数据仓库(5)数仓Kimball与Inmon架构的对比
数据仓库主要有四种架构,Kimball的DW/BI架构、独立数据集市架构、辐射状企业信息工厂Inmon架构、混合Inmon与Kimball架构。不过不管是那种架构,基本上都会使用到维度建模。
<b>Kimball的DW/BI架构</b>,可以参考这篇文章 数据仓库(4)基于维度建模的KimBall架构。
<b>独立数据集市架构</b>,采用这种架构的数据仓库,数据以部门为基础来部署,不考虑企业级别的信息共享和集成。也就是各个部门各自按照需要,各自在数据源同步数据,按照各自的标准,对数据进行处理。这种实际上就是没有架构,会造成分析数据的冗余存储,计算资源的浪费,会导致每一个统计部门统计口径的不统一,也就会导致因为数据口径不一致导致长时间的对数据。
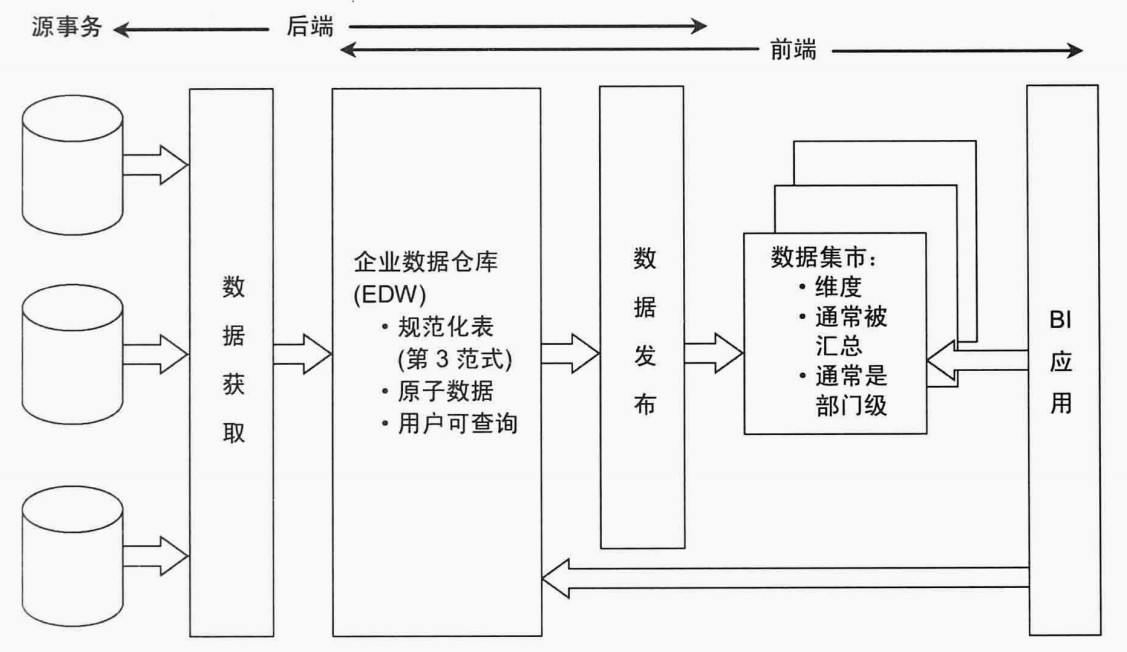
<b>辐射状企业信息工厂Inmon架构</b>,数据从操作型数据源中获取,在ETL中进行处理,获得的原子数据保存在满足第三范式的数据库中,这种规范化,原子数据的仓库就是企业信息工厂Inmon架构。Inmon架构与Kimball架构的差别之一就是,Inmon的数据仓库是规范化的,而Kimball架构是基于维度建模的星型模型。
<b>混合Inmon与Kimball架构</b>,这种就是将Kimball与Inmon两种架构进行嫁接,抽取过来的数据,存放在规范化的数据仓库中,然后在这个的基础之上抽取基于维度建模的数据展现,开发给数据分析人员等。
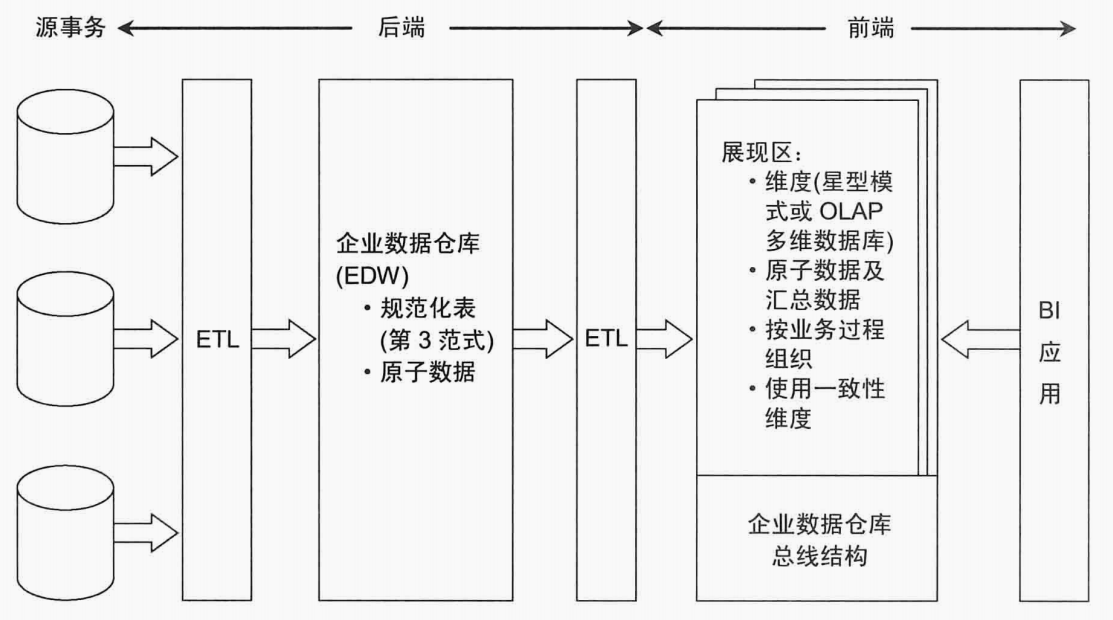
在经典的理论认为,混合Inmon与Kimball架构是最好的方式。这种方法可以将数据规范化,然后通过维度建模,以一种比较简单的方式开发给分析人员。但是这种方式适合比较传统的行业,或者政府单位,这种业务发展缓慢的模式,如果是互联网企业,特别是创业型团队,业务还在快速的迭代中,使用维度建模需要花费很长的前期准备工作,而且扩展性不好,使用Kimball维度建模是比较合适的。
Kimball 模式从流程上看是是自底向上的,即从数据集市到数据仓库再到数据源(先有数据集市再有数据仓库)的一种敏捷开发方法。对于Kimball模式,数据源每每是给定的若干个数据库表,数据较为稳定可是数据之间的关联关系比较复杂,须要从这些OLTP中产生的事务型数据结构抽取出分析型数据结构,再放入数据集市中方便下一步的BI与决策支持。所以<b>KimBall是根据需求来确定需要开发ETL哪些数据。</b>
Inmon 模式从流程上看是自顶向下的,即从数据源到数据仓库再到数据集市的(先有数据仓库再有数据市场)一种瀑布流开发方法。对于Inmon模式,数据源每每是异构的,好比从自行定义的爬虫数据就是较为典型的一种,数据源是根据最终目标自行定制的。这里主要的数据处理工做集中在对异构数据的清洗,包括数据类型检验,数据值范围检验以及其余一些复杂规则。在这种场景下,数据没法从stage层直接输出到dm层,必须先经过ETL将数据的格式清洗后放入dw层,再从dw层选择须要的数据组合输出到dm层。在Inmon模式中,并不强调事实表和维度表的概念,由于数据源变化的可能性较大,须要更增强调数据的清洗工做,从中抽取实体-关系。immon是将<b>整个数据仓库规划好,统一按照范式建模进行开发</b>。
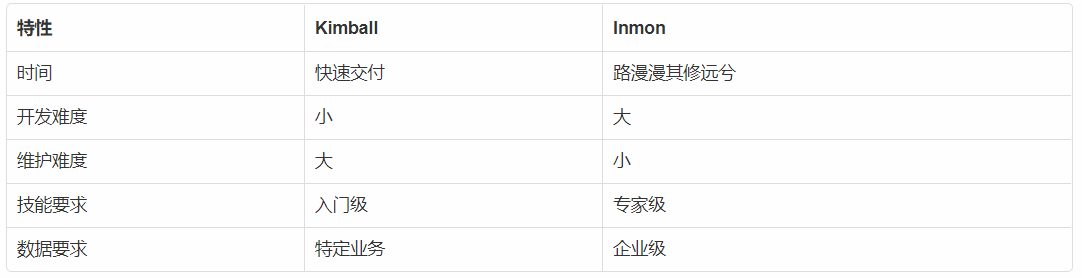
下面是两种架构的优劣比较。
> 参考文章:数据仓库(5)数仓Kimball与Inmon架构的对比
数据仓库(5)数仓Kimball与Inmon架构的对比的更多相关文章
- 数仓建设中最常用模型--Kimball维度建模详解
数仓建模首推书籍<数据仓库工具箱:维度建模权威指南>,本篇文章参考此书而作.文章首发公众号:五分钟学大数据,公众号中发送"维度建模"即可获取此书籍第三版电子书 先来介绍 ...
- 基于Hive进行数仓建设的资源元数据信息统计:Spark篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
- HAWQ取代传统数仓实践(十九)——OLAP
一.OLAP简介 1. 概念 OLAP是英文是On-Line Analytical Processing的缩写,意为联机分析处理.此概念最早由关系数据库之父E.F.Codd于1993年提出.OLAP允 ...
- 基于MaxCompute的数仓数据质量管理
声明 本文中介绍的非功能性规范均为建议性规范,产品功能无强制,仅供指导. 参考文献 <大数据之路——阿里巴巴大数据实践>——阿里巴巴数据技术及产品部 著. 背景及目的 数据对一个企业来说已 ...
- 基于Hive进行数仓建设的资源元数据信息统计:Hive篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
- 传统 BI 如何转大数据数仓
前几天建了一个数据仓库方向的小群,收集了大家的一些问题,其中有个问题,一哥很想去谈一谈--现在做传统数仓,如何快速转到大数据数据呢?其实一哥知道的很多同事都是从传统数据仓库转到大数据的,今天就结合身边 ...
- ETL数仓测试
前言 datalake架构 离线数据 ODS -> DW -> DM https://www.jianshu.com/p/72e395d8cb33 https://www.cnblogs. ...
- 数仓day01
1. 该项目适用哪些行业? 主营业务在线上进行的一些公司,比如外卖公司,各类app(比如:下厨房,头条,安居客,斗鱼,每日优鲜,淘宝网等等) 这类公司通常要针对用户的线上访问行为.消费行为.业务操作行 ...
- 看SparkSql如何支撑企业数仓
企业级数仓架构设计与选型的时候需要从开发的便利性.生态.解耦程度.性能. 安全这几个纬度思考.本文作者:惊帆 来自于数据平台 EMR 团队 前言 Apache Hive 经过多年的发展,目前基本已经成 ...
随机推荐
- 在linux上oracle服务启动停止详细
转至:https://www.cnblogs.com/baihuitestsoftware/articles/6365431.html 在CentOS 6.3下安装完Oracle 10g R2,重开机 ...
- @vue/cli的配置知道多少-publicPath,outputDir,assetsDir,indexPath,filenameHashing,configureWebpack,productionSourceMap
vue.config.js的简单介绍 vue.config.js 是一个可选的配置文件, 在项目的 (和 package.json 同级的) 根目录中存在这个文件. 默认情况没有这个文件需要我们手动去 ...
- ibv_free_device_list()函数
void ibv_free_device_list(struct ibv_device **list); 描述 函数用来释放当前可用的RDMA设备数组. 注意 数组一旦释放,指向设备的指针将不能再由i ...
- JZ-014-链表中倒数第 K 个结点
链表中倒数第 K 个结点 题目描述 输入一个链表,输出该链表中倒数第k个结点. 题目链接: 链表中倒数第 K 个结点 代码 /** * 标题:链表中倒数第 K 个结点 * 题目描述 * 输入一个链表, ...
- linux下编译安装php5.6出现 configure: error: Cannot find MySQL header files under /usr/local/mysql.
#yum install gcc gcc-c++ libxml2 libxml2-devel libjpeg-devel libpng-devel freetype-devel openssl-dev ...
- Idea 连接MySQL数据库
Idea 连接MySQL数据库 注意: 需要导入jar包,mysql-connector-java-8.0.16.jar mysql8.0及以上 使用的驱动 drive=com.mysql.cj.jd ...
- 通信原理:基于MATLAB的AM调幅分析
目的: 通过matlab仿真AM调制,通过图像分析来更好的了解AM调制的过程 1.为什么基带信号要加上一个直流分量. 2.所加直流分量为什么要大于基带信号的最大值. 3.时域中调制信号与载波和基带信号 ...
- idea创建web项目以及配置Tomcat
废话不多说,直接上干活: 1.在project中现创建好module,也就是java web项目 2.把路径名写清楚就行了 3.创建在WEB-INF上右击创建classes和lib以存储class编译 ...
- Java反射详解篇--一篇入魂
1.反射概述 Java程序在运行时操作类中的属性和方法的机制,称为反射机制. 一个关键点:运行时 一般我们在开发程序时,都知道自己具体用了什么类,直接创建使用即可.但当你写一些通用的功能时没办法在编写 ...
- 27.Java 飞机游戏小项目
开篇 游戏项目基本功能开发 飞机类设计 炮弹类设计 碰撞检测设计 爆炸效果的实现 其他功能 计时功能 游戏项目基本功能开发 这里将会一步步实现游戏项目的基本功能. 使用 AWT 技术画出游戏主窗口 A ...