Python基础之字符串和编码
字符串和编码
字符串也是一种数据类型,但是字符串比较特殊的是还有个编码问题。
因为计算机自能处理数字,如果徐娅处理文本,就必须先把文本转换为数字才能处理,最早的计算机子设计时候采用8个比特(bit)作为以恶搞字节(byte),所以一个字节能表示最大的整数是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节,比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
又因为计算机是美国人发明的,最早只有127个字符被编码到计算机里,也就是现在的大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小些字母Z的编码是122。
但是要出来中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以中国制定了GB2312编码,用来把中文编进去。
你可以想象的到,全世界那么多语言,不同的语言编导不同的编码里去,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免的出现冲突,结果就是在多种语言混合的文本中,显示出来的会有乱码。
因此,Unicode字符集运而生,Unicode把所有的语言都统一到一套编码里,着样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是UCS-16编码,用两个字节表示一个字符(如果要用到非常偏僻的字符,这需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode.
现在捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码的十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000;注意字符 ‘0’和整数 0 是不同的。
汉字 中 已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的 01001110 00101101。
你可以猜测,如果把ASCII编码的 A 用Unicode编码,只需要在前面补0就可以,因此 A 的Unicode编码是00000000 01000001。
但是新的问题有出现了:如果统一成Unicode编码,乱码问题从此消失了,但是如果你些的文章基本上群不是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,子啊存储和传输上就十分不划算。
所以本着节约的精神,又出现了把Unicode编码转化为“客变长编码”的 UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉族通常是3个字节,姿势很生僻的字符才会被编码成4-6个字节,如果你要传输的文本含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以看成是UTF-8编码的一部分,所以大量只支持ASCII编码的历史遗留软件可以子啊UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统统一的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后报错的时候再把Unicode转换成UTF-8保存到文件:
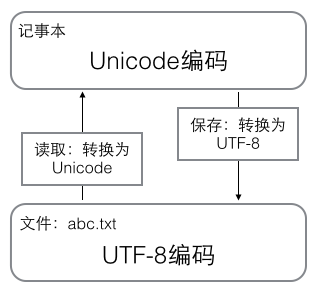
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
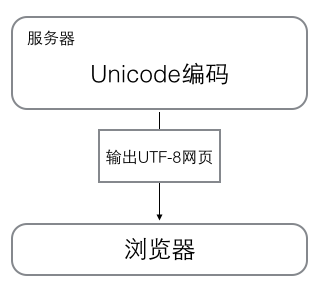
所以你看到很多网页的源码上会有类似的信息,表示改网页正式用的UTF-8编码。
Python的字符串
高清楚了令人头疼的字符编码问题后,我们再来研究Python的字符串,再最新的Python 3版本中,字符串式以Unicode编码的,也就是说Python的字符串支持多种语言,例如:
| >>> print(‘包含中文的str’) 包含中文的str |
|---|
对于单个字符的编码,Python提供了ord() 函数获取字符的整数表示,chr()函数把编码转换为对应的字符:

如果知道字符的整数编码,还可以用十六进制这么写 str:
| >>> ‘\u4e2d\u6587’ ‘中文’ |
|---|
两种写法完全是等价的。
由于Python的字符串类型是 str,在内存中以Unicode表示,一个字符对应若干个字节,如果要在网络上传输或者保存到磁盘上,就需要把str变成字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
| x =b’ABC’ |
|---|
要注意区分‘ABC’和 b’ABC’ ,前者是str,后者虽然内容显示得和前者一样,但是bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:

纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes,含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法吓死你hi为ASCII字符的字节,用\x##显示。
反过来如果我们从网络上或磁盘上读取了字节流,那么读到的数据就是bytes,要把bytes变成str,就需要用decode()方法:
| >>> b’ABC’.decode(‘ascii’) ‘ABC’ >>> b’\xe4\xbd\xa0\xe6\x9c\x89\xe7\x97\x85\xe5\x90\xa7’.decode(‘utf-8’) ‘你有病吧’ |
|---|
如果bytes中包含无法解码的字节,decode()方法会报错:

如果bytes中只是有一小部分无效的字节,可以传如errors=’ignore’忽略错误的字节:
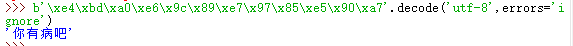
要计算str包含多少个字符,可以用len()函数:

len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
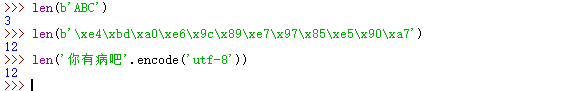
可见1个中文字符经过UTF-8编码后通常会占用3个字节,而一个字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互换,为了避免乱码问题,应该始终坚持使用UTF-8编码对str和bytes`进行转换。
由于Python源代码也是一个文本文件,所以当你的源代码中包含中文的时候,在保存源代码时候,就需要务必知道保存为UTF-8编码,当Python解释器读取源代码时候,wield让它按UTF-8编码读取,我们通常再我呢见开头写上这个两行:
|
#!/usr/bin/env python3
# -- coding: utf-8 --
|
|---|
第一行注释是为了告诉Linux/OS X系统,这是个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
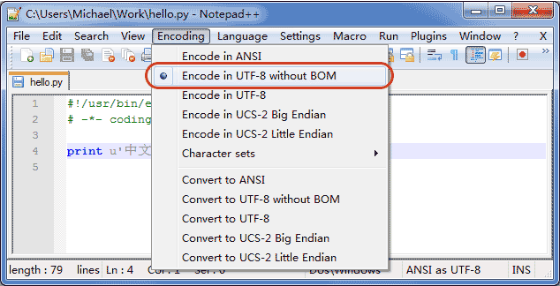
如果.py文件本身使用UTF-8编码,并且也申明了 # -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中文:
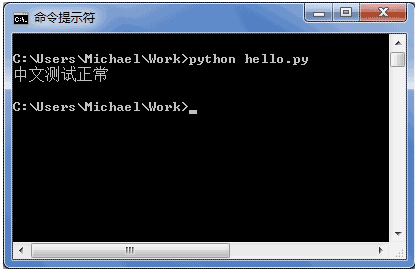
格式化
最后一个常见的问题是如何输出格式话的字符串,我们经常输出类似您好,您xx月的话费是xx,余额是xx 之类的字符串,而xxx的内容都是根据变量变化的,所以需要一种简便的格式化字符串的方法。
在Python中,采用的格式话方式和C语言是一致的,用% 实现,举例说明:
|
>>> ‘Hello, %s’ % ‘world’
‘Hello, world’
>>> ‘Hi, %s, you have $%d.’ % (‘Michael’, 1000000)
‘Hi, Michael, you have $1000000.’
|
|---|
常见的占位符有:
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
其中格式化
整数和浮点数还可以指定是否不0和整数与小数的位数:

如果你并不确定该用什么,%s永远起作用,他会把任何数据转换成为字符串:
|
>>> ‘Age: %s. Gender: %s’ % (25, True)
‘Age: 25. Gender: True’
|
|---|
有时候,字符串里面的% 是一个普通字符怎么办?这个时候就需要转义,用%% 来表示一个% :
| >>> ‘growth rate: %d %%’ % 7 ‘growth rate: 7 %’ |
|---|
format()
另一种格式化字符串的方法是使用字符串的format()方法,他会用传入的参数依次替换字符串内的占位符{0} 、 {1} …….,不过这种方法写起来比%要麻烦得多:
|
>>> ‘Hello, {0}, 成绩提升了 {1:.1f}%’.format(‘小明’, 17.125)
‘Hello, 小明, 成绩提升了 17.1%’
|
|---|
f-string
最后一种格式化字符串的方法是使用f 开头的字符串,称之为f-string ,它和普通字符串不同之处在于字符串如果包含{xxx} ,就会以对应的变量替换:
|
>>> r = 2.5 >>> s = 3.14 * r ** 2 >>> print(f’The area of a circle with radius {r} is {s:.2f}’) The area of a circle with radius 2.5 is 19.62 |
|---|
上述代码中{r} 被变量r 的值替换,{s:.2f} 被变量s 的值替换,并且:后面的.2f 指定了格式式参数(即保留两位小数),因此{s:.2f} 的替换结果是19.62 。
客户小练习:
|
a = 72
b = 85
r = ???
print(‘???’ % r)
|
|---|
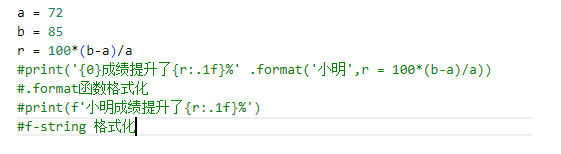
小结
Python 3的字符串使用Unicode,直接支持多种语言。当str 和bytes 互换时,需要指定编码,最常见的编码是UTF-8 编码,Python当然也支持其他编码方式,比如把Unicode编码成GB2312 :
|
>>> ‘中文’.encode(‘gb2312’)
b’\xd6\xd0\xce\xc4’
|
|---|
但是这种编码纯属自己找麻烦,如果不是特殊业务要求,请牢记使用UTF-8 编码。
格式化字符串的时候,可以用Python的交换环境测试,方便快捷。
文章转载【廖雪峰官方网站】:https://www.liaoxuefeng.com/wiki/1016959663602400/1017075323632896
Python基础之字符串和编码的更多相关文章
- Python基础数据类型-字符串(string)
Python基础数据类型-字符串(string) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客使用的是Python3.6版本,以及以后分享的每一篇都是Python3.x版 ...
- Python基础(二) —— 字符串、列表、字典等常用操作
一.作用域 对于变量的作用域,执行声明并在内存中存在,该变量就可以在下面的代码中使用. 二.三元运算 result = 值1 if 条件 else 值2 如果条件为真:result = 值1如果条件为 ...
- python基础知识3---字符编码
阅读目录 一 了解字符编码的知识储备 二 字符编码介绍 三 字符编码应用之文件编辑器 3.1 文本编辑器之nodpad++ 3.2 文本编辑器之pycharm 3.3 文本编辑器之python解释器 ...
- Python学习笔记 - 字符串和编码
#!/usr/bin/env python3 # -*- coding: utf-8 -*- #第一行注释是为了告诉Linux/OS X系统, #这是一个Python可执行程序,Windows系统会忽 ...
- python基础、字符串和if条件语句,while循环,跳出循环、结束循环
一:Python基础 1.文件后缀名: .py 2.Python2中读中文要在文件头写: -*-coding:utf8-*- 3.input用法 n为变量,代指某一变化的值 n = inpu ...
- python 3 学习字符串和编码
字符串和编码 阅读: 895464 字符编码 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字 ...
- python基础——6(字符编码,文件操作)
今日内容: 1.字符编码: 人识别的语言与机器识别的语言转化的媒介 ***** 2.字符与字节: 字符占多少字节,字符串转化 *** 3.文件操作: 操作硬盘中的一块区域:读写操作 ...
- Python基础__字符串拼接、格式化输出与复制
上一节介绍了序列的一些基本操作类型,这一节针对字符串的拼接.格式化输出以及复制的等做做详细介绍.一. 字符串的拼接 a = 'I', b = 'love', c = 'Python'. 我们的目的是: ...
- python基础类型—字符串
字符串str 用引号引起开的就是字符串(单引号,双引号,多引号) 1.字符串的索引与切片. 索引即下标,就是字符串组成的元素从第一个开始,初始索引为0以此类推. a = 'ABCDEFGHIJK' p ...
随机推荐
- linux篇-修改mysql数据库密码
总是忘记,每次都要查文档,背背背 方法1: 用SET PASSWORD命令 首先登录MySQL. 格式:mysql> set password for 用户名@localhost = passw ...
- SQL表的创建
一,创建表 1.使用鼠标创建表 1,进入SQL进行连接 编辑 2,在左边会有一个对象资源管理器,右键数据库,在弹出的窗口中选择新建数据库 编辑 3,给这个包取个名字,在这个界面可以给这个表选 ...
- 【Axure】母版引发事件
引发事件是指你将母版中某一元件的事件从母版中提升出来,以使其在页面的级别可用. 通过引发事件,可以对在不同页面上母版实例的同一个元件设置不同的交互. 设置引发事件 打开一个母版: 选择其中一个组件: ...
- [OCWA 模拟赛ADay1] 钢铁侠的逃离
Description 给定 \(A,B,N\) ,求 \(\sum\limits_{i=1}^{N} popcount(B+i*A)\) ,其中 \(popcount\) 是指数 \(x\) 在二进 ...
- Python <算法思想集结>之抽丝剥茧聊动态规划
1. 概述 动态规划算法应用非常之广泛. 对于算法学习者而言,不跨过动态规划这道门,不算真正了解算法. 初接触动态规划者,理解其思想精髓会存在一定的难度,本文将通过一个案例,抽丝剥茧般和大家聊聊动态规 ...
- fpm工具安装
概述 最近在对机房的编译环境做整理,过程曲折而痛苦,记录一下. 之前的一个老项目,在打包的时候用到了一个叫做fpm的工具. 编译环境涉及centos6和centos7,在新的编译环境的过程中,如何安装 ...
- windows和linux系统下测试端口连通性的命令
0. ping 1. telnet 2. ssh 3. curl 4. wget 5. tcping 6. 总结 本文地址: https://www.cnblogs.com/hchengmx/p/12 ...
- 基于.NetCore开发博客项目 StarBlog - (12) Razor页面动态编译
系列文章 基于.NetCore开发博客项目 StarBlog - (1) 为什么需要自己写一个博客? 基于.NetCore开发博客项目 StarBlog - (2) 环境准备和创建项目 基于.NetC ...
- Bika LIMS 开源LIMS集—— SENAITE的安装
安装环境 操作系统 Ubuntu 18.04 LTS Python 2.x. Plone 4 安装步骤 Ubuntu等Linux.Mac系统一般安装有Python的环境,但由于需要安装Python扩展 ...
- idea运行Tomcat出现 Address localhost:8080 is already in useAddress localhost:8080 is already in use
使用IDEA运行 tomcat时出现 Address localhost:8080 is already in use,就很奇怪,我明明只有这一个程序呀,怎么还会被占用.后来想想可能就是被其他进程占用 ...