RNN-LSTM-GRU-BIRNN
https://blog.csdn.net/wangyangzhizhou/article/details/76651116 共三篇
RNN的模型展开后多个时刻隐层互相连接,而所有循环神经网络都有一个重复的网络模块,RNN的重复网络模块很简单,如下下图,比如只有一个tanh层。

而LSTM的重复网络模块的结构则复杂很多,它实现了三个门计算,即遗忘门、输入门和输出门。每个门负责是事情不一样,遗忘门负责决定保留多少上一时刻的单元状态到当前时刻的单元状态;输入门负责决定保留多少当前时刻的输入到当前时刻的单元状态;输出门负责决定当前时刻的单元状态有多少输出。
每个LSTM包含了三个输入,即上时刻的单元状态、上时刻LSTM的输出和当前时刻输入。

https://blog.csdn.net/thriving_fcl/article/details/73381217
主要参考的论文是Hierarchical Attention Networks for Document Classification。这里的层次Attention网络并不是只含有Attention机制的网络,而是在双向RNN的输出后加了Attention机制,层次表现在对于较长文本的分类,先将词向量通过RNN+Attention表示为句子向量,再将句子向量通过RNN+Attention表示为文档向量。两部分的Attention机制是一样的,这篇博客就不重复说明了。
BIRNN

attention
1. 原来的Encoder–Decoder
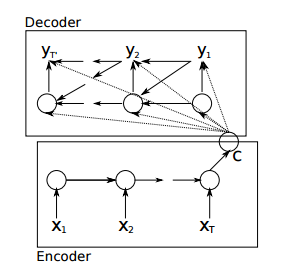
在这个模型中,encoder只将最后一个输出递给了decoder,这样一来,decoder就相当于对输入只知道梗概意思,而无法得到更多输入的细节,比如输入的位置信息。
2. 对齐问题
前面说了,只给我递来最后一个输出,不好;但如果把每个step的输出都传给我,又有一个问题了,怎么对齐?
什么是对齐?比如说英文翻译成中文,假设英文有10个词,对应的中文翻译只有6个词,那么就有了哪些英文词对哪些中文词的问题了嘛。
3. attention机制
https://www.cnblogs.com/shixiangwan/p/7573589.html
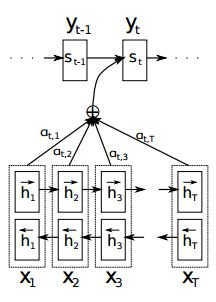
这个g可以用一个小型的神经网络来逼近,它用来计算St−1 、hj这两者的关系分数,如果分数大则说明关注度较高,注意力分布就会更加集中在这个输入单词上,这个函数在文章Neural Machine Translation by Jointly Learning to Align and Translate(2014)中称之为校准模型(alignment model),文中提到这个函数是RNN前馈网络中的一系列参数,在训练过程会训练这些参数。
把四个公式串起来看,这个attention机制可以总结为一句话:当前一步输出St应该对齐哪一步输入,主要取决于前一步输出St−1和这一步输入的encoder结果hj。
(该结论有时表述为只与encoder结果有关)
RNN-LSTM-GRU-BIRNN的更多相关文章
- RNN,LSTM,GRU基本原理的个人理解
记录一下对RNN,LSTM,GRU基本原理(正向过程以及简单的反向过程)的个人理解 RNN Recurrent Neural Networks,循环神经网络 (注意区别于recursive neura ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- RNN/LSTM/GRU/seq2seq公式推导
概括:RNN 适用于处理序列数据用于预测,但却受到短时记忆的制约.LSTM 和 GRU 采用门结构来克服短时记忆的影响.门结构可以调节流经序列链的信息流.LSTM 和 GRU 被广泛地应用到语音识别. ...
- RNN - LSTM - GRU
循环神经网络 (Recurrent Neural Network,RNN) 是一类具有短期记忆能力的神经网络,因而常用于序列建模.本篇先总结 RNN 的基本概念,以及其训练中时常遇到梯度爆炸和梯度消失 ...
- RNN & LSTM & GRU 的原理与区别
RNN 循环神经网络,是非线性动态系统,将序列映射到序列,主要参数有五个:[Whv,Whh,Woh,bh,bo,h0][Whv,Whh,Woh,bh,bo,h0],典型的结构图如下: 和普通神经网 ...
- [PyTorch] rnn,lstm,gru中输入输出维度
本文中的RNN泛指LSTM,GRU等等 CNN中和RNN中batchSize的默认位置是不同的. CNN中:batchsize的位置是position 0. RNN中:batchsize的位置是pos ...
- RNN, LSTM, GRU cells
项目需要,先简记cell,有时间再写具体改进原因 RNN cell LSTM cell: GRU cell: reference: 1.https://towardsdatascience.com/a ...
- RNN,GRU,LSTM
2019-08-29 17:17:15 问题描述:比较RNN,GRU,LSTM. 问题求解: 循环神经网络 RNN 传统的RNN是维护了一个隐变量 ht 用来保存序列信息,ht 基于 xt 和 ht- ...
- 自己动手实现深度学习框架-7 RNN层--GRU, LSTM
目标 这个阶段会给cute-dl添加循环层,使之能够支持RNN--循环神经网络. 具体目标包括: 添加激活函数sigmoid, tanh. 添加GRU(Gate Recurrent U ...
- NLP教程(5) - 语言模型、RNN、GRU与LSTM
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
随机推荐
- 使用 NumPy 和 Matplotlib 绘制函数图
Numpy是用python进行科学计算的基本程序包. 它主要包含以下功能: ♦强大的n维数组对象 ♦复杂(广播)函数工具 ♦用于集成c/c++和Fortran代码-有用的线性代数 ♦傅里叶变换和随机数 ...
- laravel中的数据库迁移
1.创建数据库迁移文件:生成数据库迁移文件,前面跟着时间戳: php artisan make:migration create_posts_table 创建数据库迁移文件:可以重命名数据表名: -- ...
- day1 计算机硬件基础
CPU包括运算符和逻辑符 储存器包括内存和硬盘 7200转的机械硬盘一般找到想要的数据需要9毫秒的时间 4+5 5毫秒的时间是磁头到磁盘轨道 4毫秒是平均开始查找想要的数据到找到的 ...
- 顺便谈谈对于Java程序猿学习当中各个阶段的建议
引言 其实本来真的没打算写这篇文章,主要是LZ得记忆力不是很好,不像一些记忆力强的人,面试完以后,几乎能把自己和面试官的对话都给记下来.LZ自己当初面试完以后,除了记住一些聊过的知识点以外,具体的内容 ...
- 项目导入时报错:The import javax.servlet.http.HttpServletRequest cannot be resolved 解决方法
Error: The import javax.servlet cannot be resolved The import javax.servlet.http.HttpServletRequest ...
- hdu 1057 A + B Again
A + B Again Problem Description There must be many A + B problems in our HDOJ , now a new one is com ...
- Linux学习 :多线程编程
1.Linux进程与线程() 进程:通过fork创建子进程与创建线程之间是有区别的:fork创建出该进程的一份拷贝,创建时额外申请了新的内存空间以及存储代码段.数据段.BSS段.堆.栈空间, ...
- SQL-19 查找所有员工的last_name和first_name以及对应的dept_name,也包括暂时没有分配部门的员工
题目描述 查找所有员工的last_name和first_name以及对应的dept_name,也包括暂时没有分配部门的员工CREATE TABLE `departments` (`dept_no` c ...
- jQuery $.each()常见的几种使用方法
<code class="language-html"><!doctype html> <html> <head> <meta ...
- table 奇行偶行
jquery 方法: $("tr:odd").//偶行 $("tr:even") //奇行