Hive SQL grouping sets 用法
概述
GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
这几个分析函数通常用于OLAP中,不能累加,而且需要根据不同维度上钻和下钻的指标统计,比如,分小时、天、月的UV数。
GROUPING SETS和GROUPING__ID
说明
在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL
GROUPING__ID,表示结果属于哪一个分组集合。
查询语句:
select
month,
day,
count(distinct cookieid) as uv,
GROUPING__ID
from cookie.cookie5
group by month,day
grouping sets (month,day)
order by GROUPING__ID;
等价于:
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day
查询结果
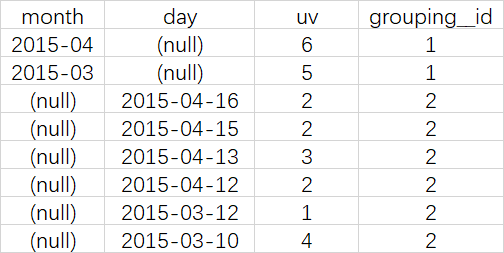
结果说明
第一列是按照month进行分组
第二列是按照day进行分组
第三列是按照month或day分组是,统计这一组有几个不同的cookieid
第四列grouping_id表示这一组结果属于哪个分组集合,根据grouping sets中的分组条件month,day,1是代表month,2是代表day
再比如:
SELECT month, day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM cookie5
GROUP BY month,day
GROUPING SETS (month,day,(month,day))
ORDER BY GROUPING__ID;
等价于:
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM cookie5 GROUP BY month,day

CUBE
说明
根据GROUP BY的维度的所有组合进行聚合
查询语句
SELECT month, day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM cookie5
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
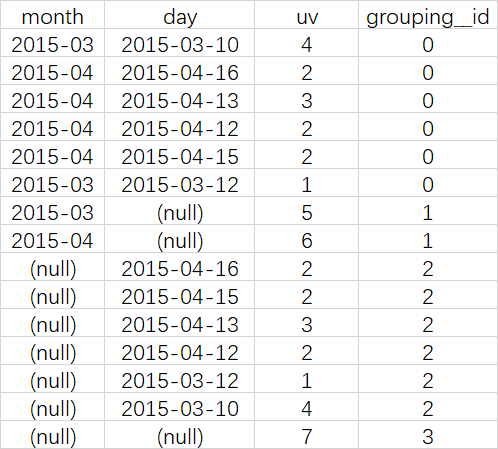
等价于
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__ID FROM cookie5
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM cookie5 GROUP BY month,day
查询结果
ROLLUP
说明
是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合
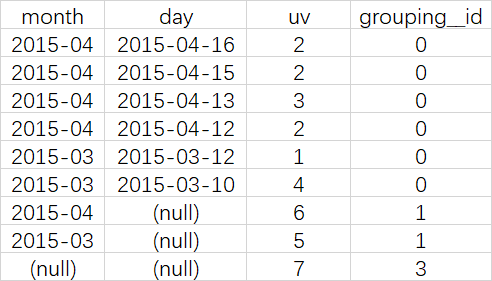
查询语句
-- 比如,以month维度进行层级聚合
SELECT month, day, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID
FROM cookie5
GROUP BY month,day WITH ROLLUP ORDER BY GROUPING__ID;
可以实现这样的上钻过程:
月天的UV->月的UV->总UV
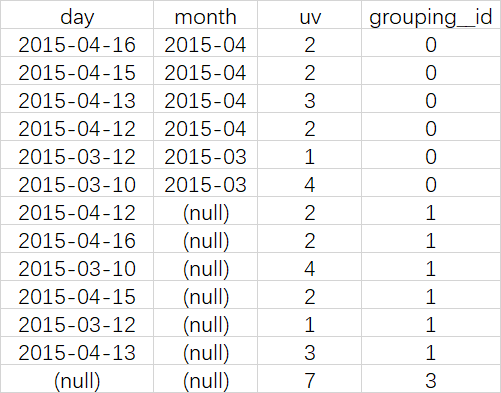
--把month和day调换顺序,则以day维度进行层级聚合:
可以实现这样的上钻过程:
天月的UV->天的UV->总UV
(这里,根据天和月进行聚合,和根据天聚合结果一样,因为有父子关系,如果是其他维度组合的话,就会不一样)
https://www.cnblogs.com/qingyunzong/p/8798987.html
感谢博主!
Hive SQL grouping sets 用法的更多相关文章
- hive中grouping sets的使用
hive中grouping sets 数量较多时如何处理? 可以使用如下设置来 set hive.new.job.grouping.set.cardinality = 30; 这条设置的意义在于 ...
- Hive高级聚合GROUPING SETS,ROLLUP以及CUBE
scala> import org.apache.spark.sql.hive.HiveContextimport org.apache.spark.sql.hive.HiveContext s ...
- SQL Server 之 GROUP BY、GROUPING SETS、ROLLUP、CUBE
1.创建表 Staff CREATE TABLE [dbo].[Staff]( ,) NOT NULL, ) NULL, ) NULL, ) NULL, [Money] [int] NULL, [Cr ...
- SQL Server里Grouping Sets的威力
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务).我不是说在生产里使用开发版,也不是说安装盗版SQL Server. 不可能的任务 ...
- SQL Server2008 程序设计 汇总 GROUP BY,WITH ROLLUP,WITH CUBE,GROUPING SETS(..)
--SQL Server2008 程序设计 汇总 GROUP BY ,WITH ROLLUP WITH CUBE GROUPING SET(..) /*********************** ...
- hive grouping sets 实现原理
先下结论: 看了hive 1.1.0 grouping sets 实现(从源码及执行计划都可以看出与kylin实现不一样),(前提是可累加,如sum函数)他并没有像kylin一样先按照group by ...
- SQL Server里Grouping Sets的威力【转】
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务).我不是说在生产里使用开发版,也不是说安装盗版SQL Server. 不可能的任务 ...
- Hive高阶聚合函数 GROUPING SETS、Cube、Rollup
-- GROUPING SETS作为GROUP BY的子句,允许开发人员在GROUP BY语句后面指定多个统计选项,可以简单理解为多条group by语句通过union all把查询结果聚合起来结合起 ...
- SQL Server ->> GROUPING SETS, CUBE, ROLLUP, GROUPING, GROUPING_ID
在我们制作报表的时候常常需要分组聚合.多组聚合和总合.如果通过另外的T-SQL语句来聚合难免性能太差.如果通过报表工具的聚合功能虽说比使用额外的T-SQL语句性能上要好很多,不过不够干脆,还是需要先生 ...
随机推荐
- Codeforces 594A - Warrior and Archer
题目大意:给你在一条线上的n(偶数)个点,mike和alice 开始禁点,他们轮流开始,直到最后只剩下两个点, mike希望剩下的两个点距离尽可能小,alice希望剩下的两个点距离尽可能大,他们都采用 ...
- HDU3031 To Be Or Not To Be 左偏树 可并堆
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - HDU3031 题意概括 喜羊羊和灰太狼要比赛. 有R次比赛. 对于每次比赛,首先输入n,m,n表示喜羊羊和灰 ...
- C#连接数据库MD5数据库加密
创建StringHelper类 首先数据库里的资料是加密了的. 创建将指定的字符串加密为MD5密文方法 public static string ToMD5(string source){ Strin ...
- ARIMA模型---时间序列分析---温度预测
(图片来自百度) 数据 分析数据第一步还是套路------画图 数据看上去比较平整,但是由于数据太对看不出具体情况,于是将只取前300个数据再此画图 这数据看上去很不错,感觉有隐藏周期的意思 代码 # ...
- Spring框架学习08——自动代理方式实现AOP
在传统的基于代理类的AOP实现中,每个代理都是通过ProxyFactoryBean织入切面代理,在实际开发中,非常多的Bean每个都配置ProxyFactoryBean开发维护量巨大.解决方案:自动创 ...
- Orleans逐步教程
参考文档:https://dotnet.github.io/orleans/Tutorials/index.html 一.通过模板创建Orleans ①下载vs插件:https://marketpla ...
- loj#2129. 「NOI2015」程序自动分析
题目链接 loj#2129. 「NOI2015」程序自动分析 题解 额... 考你会不会离散化优化常数 代码 #include<queue> #include<cstdio> ...
- Java API概述
collection of APIs(Application Programming Interface) java.lang — automatically imported into Java p ...
- oracle 变量
插入 日期时间 循环插入 declare total date:) ; begin .. LOOP insert into DQ_DATE(date_time) values ( total ); t ...
- 在windows下安装git中文版客户端并连接gitlab
下载git Windows客户端 git客户端下载地址:https://git-scm.com/downloads 我这里下载的是Git-2.14.0-64-bit.exe版本 下载TortoiseG ...