Spark详解(04) - Spark项目开发环境搭建
类别 [随笔分类]Spark
Spark详解(04) - Spark项目开发环境搭建
Spark Shell仅在测试和验证程序时使用的较多,在生产环境中,通常会在IDEA中编制程序,然后打成Jar包,提交到集群,最常用的是创建一个Maven项目,利用Maven来管理Jar包的依赖。
新建项目
在idea中file — new project,选择Maven
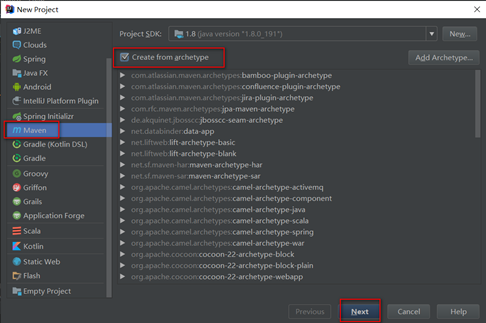
填写gid和aid
下一步点击next
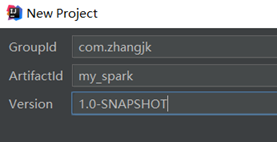
选择项目名以及项目源码储存路径,点击Finish
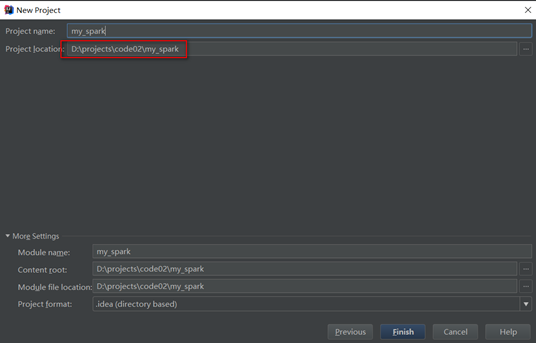
创建完成后会自动打开pom.xml页面
配置环境
配置Maven
选择本地maven路径:file – settings

添加scala的lib和SDK:file – project structure
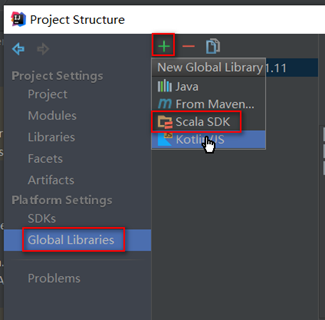


添加成功后在External Libraries下显示scala-sdk
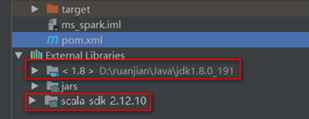
使用maven添加依赖包
本地添加方式和maven方式二者选一即可
在pom中添加spark依赖
- <dependencies>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.12</artifactId>
- <version>3.0.0</version>
- </dependency>
- </dependencies>
Pom中添加打包插件
- <build>
- <finalName>WordCount</finalName>
- <plugins>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-assembly-plugin</artifactId>
- <version>3.0.0</version>
- <configuration>
- <archive>
- <manifest>
- <mainClass>com.zhangjk.WordCount</mainClass>
- </manifest>
- </archive>
- <descriptorRefs>
- <descriptorRef>jar-with-dependencies</descriptorRef>
- </descriptorRefs>
- </configuration>
- <executions>
- <execution>
- <id>make-assembly</id>
- <phase>package</phase>
- <goals>
- <goal>single</goal>
- </goals>
- </execution>
- </executions>
- </plugin>
- </plugins>
- </build>
离线添加本地spark的依赖jar包:file – project structure
本地添加方式和maven方式二者选一即可
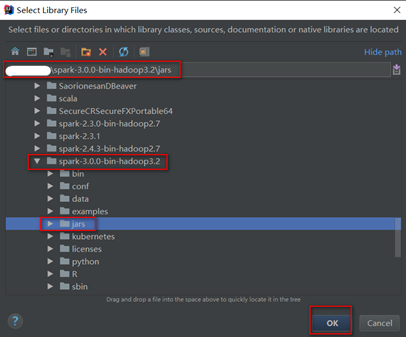
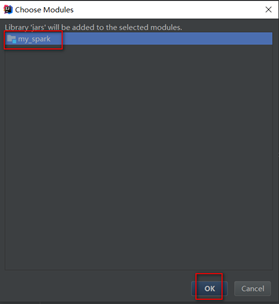
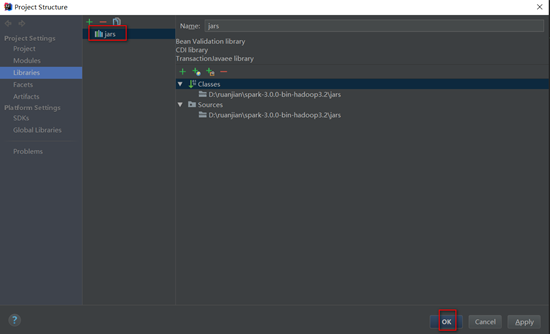
这里添加spark jar包是为了方便本地开发环境运行saprk任务方便调试,可以从本地安装的spark环境中选择,也可以使用maven添加,选择本地文件更方便管理,因为在提交spark任务到yarn集群时由于yarn集群中已经有spark相关依赖,所以在项目打包时需要将spark依赖去掉(不去掉spark任务会运行失败),同时spark之外的其他依赖打包时又不能去掉。本地spark jar包添加完成后会在External Libraries下显示。
除了spark依赖的jar,项目需要的其他依赖可以在pom中添加其他依赖通过maven管理
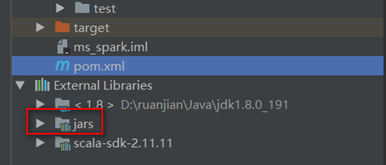
- 添加其他依赖包
Spark项目中除了spark相关依赖包外的其他依赖包还是需要在打包时放到jar包中的,
在pom.xml中添加相关依赖
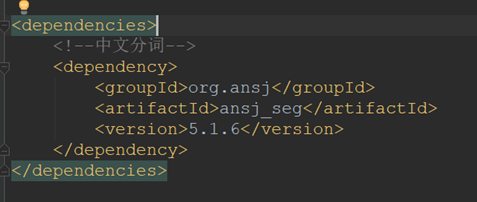
file – project structure
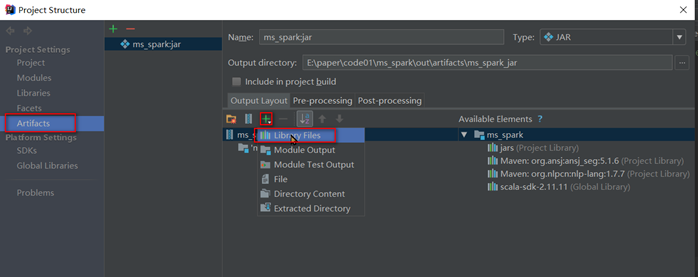
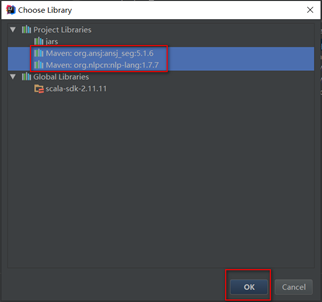
从这里可以看到,spark相关依赖包都在jars目录中,而maven管理的jar包都直接显示出来,所以spark的相关依赖可以选择不使用maven管理

重新bulid项目即可
如果jar包在yarn平台中运行时报 java.lang.ClassNotFoundException: org.ansj.recognition.impl.StopRecognition
意思是程序找不到maven引入的依赖,使用压缩软件打开jar包如下
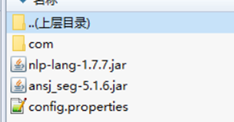
发现只有自己编写的代码是以文件加在jar包中,而引入的jar包则是以jar文件的方式在压缩包中
解决方法如下
使用压缩软件将jar包解压
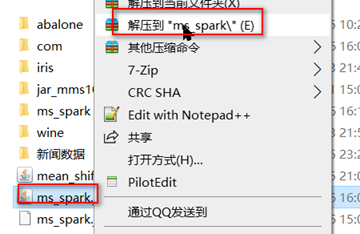
然后将不是依赖包的目录文件删除

然后将所有依赖的jar包再次解压到当前文件夹
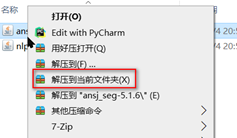
最有将解压后的依赖jar包在压缩到原有的jar包文件中
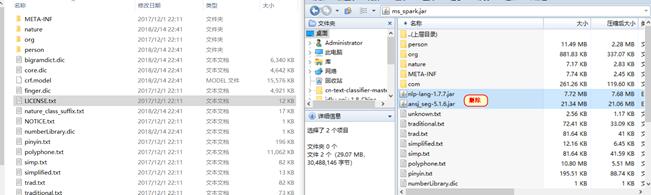
这样在重新提交任务就不会出现找不到类的错误了
这是一种解决方案,ieda在打包时应该可以设置依赖包的打包方式,若有知道的请告知
创建scala源码包
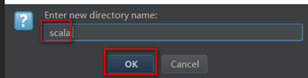
Main目录下创建scala目录:在main目录上右键单击

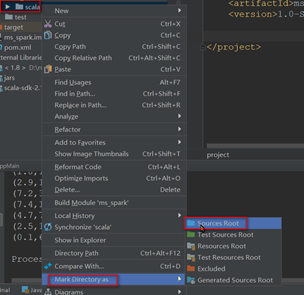
将创建的scala目录转成根目录,在上一步创建的scala目录右键单击
编写wordcount测试程序
在scala目录下新建包名:com.zhangjk
创建伴生对象(Object)WordCount
编写代码
- package com.zhangjk
- import org.apache.spark.rdd.RDD
- import org.apache.spark.{SparkConf, SparkContext}
- object WordCount {
- def main(args: Array[String]): Unit = {
- val conf: SparkConf = new SparkConf()
- //TODO 设置线程数,在本地idea中运行需要设置此参数,打成jar包在yarn集群中运行需要注释该参数设置,
- .setMaster("local[*]")
- .setAppName("WC")
- val sc = new SparkContext(conf)
- sc.setLogLevel("WARN")
- val data = Array("hello scala", "hello word", "hello java", "hello python", "word count")
- val inputRDD = sc.parallelize(data)
- val resultRDD: RDD[(String, Int)] = inputRDD.filter(line => null != line && line.trim.length > 0)
- .flatMap(_.split(" "))
- .mapPartitions(iter => iter.map(_ -> 1))
- .reduceByKey(_ + _)
- resultRDD.coalesce(1)
- .foreachPartition(
- iter=>iter.foreach(println)
- )
- sc.stop()
- }
- }
本地运行调试spark代码
- 检查Spark版本和scala版本是否一致
使用IDEA工具运行运行spark项目时必须保证spark依赖的scala版本和本地安装的版本保持一致,如果不一致会报如下错误
Exception in thread "main" java.lang.NoSuchMethodError: scala.Product.$init$(Lscala/Product;)V

如果确定spark版本和scala版本是否一致
在cmd中运行spark-shell,可以看到spark-3.0.0版本使用的scala版本是2.12.10
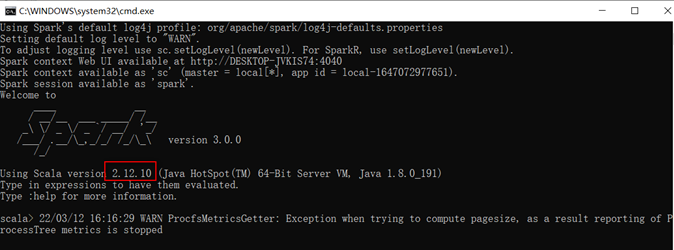
在另一个cmd中输入scala命令可以看到当前使用的scala运行环境是2.12.10,和spark要求的一致,如果不一致,则需要下载对应版本的scala环境安装包重新安装
- 本地运行调试
本地Spark程序调试需要使用Local提交模式,即将本机当做运行环境,Master和Worker都为本机。运行时直接加断点调试即可
本地调试流程
打包并提交到yarn平台运行
打包
- 使用artifacts打包
新建build

选择运行的主类
无论是否指定都需要在提交spark任务时使用--class com.taiji. WordCount参数设置jar包运行的主类
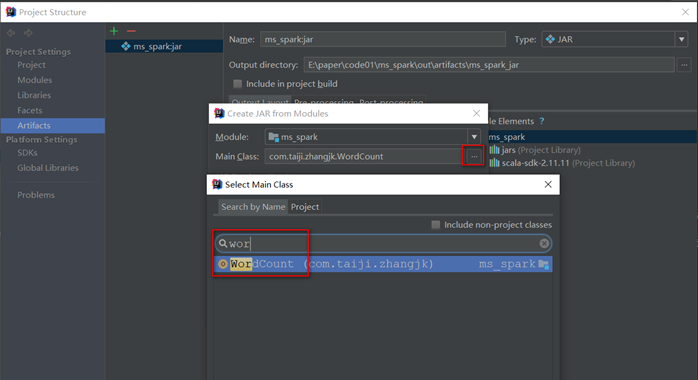
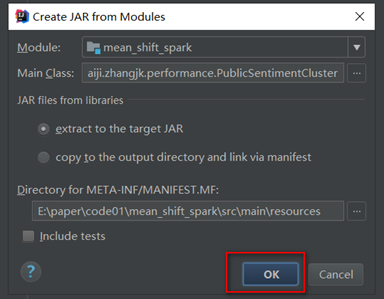
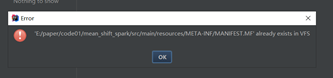
若出现下面的错误,删除MANIFEST.MF
由于spark程序部分依赖包服务器上已有,需要手工将spark的相关依赖jar包删除。
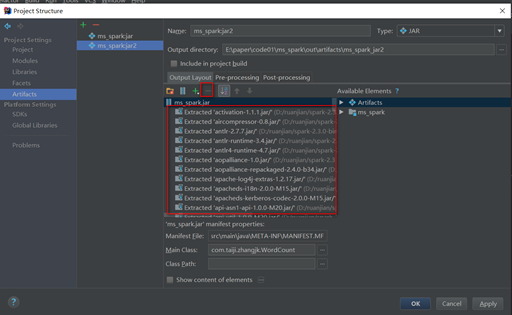
如果是新建项目,并且按照上面的方式添加的spark依赖,把所有的都删除,只保留最后一个,然后再按照项目需要再pom中添加其他依赖

保存配置
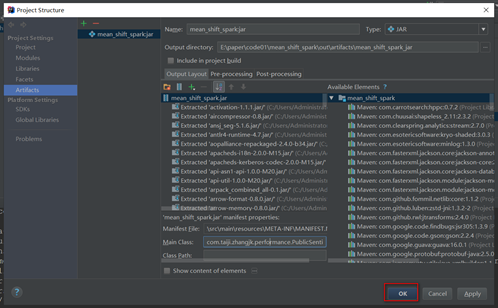
编译打包

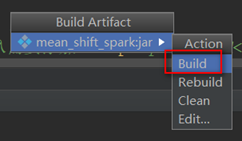
最终生产的jar包

- 使用maven打包
在maven控制台点击package打包,
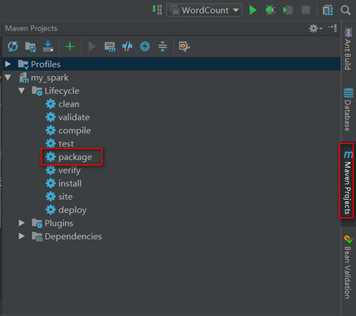
然后,查看打完后的jar包

其中:
WordCount.jar是不带依赖的jar包,在提交任务时,由于服务器上已经安装了spark的相关依赖,一般会使用该jar包
WordCount-jar-with-dependencies.jar是带所有依赖的jar包
如果spark程序中引入的依赖除了spark-core之外还有其他依赖,例如zkclient、kafka-clients等,此时对于不带依赖的jar包,服务器上也没有对于的jar包,而带依赖的jar包服务器上又包含了spark依赖的所有jar包,此时在提交任务是无论提交那个jar包都不能正常运行,这是可以使用<scope>provided</scope>将spark依赖的jar包在打包时忽略,这样在WordCount-jar-with-dependencies.jar的jar包中即不包含saprk依赖又还有其他依赖
提交任务
使用spark-submit提交任务,需要注意用户权限,如果是cdh安装的yarn平台,需要切换到spark或hdfs用户执行submit命令 同时存放jar包的目录尽量具有777的权限
如果使用spark 有时候需要访问hdfs文件系统,spark用户也会受到权限限制,这时可以切换到hdfs用户试试
在命令前面添加nohup是后台方式执行,不加即为前台方式启动,连接终端断开任务即停止运行
- 提交spark任务到yarn平台
把jar包上传到服务器/opt/module/spark-yarn目录
执行submit命令
[hadoop@hadoop102 spark-yarn]$ bin/spark-submit --class com.zhangjk.WordCount --master yarn ./WordCount.jar
- spark-submit 详细参数说明
--master master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local
--deploy-mode 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client
--class 应用程序的主类,仅针对 java 或 scala 应用
--name 应用程序的名称
--jars 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下
--packages 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标
--exclude-packages 为了避免冲突
而指定不包含的 package
--repositories 远程 repository
--conf PROP=VALUE 指定 spark 配置属性的值,例如 -conf spark.executor.extraJavaOptions="-XX:MaxPermSize=256m"
--properties-ile 加载的配置文件,默认为 conf/spark-defaults.conf
--driver-memory Driver内存,默认 1G
--driver-java-options 传给 driver 的额外的 Java 选项
--driver-library-path 传给 driver 的额外的库路径
--driver-class-path 传给 driver 的额外的类路径
--driver-cores Driver 的核数,默认是1。在 yarn 或者 standalone 下使用
--executor-memory 每个 executor 的内存,默认是1G
--total-executor-cores 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用
--num-executors 启动的 executor 数量。默认为2。在 yarn 下使用
--executor-core 每个 executor 的核数。在yarn或者standalone下使用
其他常用
关联源码
按住ctrl键,点击RDD

提示下载或者绑定源码

解压资料包中spark-3.0.0.tgz到非中文路径。
点击Attach Sources…按钮,选择源码路径
创建IDEA快捷键
1)点击File->Settings…->Editor->Live Templates->output->Live Template
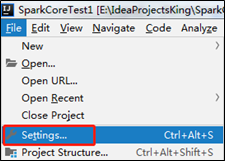
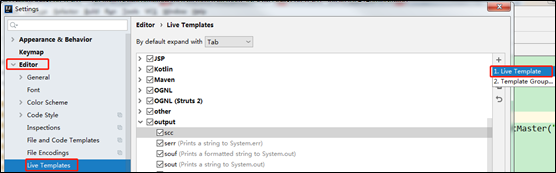
2)点击左下角的Define->选择Scala

3)在Abbreviation中输入快捷键名称scc,在Template text中填写,输入快捷键后生成的内容。
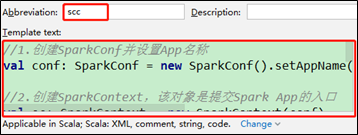
//1.创建SparkConf并设置App名称
val conf: SparkConf =
new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext =
new SparkContext(conf)
//4.关闭连接
sc.stop()
异常处理
idea打jar包缺少class文件(classes目录为空)
将打好的jar包上传到服务器上提交任务时发现报Error: Failed to load class错误,日志如下:
2022-03-13 02:29:38,620 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Error: Failed to load class com.zhangjk.WordCount.
2022-03-13 02:29:38,763 INFO util.ShutdownHookManager: Shutdown hook called
2022-03-13 02:29:38,764 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-35dd8e48-28ec-4ca7-a8ee-45b3eeb0f49e
通过压缩软件打开jar包,发现根本找不到classes目录及class文件
在IDEA中发现打包结果的classes目录也为空:
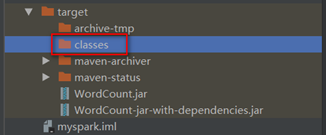
解决方案
现在idea中运行一次项目

运行成功后。
此时target目录下的classes目录出现了对应的class文件:
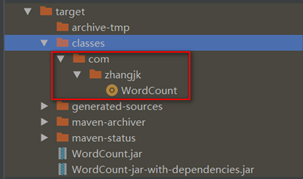
再次点击maven的package命令打包,将打好的jar包再次使用压缩软件打开,可以看到对于的class文件出现了
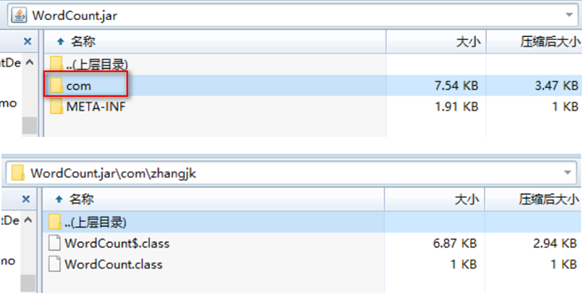
出现这种情况是因为某些原因导致package命令打包不能自动编译。在idea中运行项目会先编译,然后在打包就能把编译后的文件打到jar包中了
缺少Hadoop
如果本机操作系统是Windows,如果在程序中使用了Hadoop相关的东西,比如写入文件到HDFS,则会遇到如下异常:

出现这个问题的原因,并不是程序的错误,而是用到了Hadoop相关的服务,解决办法
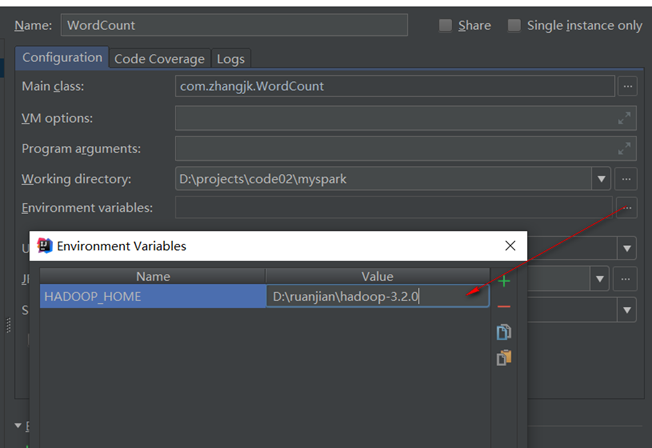
1)配置HADOOP_HOME环境变量
2)在IDEA中配置Run Configuration,添加HADOOP_HOME变量

Spark详解(04) - Spark项目开发环境搭建的更多相关文章
- Hadoop项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Mav ...
- Hive项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Mav ...
- unbuntu16.04上python开发环境搭建建议
unbuntu16.04上python开发环境搭建建议 2017-12-20 10:39:27 推荐列表: pycharm: 可以自行破解,但是不推荐,另外也不稳定 pydev+eclipse: ...
- iOS项目——项目开发环境搭建
在开发项目之前,我们需要做一些准备工作,了解iOS扩展--Objective-C开发编程规范是进行开发的必备基础,学习iOS学习--Xcode9上传项目到GitHub是我们进行版本控制和代码管理的选择 ...
- ubuntu16.04 Golang语言开发环境搭建
golang即go语言是跨平台的语言,适用于windows 和linux平台,下面介绍linux平台下ubuntu16.04系统下的开发环境搭建过程. 一.安装开发必备环境 执行下面命令分别安装git ...
- Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) 我这里,相信,能看此博客的朋友,想必是有一定基础的了.我前期写了大量的基础性博文. ...
- 详解php多人开发环境原理
作为一名php开发人员,有时候一个项目或一个功能我们不能独自完成,就像当一个仓库开发人员大于1,20人的时候,每个人可能开发不同的模块和功能,用代码版本控制工具比如 git 开不同的分支,流程大概是先 ...
- 详解 Webpack+Babel+React 开发环境的搭建
1.认识Webpack 构建应用前我们先来了解一下Webpack, Webpack是一个模块打包工具,能够把各种文件(例如:ReactJS.Babel.Coffeescript.Less/Sass等) ...
- 利用maven开发springMVC项目——开发环境搭建(版本错误解决)
申明:部分内容参见别人的博客,没有任何的商业用途,只是作为自己学习使用.(大佬博客) 一.相关环境 - eclipse :eclipse-jee-oxygen-3-win32-x86_64(下载地址) ...
- Ubuntu 16.04 以太坊开发环境搭建
今天我们来一步一步从搭建以太坊智能合约开发环境. Ubuntu16.04 安装ubuntu16.04.下载链接 //先update一下(或者换国内源再update) sudo apt-get upda ...
随机推荐
- 编程架构演化史:远古时代,从打孔卡(Punched Card)开始
回想读书时记录到书本里的打孔纸带编程,到初学编程接触到的C语言高级编程,再到C++.Java面向对象语言产生:从面向过程系统设计 到面向对象系统设计:从三层结构到MVC.MVP.MVVM:从主机到虚拟 ...
- 华为路由器RIP路由协议配置命令
RIP路由协议配置 rip 创建开启协议进程 network + ip 对指定网段接口使能RIP功能IP地址是与路由器直连的网段 debugging rip 1 查看RIP定期更新情况 termina ...
- Java斗地主(集合综合练习)
学完了集合后我们可以开始做一个简易版的 " 斗地主 " 了,但是呢咱们这个斗地主只能实现制造牌,洗牌.发牌.看牌这几个简单的功能,并不是我们玩的 " 真人版斗地主 & ...
- Doris开发手记4:倍速性能提升,向量化导入的性能调优实践
最近居家中,对自己之前做的一些工作进行总结.正好有Doris社区的小伙伴吐槽向量化的导入性能表现并不是很理想,就借这个机会对之前开发的向量化导入的工作进行了性能调优,取得了不错的优化效果.借用本篇手记 ...
- golang中的errgroup
0.1.索引 https://waterflow.link/articles/1665239900004 1.串行执行 假如我们需要查询一个课件列表,其中有课件的信息,还有课件创建者的信息,和课件的缩 ...
- golang中的选项模式
索引 https://waterflow.link/articles/1663835071801 当我在使用go-zero时,我看到了好多像下面这样的代码: ... type ( // RunOpti ...
- 三、redis环境安装
三.redis环境安装 3.1.下载和安装 下载地址:https://github.com/tporadowski/redis/releases 使用以下命令启动redis服务端 redis-se ...
- 图文详解丨iOS App上架全流程及审核避坑指南
App Store作为苹果官方的应用商店,审核严格周期长一直让用户头疼不已,很多app都"死"在了审核这一关,那我们就要放弃iOS用户了吗?当然不是!本期我们从iOS app上架流 ...
- JS 学习笔记(一)常用的字符串去重方法
要求:从输入框中输入一串字符,按回车后输出去重后的字符串 方法一: <body> <input type="text" id="input" ...
- 嵌入式-C语言基础:结构体
数组只能存放一种类型的数据,而结构体内可以存放不同类型的数据. #include<stdio.h> #include <string.h> struct Student { c ...