RNN-LSTM-GRU-BIRNN
https://blog.csdn.net/wangyangzhizhou/article/details/76651116 共三篇
RNN的模型展开后多个时刻隐层互相连接,而所有循环神经网络都有一个重复的网络模块,RNN的重复网络模块很简单,如下下图,比如只有一个tanh层。

而LSTM的重复网络模块的结构则复杂很多,它实现了三个门计算,即遗忘门、输入门和输出门。每个门负责是事情不一样,遗忘门负责决定保留多少上一时刻的单元状态到当前时刻的单元状态;输入门负责决定保留多少当前时刻的输入到当前时刻的单元状态;输出门负责决定当前时刻的单元状态有多少输出。
每个LSTM包含了三个输入,即上时刻的单元状态、上时刻LSTM的输出和当前时刻输入。

https://blog.csdn.net/thriving_fcl/article/details/73381217
主要参考的论文是Hierarchical Attention Networks for Document Classification。这里的层次Attention网络并不是只含有Attention机制的网络,而是在双向RNN的输出后加了Attention机制,层次表现在对于较长文本的分类,先将词向量通过RNN+Attention表示为句子向量,再将句子向量通过RNN+Attention表示为文档向量。两部分的Attention机制是一样的,这篇博客就不重复说明了。
BIRNN

attention
1. 原来的Encoder–Decoder
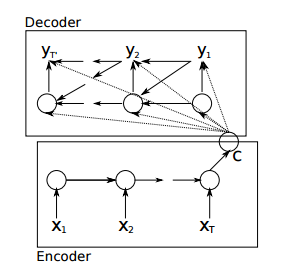
在这个模型中,encoder只将最后一个输出递给了decoder,这样一来,decoder就相当于对输入只知道梗概意思,而无法得到更多输入的细节,比如输入的位置信息。
2. 对齐问题
前面说了,只给我递来最后一个输出,不好;但如果把每个step的输出都传给我,又有一个问题了,怎么对齐?
什么是对齐?比如说英文翻译成中文,假设英文有10个词,对应的中文翻译只有6个词,那么就有了哪些英文词对哪些中文词的问题了嘛。
3. attention机制
https://www.cnblogs.com/shixiangwan/p/7573589.html
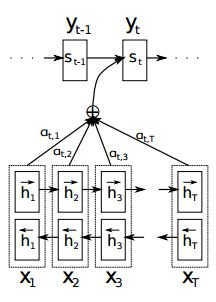
这个g可以用一个小型的神经网络来逼近,它用来计算St−1 、hj这两者的关系分数,如果分数大则说明关注度较高,注意力分布就会更加集中在这个输入单词上,这个函数在文章Neural Machine Translation by Jointly Learning to Align and Translate(2014)中称之为校准模型(alignment model),文中提到这个函数是RNN前馈网络中的一系列参数,在训练过程会训练这些参数。
把四个公式串起来看,这个attention机制可以总结为一句话:当前一步输出St应该对齐哪一步输入,主要取决于前一步输出St−1和这一步输入的encoder结果hj。
(该结论有时表述为只与encoder结果有关)
RNN-LSTM-GRU-BIRNN的更多相关文章
- RNN,LSTM,GRU基本原理的个人理解
记录一下对RNN,LSTM,GRU基本原理(正向过程以及简单的反向过程)的个人理解 RNN Recurrent Neural Networks,循环神经网络 (注意区别于recursive neura ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- RNN/LSTM/GRU/seq2seq公式推导
概括:RNN 适用于处理序列数据用于预测,但却受到短时记忆的制约.LSTM 和 GRU 采用门结构来克服短时记忆的影响.门结构可以调节流经序列链的信息流.LSTM 和 GRU 被广泛地应用到语音识别. ...
- RNN - LSTM - GRU
循环神经网络 (Recurrent Neural Network,RNN) 是一类具有短期记忆能力的神经网络,因而常用于序列建模.本篇先总结 RNN 的基本概念,以及其训练中时常遇到梯度爆炸和梯度消失 ...
- RNN & LSTM & GRU 的原理与区别
RNN 循环神经网络,是非线性动态系统,将序列映射到序列,主要参数有五个:[Whv,Whh,Woh,bh,bo,h0][Whv,Whh,Woh,bh,bo,h0],典型的结构图如下: 和普通神经网 ...
- [PyTorch] rnn,lstm,gru中输入输出维度
本文中的RNN泛指LSTM,GRU等等 CNN中和RNN中batchSize的默认位置是不同的. CNN中:batchsize的位置是position 0. RNN中:batchsize的位置是pos ...
- RNN, LSTM, GRU cells
项目需要,先简记cell,有时间再写具体改进原因 RNN cell LSTM cell: GRU cell: reference: 1.https://towardsdatascience.com/a ...
- RNN,GRU,LSTM
2019-08-29 17:17:15 问题描述:比较RNN,GRU,LSTM. 问题求解: 循环神经网络 RNN 传统的RNN是维护了一个隐变量 ht 用来保存序列信息,ht 基于 xt 和 ht- ...
- 自己动手实现深度学习框架-7 RNN层--GRU, LSTM
目标 这个阶段会给cute-dl添加循环层,使之能够支持RNN--循环神经网络. 具体目标包括: 添加激活函数sigmoid, tanh. 添加GRU(Gate Recurrent U ...
- NLP教程(5) - 语言模型、RNN、GRU与LSTM
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
随机推荐
- Java技巧之双括弧初始化
由于Java语言的集合框架中(collections, 如list, map, set等)没有提供任何简便的语法结构,这使得在建立常量集合时的工作非常繁索.每次建立时我们都要做: 定义一个临时的集合类 ...
- forget suffix word aby able ability out 1
1★ aby 2★ ability 3★ able 有`~ 能力 的,具有 这样的能力 的人或物
- memory prefix out omni,over,out,od,octa ~O
1● omni 全部 ,到处: 2● over 过度,超过,出去,翻转 3● out 超过,过去,过分, 在~之上, 4● od 逆,倒 :加强 的 意思 5● octa 八
- nyoj 0269 VF(dp)
nyoj 0269 VF 意思大致为从1-10^9数中找到位数和为s的个数 分析:利用动态规划思想,一位一位的考虑,和s的范围为1-81 状态定义:dp[i][j] = 当前所有i位数的和为j的个数 ...
- Win10系列:UWP界面布局基础1
随着技术的不断发展,使用者对应用程序的界面体验提出了更高的要求,为了应对越来越复杂的界面设计需求和有效的简化界面开发过程,微软公司在其应用程序的开发技术当中引入一套新的应用程序界面描述语言,这就是XA ...
- 读书笔记 enum枚举之位标志属性(Flags)浅析
针对enum枚举来说,可以定义位标志属性,从而使该枚举类型的实例可以存储枚举列表中定义值的任意组合.可以用 与(&).或(|).异或(^)进行相应的运算.废话不多说,代码最直接. //每一个定 ...
- DRF的分页
DRF的分页 DRF的分页 为什么要使用分页 其实这个不说大家都知道,大家写项目的时候也是一定会用的, 我们数据库有几千万条数据,这些数据需要展示,我们不可能直接从数据库把数据全部读取出来, 这样 ...
- 进程中的Manager(),实现多进程的数据共享与传递
__author__ = "Alex Li" from multiprocessing import Process, Managerimport osdef f(d, l): d ...
- vue-cli快速构建vue项目模板
vue-cli 是vue.js的脚手架,用于自动生成vue.js模板工程的. 1.使用npm安装vue-cli 需要先装好vue 和 webpack(前提是已经安装了nodejs,否则连npm都用不了 ...
- <Codis><JedisPool><DeadLock>
Overview Background: I start a thread [call thread A below]in Spark driver to handle opening files i ...