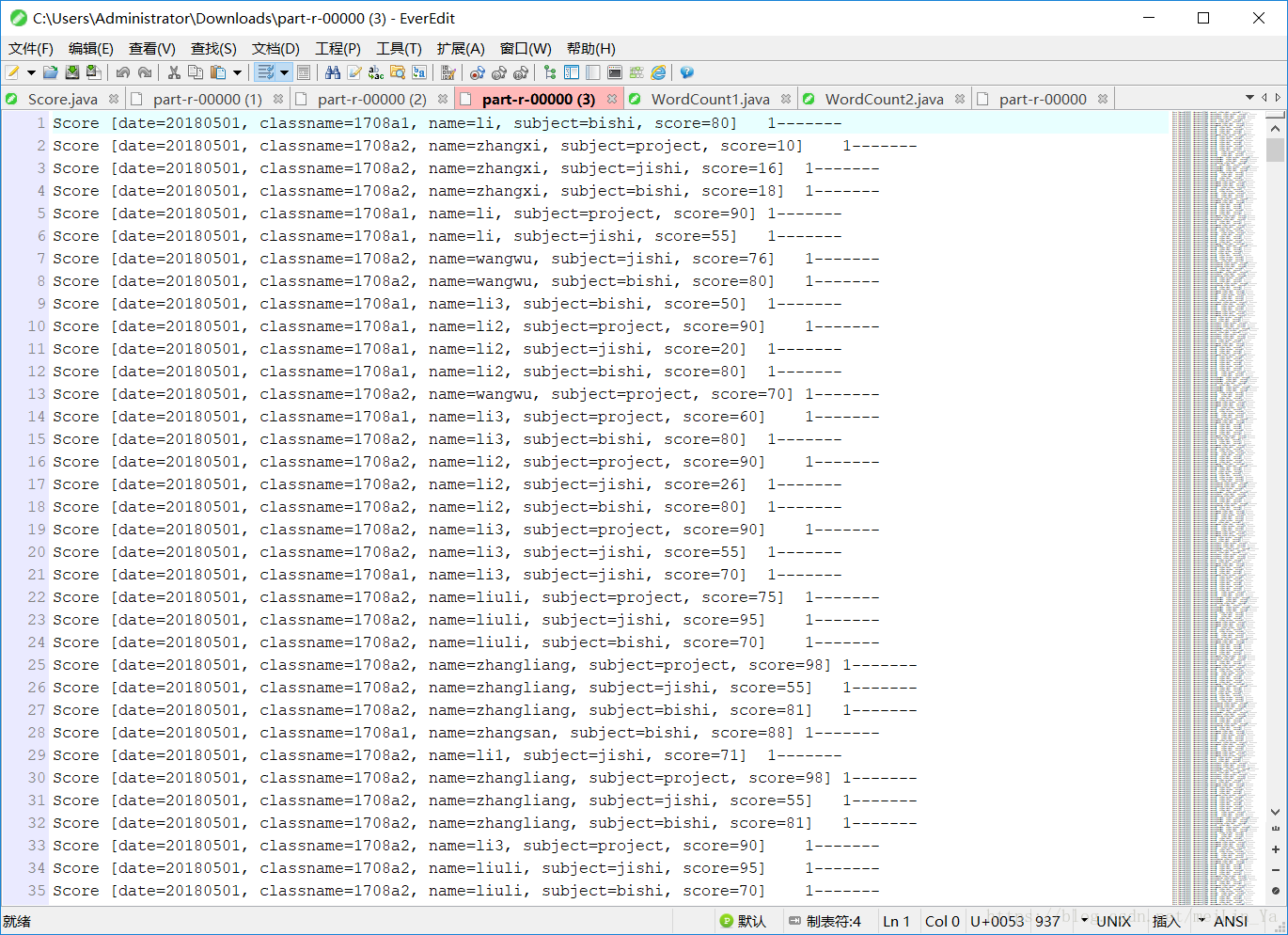
发现计数器都是1,也就是说没有一个数据是相同的,但是我的数据里面明明是相同的数据啊,是为什么,因为
此时数据按升序排列,然后我们将compareto返回值调为-1

此时数据是按降序排序。
在compareto中String字符串是将字符串转化为ascii码表的值(字符所对应的十进制值) 相加然后进行比较大小。
MapReduce
将Text文本对象化,传一个序列化对象后,利用对象属性字段取值并使用值,比切割字符串方式取值方便,并且在自定义类中使用添加方法如equalse方法和comparto方法是mapreduce中的key进行排序。从而简化yarn对的数据操作过程,利用了java的一切皆对象的思想。
MapReduce(二)的更多相关文章
- Hadoop学习笔记: MapReduce二次排序
本文给出一个实现MapReduce二次排序的例子 package SortTest; import java.io.DataInput; import java.io.DataOutput; impo ...
- (转)MapReduce二次排序
一.概述 MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的.在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求 ...
- 详细讲解MapReduce二次排序过程
我在15年处理大数据的时候还都是使用MapReduce, 随着时间的推移, 计算工具的发展, 内存越来越便宜, 计算方式也有了极大的改变. 到现在再做大数据开发的好多同学都是直接使用spark, hi ...
- MapReduce二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
- 关于MapReduce二次排序的一点解答
上一篇博客说明了怎么自定义Key,而且用了二次排序的例子来做测试,但没有详细的说明二次排序,这一篇说详细的说明二次排序,为了说明曾经一个思想的误区,特地做了一个3个字段的二次排序来说明.后面称其为“三 ...
- MapReduce(二) MR的高级特性-序列化、排序、分区、合并
一.序列化 (*) 核心接口:Writable接口.如果有一个类实现了Writable接口,就可以作为Map/Reduce的key和value. 举例: 读取员工数据,生成员工对象,直接存储 ...
- mapreduce二次排序详解
什么是二次排序 待排序的数据具有多个字段,首先对第一个字段排序,再对第一字段相同的行按照第二字段排序,第二次排序不破坏第一次排序的结果,这个过程就称为二次排序. 如何在mapreduce中实现二次排序 ...
- MapReduce(二)常用三大组件
mapreduce三大组件:Combiner\Sort\Partitioner 默认组件:排序,分区(不设置,系统有默认值) 一.mapreduce中的Combiner 1.什么是combiner C ...
- MapReduce 二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
随机推荐
- mapgis IGServer账号
2064803644@qq.com 1576391020@qq.com 密码一样
- 【Python】【有趣的模块】【requests】【一】HTTP头信息总结
[HTTP请求 == 请求行 + 消息报头 + 请求正文 ] 请求行:Method Request-URL HTTP-Version CRLF HTTP协议定义了许多与服务器交互的方法 ① PUT:请 ...
- Codeforces 85 D. Sum of Medians
题目链接:http://codeforces.com/contest/85/problem/D 做法果然男默女泪啊..... 大概就是直接开了一个$vector$每次插入删除都用自带的$insert$ ...
- 使用CSS渐变
转载自:https://developer.mozilla.org/zh-CN/docs/Web/Guide/CSS/Using_CSS_gradients CSS 渐变 是在 CSS3 Image ...
- CentOS6.X、7.X下Jenkins的安装及使用
一.相关概念 1.1 Jenkins概念: Jenkins是一个功能强大的应用程序,允许持续集成和持续交付项目,无论用的是什么平台.这是一个免费的源代码,可以处理任何类型的构建或持续集成.集成Jenk ...
- Angular 学习笔记 ( 创建 library, 转换老旧的 library )
更新 : 2018-10-28 不知道为什么在 ng 跑一直做不到 .d.ts 最后发现,如果有一个插件 propagating-hammerjs.ts 那么就在 root create 一个 pro ...
- 第 8 章 容器网络 - 057 - macvlan 网络隔离和连通
macvlan 网络隔离和连通 验证 macvlan 之间的连通性. bbox1 能 ping 通 bbox3,bbox2 能 ping 通 bbox4. 即:同一 macvlan 网络能通信. bb ...
- 关于类、方法、对象(实例):通过一个例子看一下self都做了哪些事情
我们在定义一个类时,经常会在类的各个方法中看到self,那么在程序执行时self到底起了什么作用,什么时候要加self,这一点需要我们思考并好好理解.之前在学习时没有想这么多,加之用pycharm写代 ...
- 在不进入Guest OS的情况下,取得Guest OS的IP地址
因为是个Headless 服务器,总是需要GUI VNC 到 Host OS, 然后进入里面的虚拟机,打 ipconfig / ifconfig ,非常的不方便. 查了网上,找到上面的方法 1)确保 ...
- ROC曲线(receiver-operating-characteristic curve)-阈值评价标准(转)
转自:http://blog.csdn.net/abcjennifer/article/details/7359370 ROC曲线指受试者工作特征曲线 / 接收器操作特性曲线(receiver ope ...