【深入浅出 Yarn 架构与实现】3-1 Yarn Application 流程与编写方法
本篇学习 Yarn Application 编写方法,将带你更清楚的了解一个任务是如何提交到 Yarn ,在运行中的交互和任务停止的过程。通过了解整个任务的运行流程,帮你更好的理解 Yarn 运作方式,出现问题时能更好的定位。
一、简介
本篇将对 Yarn Application 编写流程进行介绍。将一个新的应用程序运行到 Yarn 上,主要编写两个组件 Client 和 ApplicationMaster,组件的具体实现案例将在后两篇文章中介绍。
(实际使用中,我们并不需要实现一个 Yarn Application,直接将任务提交到 MapReduce、Spark、Hive、Flink 等框架上,再由这些框架提交任务即可,这些框架也可以被视为一种特定的 Yarn Application。)
其中,Client 主要用于提交应用程序和管理应用程序,ApplicationMaster 负责实现应用程序的任务切分、调度、监控等功能。
一)Application 的提交和启动流程
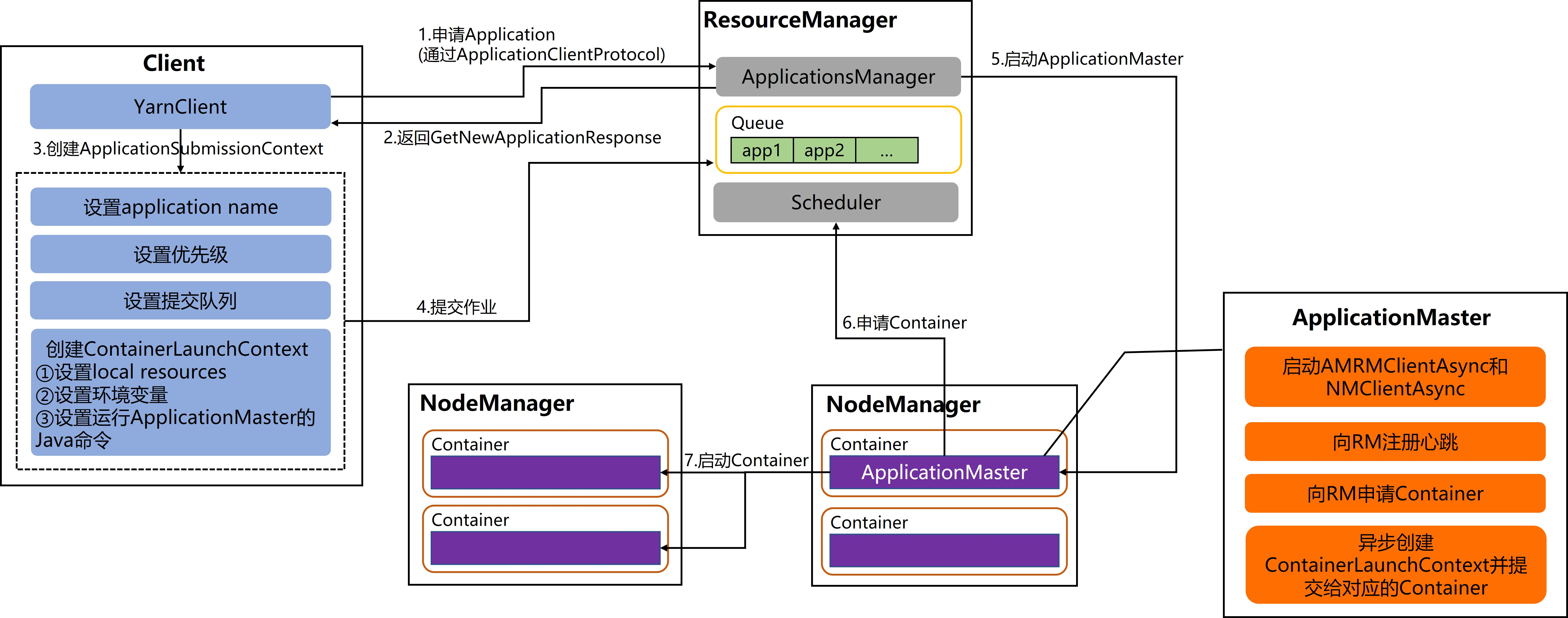
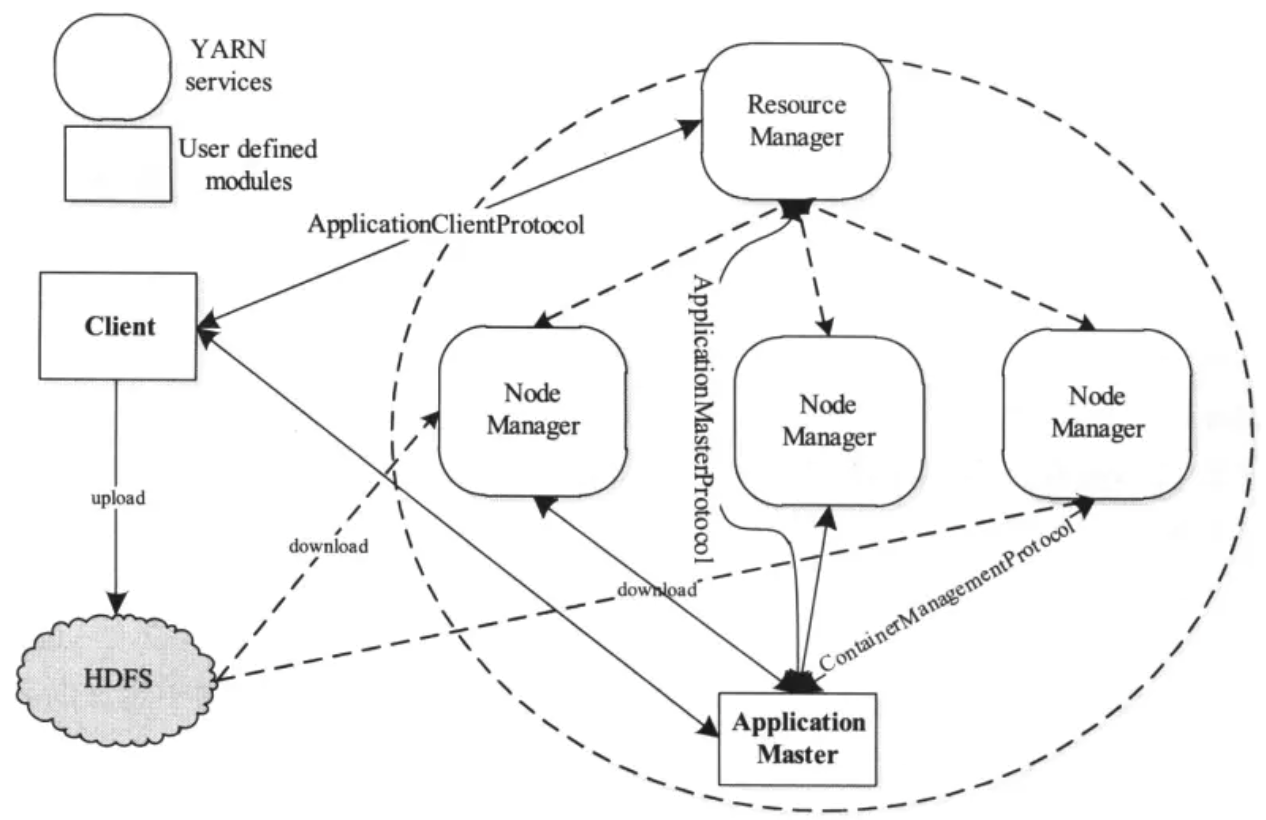
二)各服务间涉及的 protocol
二、组件实现流程
一)Client 实现
- 创建并启动
YarnClient; - 通过
YarnClient创建Application; - 完善
ApplicationSubmissionContext所需内容:- 设置 application name;
- 设置 ContainerLaunchContext;(包含 app master jar)
- 设置优先级、队列等
- 提交
Application。
二)ApplicationMaster实现
- 创建并启动
AMRMClientAsync,用于与ResourceManager通信; - 创建并启动
NMClientAsync,用于与NodeManager通信; - 向
ResourceManager注册,之后会向ResourceManager发送心跳; - 向
ResourceManager申请Container。 - 在
Container中运行 task
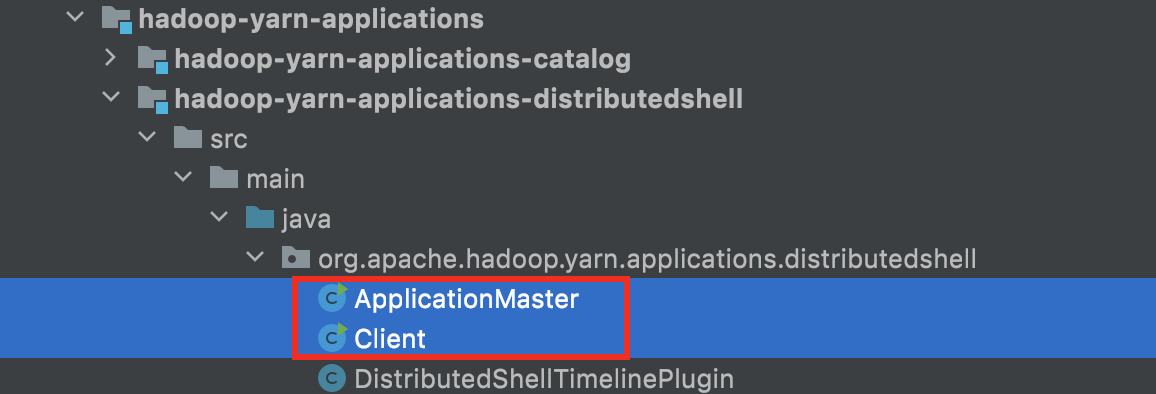
三)Hadoop 实现案例
Hadoop 自带的 hadoop-yarn-applications-distributedshell 是个很好的学习案例,可以参考其中的 Client.java 和 ApplicationMaster.java 两个类进行学习。DistributedShell 可以执行用户指定的 Shell 命令或脚本,包含了编写一个 YARN Application 的完整内容。
三、小结
本篇带大家了解了 Yarn Application 提交和启动流程、组件间涉及的通信协议,以及编写 Application 的基本流程。实际上,在 Yarn 上运行不同的框架应用 Hive、Spark、Flink 等就是主要实现 Client 和 Application Master 两个组件。理解了本文的相关知识,再去看其他应用提交过程就会清晰很多。
接下来的两篇讲带大家学习 Client 和 Application Master 具体编写方式。
参考文章:
深入解析yarn架构设计与技术实现-yarn 应用程序设计方法
Hadoop YARN原理 - 编写YARN Application
Hadoop DOC: Writing YARN Applications
github app-on-yarn-demo
《Hadoop 技术内幕 - 深入解析 Yarn 结构设计与实现原理》第四章
【深入浅出 Yarn 架构与实现】3-1 Yarn Application 流程与编写方法的更多相关文章
- 【深入浅出 Yarn 架构与实现】2-1 Yarn 基础库概述
了解 Yarn 基础库是后面阅读 Yarn 源码的基础,本节对 Yarn 基础库做总体的介绍.并对其中使用的第三方库 Protocol Buffers 和 Avro 是什么.怎么用做简要的介绍. 一. ...
- 【深入浅出 Yarn 架构与实现】2-2 Yarn 基础库 - 底层通信库 RPC
RPC(Remote Procedure Call) 是 Hadoop 服务通信的关键库,支撑上层分布式环境下复杂的进程间(Inter-Process Communication, IPC)通信逻辑, ...
- 【深入浅出 Yarn 架构与实现】2-3 Yarn 基础库 - 服务库与事件库
一个庞大的分布式系统,各个组件间是如何协调工作的?组件是如何解耦的?线程运行如何更高效,减少阻塞带来的低效问题?本节将对 Yarn 的服务库和事件库进行介绍,看看 Yarn 是如何解决这些问题的. 一 ...
- 【深入浅出 Yarn 架构与实现】2-4 Yarn 基础库 - 状态机库
当一个服务拥有太多处理逻辑时,会导致代码结构异常的混乱,很难分辨一段逻辑是在哪个阶段发挥作用的. 这时就可以引入状态机模型,帮助代码结构变得清晰. 一.状态机库概述 一)简介 状态机由一组状态组成: ...
- 【深入浅出 Yarn 架构与实现】1-1 设计理念与基本架构
一.Yarn 产生的背景 Hadoop2 之前是由 HDFS 和 MR 组成的,HDFS 负责存储,MR 负责计算. 一)MRv1 的问题 耦合度高:MR 中的 jobTracker 同时负责资源管理 ...
- 【深入浅出 Yarn 架构与实现】1-2 搭建 Hadoop 源码阅读环境
本文将介绍如何使用 idea 搭建 Hadoop 源码阅读环境.(默认已安装好 Java.Maven 环境) 一.搭建源码阅读环境 一)idea 导入 hadoop 工程 从 github 上拉取代码 ...
- Spark on Yarn 架构解析
. 一.Hadoop Yarn组件介绍: 我们都知道yarn重构根本的思想,是将原有的JobTracker的两个主要功能资源管理器 和 任务调度监控 分离成单独的组件.新的架构使用全局管理所有应用程序 ...
- Yarn集群的搭建、Yarn的架构和WordCount程序在集群提交方式
一.Yarn集群概述及搭建 1.Mapreduce程序运行在多台机器的集群上,而且在运行是要使用很多maptask和reducertask,这个过程中需要一个自动化任务调度平台来调度任务,分配资源,这 ...
- Yarn架构详解
Yarn架构介绍Yarn/MRv2最基本的想法是将原JobTracker主要的资源管理和job调度/监视功能分开作为两个单独的守护进程.有一个全局的ResourceManager(RM)和每个Appl ...
随机推荐
- DataGridView控件绑定数据之后,置顶操作
一个小小的置顶,就搞了半个小时,还是记录一下吧. 1.第一个问题就是datatable的插入只能是Insert DataRow,但是获取选中的行,都是DataGridViewRow,不能直接转换. 找 ...
- 给ShardingSphere提了个PR,不知道是不是嫌弃我
说来惭愧,干了 10 来年程序员,还没有给开源做过任何贡献,以前只知道嘎嘎写,出了问题嘎嘎改,从来没想过提个 PR 去修复他,最近碰到个问题,发现挺简单的,就随手提了个 PR 过去. 问题 问题挺简单 ...
- Zookeeper及基于Zookeeper的分布式锁总结
1. Zookeeper ZooKeeper 内部存储的数据结构 / +-- node1 +-- node2 | +-- sub_node21 -> "I am sub_node21& ...
- 果汁 DI 介绍
Guice (英音同 'juice[果汁]') 是一个为 JDK8 及以上提供的轻量依赖注入框架. 目录 三级标题 三级标题 四级标题 三级标题 三级标题 /** * Animal */ interf ...
- Python中的super函数,你熟吗?
摘要:经常有朋友问,学 Python 面向对象时,翻阅别人代码,会发现一个 super() 函数,那这个函数的作用到底是什么? 本文分享自华为云社区<Python中的super函数怎么学,怎么解 ...
- 2021年3月-第02阶段-前端基础-Flex 伸缩布局-移动WEB开发_流式布局
移动web开发流式布局 1.0 移动端基础 1.1 浏览器现状 PC端常见浏览器:360浏览器.谷歌浏览器.火狐浏览器.QQ浏览器.百度浏览器.搜狗浏览器.IE浏览器. 移动端常见浏览器:UC浏览器, ...
- Kafka开启SASL认证 【windowe详细版】
一.JAAS配置 Zookeeper配置JAAS zookeeper环境下新增一个配置文件,如zk_server_jass.conf,内容如下: Server { org.apache.kafka.c ...
- CPU密集型和IO密集型(判断最大核心线程的最大线程数)
CPU密集型和IO密集型(判断最大核心线程的最大线程数) CPU密集型 1.CPU密集型获取电脑CPU的最大核数,几核,最大线程数就是几Runtime.getRuntime().availablePr ...
- ProxySQL(9):ProxySQL的查询缓存功能
文章转载自: https://www.cnblogs.com/f-ck-need-u/p/9314459.html ProxySQL支持查询缓存的功能,可以将后端返回的结果集缓存在自己的内存中,在某查 ...
- Python Client API文档
官网文档地址:http://docs.minio.org.cn/docs/master/python-client-api-reference 初使化MinIO Client对象 from minio ...