基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse。 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse。
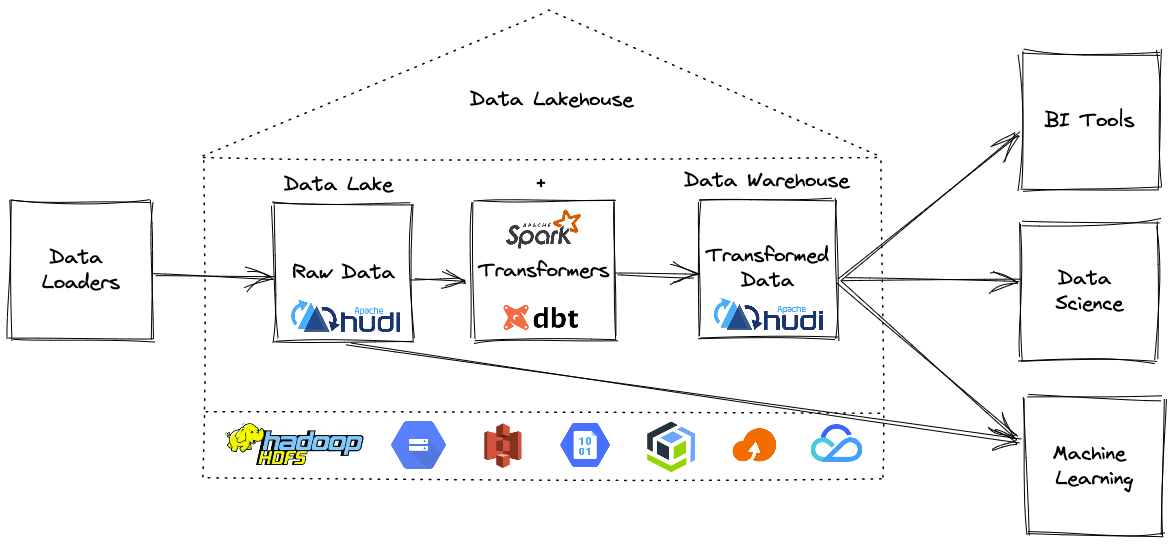
在深入了解细节之前,让我们先澄清一下本博客中使用的一些术语。
什么是 Apache Hudi?
Apache Hudi 为Lakehouse带来了 ACID 事务、记录级更新/删除和变更流。
Apache Hudi 是一个开源数据管理框架,用于简化增量数据处理和数据管道开发。该框架更有效地管理数据生命周期等业务需求并提高数据质量。
什么是dbt?
dbt(数据构建工具)是一种数据转换工具,使数据分析师和工程师能够在云数据仓库中转换、测试和记录数据。
dbt 使分析工程师能够通过简单地编写select语句来转换其仓库中的数据。 dbt 处理将这些select语句转换为表和视图。
dbt 在 ELT(提取、加载、转换)过程中执行 T——它不提取或加载数据,但它非常擅长转换已经加载到仓库中的数据。
什么是Lakehouse?
Lakehouse 是一种新的开放式架构,它结合了数据湖和数据仓库的最佳元素。 Lakehouses 是通过一种新的系统设计实现的:在开放格式的低成本云存储之上直接实施类似于数据仓库中的事务管理和数据管理功能。如果必须在现代世界中重新设计数据仓库,Lakehouse便是首选,因为现在可以使用廉价且高度可靠的存储(以对象存储的形式)。
换句话说,虽然数据湖历来被视为添加到云存储文件夹中的一堆文件,但 Lakehouse 表支持事务、更新、删除,在 Apache Hudi 的情况下,甚至支持索引或更改捕获等类似数据库的功能。
如何建造一个开放的Lakehouse?
现在我们知道什么是Lakehouse了,所以让我们建造一个开放的Lakehouse,你需要几个组件:
- 支持 ACID 事务的开放表格式
- Apache Hudi(与 dbt 集成)
- Delta Lake(锁定到 Databricks 运行时的专有功能)
- Apache Iceberg(目前未与 dbt 集成)
- 数据转换工具
- 开源 dbt 是转换层事实上的流行选择
- 分布式数据处理引擎
- Apache Spark 是计算引擎事实上的流行选择
- 云储存
- 可以选择任何具有成本效益的云存储或 HDFS
- 选择最心仪的查询引擎
构建 Lakehouse需要一种方法来提取数据并将其加载为 Hudi 表格式,然后使用 dbt 就地转换。
DBT 通过 dbt-spark 适配器包支持开箱即用的 Hudi。使用 dbt 创建建模数据集时,您可以选择 Hudi 作为表的格式。
可以按照此页面上的说明学习如何安装和配置 dbt+hudi。
第 1 步:如何提取和加载原始数据集?
这是构建Lakehouse的第一步,这里有很多选择可以将数据加载到我们的开放Lakehouse中。可以使用 Hudi 的 Delta Streamer工具,因为所有摄取功能都是预先构建的,并在大规模生产中经过实战测试。
Hudi 的 DeltaStreamer 在 ELT(提取、加载、转换)过程中执行 EL——它非常擅长提取、加载和可选地转换已经加载到 Lakehouse 中的数据。
第二步:如何用dbt项目配置Hudi?
要将 Hudi 与 dbt 项目一起使用,需要选择文件格式为 Hudi。文件格式配置可以在特定模型中指定,也可以为 dbt_project.yml 文件中的所有模型指定:
models:
+file_format: hudi
或者
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
file_format = 'hudi',
unique_key = 'id',
…
) }}
选择 Hudi 作为 file_format 后,可以使用 dbt 创建物化数据集,这提供了 Hudi 表格式独有的额外好处,例如字段级更新/删除。
第三步:如何增量读取原始数据?
在我们学习如何构建增量物化视图之前,让我们快速了解一下,什么是 dbt 中的物化?物化是在 Lakehouse 中持久化 dbt 模型的策略。 dbt 中内置了四种类型的物化:
- table
- view
- incremental
- ephemeral
在所有物化类型中,只有增量模型允许 dbt 自上次运行 dbt 以来将记录插入或更新到表中,这释放了 Hudi 的能力,我们将深入了解细节。
使用增量模型需要执行以下两个步骤:
- 告诉 dbt 如何过滤增量执行的行
- 定义模型的唯一性约束(使用>= Hudi 0.10.1版本时需要)
如何在增量运行中应用过滤器?
dbt 提供了一个宏 is_incremental(),它对于专门为增量实现定义过滤器非常有用。
通常需要过滤“新”行,例如自上次 dbt 运行此模型以来已创建的行。查找此模型最近运行的时间戳的最佳方法是检查目标表中的最新时间戳。 dbt 通过使用“{{ this }}”变量可以轻松查询目标表。
{{
config(
materialized='incremental',
file_format='hudi',
)
}}
select
*
from raw_app_data.events
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where event_time > (select max(event_time) from {{ this }})
{% endif %}
如何定义唯一性约束?
unique_key 是数据集的主键,它确定记录是否具有新值,是否应该更新/删除或插入。
可以在模型顶部的配置块中定义 unique_key。 这个 unique_key 将作为 Hudi 表上的主键(hoodie.datasource.write.recordkey.field)。
第 4 步:如何在编写数据集时使用 upsert 功能?
dbt 在加载转换后的数据集时提供了多种加载策略,例如:
- append(默认)
- insert_overwrite(可选)
- merge(可选,仅适用于 Hudi 和 Delta 格式)
默认情况下dbt 使用 append 策略,当在同一有效负载上多次执行 dbt run 命令时,可能会导致重复行。
当你选择insert_overwrite策略时,dbt每次运行dbt都会覆盖整个分区或者全表加载,这样会造成不必要的开销,而且非常昂贵。
除了所有现有的加载数据的策略外,使用增量物化时还可以使用Hudi独占合并策略。使用合并策略可以对Lakehouse执行字段级更新/删除,这既高效又经济,因此可以获得更新鲜的数据和更快的洞察力。
如何执行字段级更新?
如果使用合并策略并指定了 unique_key,默认情况下dbt 将使用新值完全覆盖匹配的行。
由于 Apache Spark 适配器支持合并策略,因此可以选择将列名列表传递给 merge_update_columns 配置。在这种情况下dbt 将仅更新配置指定的列,并保留其他列的先前值。
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
file_format = 'hudi',
unique_key = 'id',
merge_update_columns = ['msg', 'updated_ts'],
) }}
如何配置额外的Hudi自定义配置?
如果想指定额外的 Hudi 配置时,可以使用选项配置来做到这一点:
{{ config(
materialized='incremental',
file_format='hudi',
incremental_strategy='merge',
options={
'type': 'mor',
'primaryKey': 'id',
'precombineKey': 'ts',
},
unique_key='id',
partition_by='datestr',
pre_hook=["set spark.sql.datetime.java8API.enabled=false;"],
)
}}
总结
希望本篇博文可以助力基于Apache Hudi 与 dbt构建开放的 Lakehouse !
基于 Apache Hudi 和DBT 构建开放的Lakehouse的更多相关文章
- 基于Apache Hudi和Debezium构建CDC入湖管道
从 Hudi v0.10.0 开始,我们很高兴地宣布推出适用于 Deltastreamer 的 Debezium 源,它提供从 Postgres 和 MySQL 数据库到数据湖的变更捕获数据 (CDC ...
- 基于 Apache Hudi + Presto + AWS S3 构建开放Lakehouse
认识Lakehouse 数据仓库被认为是对结构化数据执行分析的标准,但它不能处理非结构化数据. 包括诸如文本.图像.音频.视频和其他格式的信息. 此外机器学习和人工智能在业务的各个方面变得越来越普遍, ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- 基于Apache Hudi构建分析型数据湖
为了有机地发展业务,每个组织都在迅速采用分析. 在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能. 通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特 ...
随机推荐
- Java使用类-String
String,StringBuffer,StringBuild 大佬的理解-><深入理解Java中的String> 1.String 1.1 String 实例化 String st ...
- ShardingSphere-proxy-5.0.0分布式哈希取模分片实现(四)
一.说明 主要是对字符串的字段进行hash取模 二.修改配置文件config-sharding.yaml,并重启服务 # # Licensed to the Apache Software Found ...
- 【黑马pink老师的H5/CSS课程】(二)标签与语法
视频链接:P8~P29 黑马程序员pink老师前端入门教程,零基础必看的h5(html5)+css3+移动 参考链接: HTML 元素 1.HTML语法规范 1.1 基本语法概述 HTML 标签是由尖 ...
- python——进行年龄和性别检测
年龄和性别检测 使用Python编程语言带你完成使用机器学习进行年龄和性别检测的任务. 首先需要编写用于检测人脸的代码,因为如果没有人脸检测,我们将无法进一步完成年龄和性别预测的任务. 下一步是预测图 ...
- 一个紧张刺激的聊天器,要不要进来看看(Python UDP网络模型)
先来哔哔两句:(https://jq.qq.com/?_wv=1027&k=QgGWqAVF) 互联网的本质是什么?其实就是信息的交换.那么如何将自己的信息发送到其他人的电脑上呢?那就需要借助 ...
- Task.Run(), Task.Factory.StartNew() 和 New Task() 的行为不一致分析
重现 在 .Net5 平台下,创建一个控制台程序,注意控制台程序的Main()方法如下: static async Task Main(string[] args) 方法的主体非常简单,使用Task. ...
- Error:(4, 13) java: -source 1.5 中不支持默认方法 (请使用 -source 8 或更高版本以启用默认方法)
- APISpace 月出月落和月相API接口 免费好用
月出和月落的位置,正如地球围绕太阳变化时产生的日出和日落一样,但是也和月相有关.一天中月亮升起的时间取决于它的月相.当你记得月相取决于太阳,月亮和地球的相对位置应该是明显的.月相是指从地球上看月球直 ...
- 微信小程序使用echarts/数据刷新重新渲染/图层遮挡问题
1.微信小程序使用echarts,首先下载echarts并导入小程序项目中,因小程序后期上线对文件大小有要求,所以建议进行定制下载导入可减少文件大小占比,也可以下载以前旧版本文件比较小的应付使用 下载 ...
- SpringBoot配置文件读取过程分析
整体流程分析 SpringBoot的配置文件有两种 ,一种是 properties文件,一种是yml文件.在SpringBoot启动过程中会对这些文件进行解析加载.在SpringBoot启动的过程中, ...