爬取西刺代理的IP与端口(一)
0x01 简陋代码是,获取(.*?)的字符串
#coding:utf-8
from requests import *
import re
headers = { "accept":"text/html,application/xhtml+xml,application/xml;",
"accept-encoding":"gzip",
"accept-language":"zh-cn,zh;q=0.8",
"referer":"Mozilla/5.0(compatible;Baiduspider/2.0;+http://www.baidu.com/search/spider.html)",
"connection":"keep-alive",
"user-agent":"mozilla/5.0(windows NT 6.1;wow64) applewebkit/537.36 (khtml,like gecko)chrome/42.0.2311.90 safari/537.36"
}
url="https://www.xicidaili.com/wn/"
html=get(url,timeout=3,headers=headers).text
iplist = re.findall('<td>(.*?)</td>',html)
print(iplist)

0x02 只爬取IP与端口,findall带两个(.*?),则两个为一组
#coding:utf-8
from requests import *
import re
headers = { "accept":"text/html,application/xhtml+xml,application/xml;",
"accept-encoding":"gzip",
"accept-language":"zh-cn,zh;q=0.8",
"referer":"Mozilla/5.0(compatible;Baiduspider/2.0;+http://www.baidu.com/search/spider.html)",
"connection":"keep-alive",
"user-agent":"mozilla/5.0(windows NT 6.1;wow64) applewebkit/537.36 (khtml,like gecko)chrome/42.0.2311.90 safari/537.36"
}
url="https://www.xicidaili.com/wn/"
html=get(url,timeout=3,headers=headers).text
pattern = re.compile('<tr class=".*?">.*?<td.*?</td>.*?<td>(.*?)</td>.*?<td>(.*?)</td>.*?</tr>', re.S)
iplist = re.findall(pattern,html)
print(iplist)
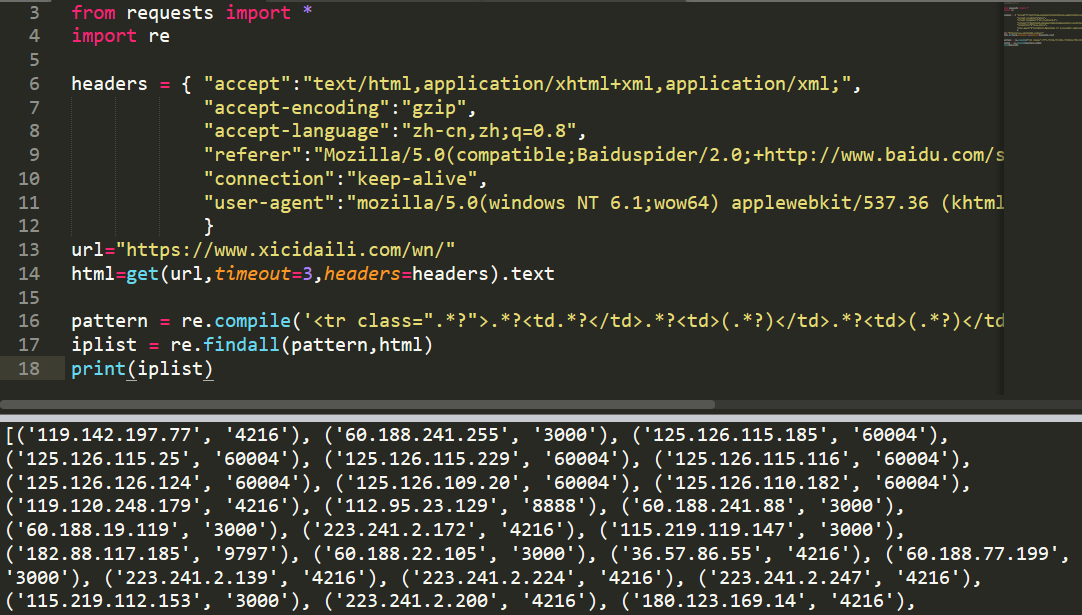
这样就简单多了,直接for循环把每个元组提取出来,且元组支持切片,[0]获取每个ip,[1]获取每个端口
0x03 最终输出格式如下
#coding:utf-8
from requests import *
import re
headers = { "accept":"text/html,application/xhtml+xml,application/xml;",
"accept-encoding":"gzip",
"accept-language":"zh-cn,zh;q=0.8",
"referer":"Mozilla/5.0(compatible;Baiduspider/2.0;+http://www.baidu.com/search/spider.html)",
"connection":"keep-alive",
"user-agent":"mozilla/5.0(windows NT 6.1;wow64) applewebkit/537.36 (khtml,like gecko)chrome/42.0.2311.90 safari/537.36"
}
url="https://www.xicidaili.com/wn/"
html=get(url,timeout=3,headers=headers).text
pattern = re.compile('<tr class=".*?">.*?<td.*?</td>.*?<td>(.*?)</td>.*?<td>(.*?)</td>.*?</tr>', re.S)
iplist = re.findall(pattern,html)
#print(iplist)
for i in iplist:
#print(i[0])
#print(i[1])
url="http://%s:%s"%(i[0],i[1])
print(url)

爬取西刺代理的IP与端口(一)的更多相关文章
- 使用XPath爬取西刺代理
因为在Scrapy的使用过程中,提取页面信息使用XPath比较方便,遂成此文. 在b站上看了介绍XPath的:https://www.bilibili.com/video/av30320885?fro ...
- Python四线程爬取西刺代理
import requests from bs4 import BeautifulSoup import lxml import telnetlib #验证代理的可用性 import pymysql. ...
- 手把手教你使用Python爬取西刺代理数据(下篇)
/1 前言/ 前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看.今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下. /2 首页分析 ...
- Scrapy爬取西刺代理ip流程
西刺代理爬虫 1. 新建项目和爬虫 scrapy startproject daili_ips ...... cd daili_ips/ #爬虫名称和domains scrapy genspider ...
- python scrapy 爬取西刺代理ip(一基础篇)(ubuntu环境下) -赖大大
第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrapy框架 具体就自行百度了,主要内容不是在这. 第二步:创建scrapy(简单介绍) 1.Creating a p ...
- python+scrapy 爬取西刺代理ip(一)
转自:https://www.cnblogs.com/lyc642983907/p/10739577.html 第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrap ...
- python3爬虫-通过requests爬取西刺代理
import requests from fake_useragent import UserAgent from lxml import etree from urllib.parse import ...
- 爬取西刺ip代理池
好久没更新博客啦~,今天来更新一篇利用爬虫爬取西刺的代理池的小代码 先说下需求,我们都是用python写一段小代码去爬取自己所需要的信息,这是可取的,但是,有一些网站呢,对我们的网络爬虫做了一些限制, ...
- 爬取西刺网的免费IP
在写爬虫时,经常需要切换IP,所以很有必要自已在数据维护库中维护一个IP池,这样,就可以在需用的时候随机切换IP,我的方法是爬取西刺网的免费IP,存入数据库中,然后在scrapy 工程中加入tools ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
随机推荐
- Netty源码—2.Reactor线程模型一
大纲 1.关于NioEventLoop的问题整理 2.理解Reactor线程模型主要分三部分 3.NioEventLoop的创建 4.NioEventLoop的启动 1.关于NioEventLoop的 ...
- boot3+JDK17+spring-cloud-gateway:4.0.0+spring-cloud:2022.0.0.0+Nacos2.2.1配置动态路由的网关
项目依赖 配置 # Nacos帮助文档: https://nacos.io/zh-cn/docs/concepts.html # Nacos认证信息 spring.cloud.nacos.config ...
- 从零开始开发一个 MCP Server!
大家好!我是韩老师. 最近,在 AI 开发领域,MCP (Model Context Protocol) 是越来越火了! 前几天,我我也开发了一款 Code Runner MCP Server: Co ...
- C# 13 中的新增功能实操
前言 今天大姚带领大家一起来看看 C# 13 中的新增几大功能,并了解其功能特性和实际应用场景. 前提准备 要体验 C# 13 新增的功能可以使用最新的 Visual Studio 2022 版本或 ...
- Object类--equals方法--java进阶day05
1.equals方法 2.equals方法的逻辑 如图,我们发现调用equals方法将两个属性一样的变量进行比较时,返回的还是false 为了了解清楚equals方法的逻辑,我们ctrl 鼠标右键点击 ...
- 构建窗体--java进阶day03
1.窗体对象Jframe 要创建窗体就需要Jframe对象,窗体创建好不会自己显示,还需要我们自己写一段代码让其显示 2.设置窗体可见--setVisible(true) 该方法用于显示窗体 3.窗体 ...
- 【Java】Math类的基本操作
Math类 Math 类是数学操作类,提供了一系列的数学操作方法,包括求绝对值.三角函数等,在 Math 类中提供的一切方法都是静态方法(类方法),所以直接由类名称调用即可. Math类的基本操作: ...
- 【数据结构与算法】Java链表与递归:移除链表元素
Java链表与递归:移除链表元素 Java https://leetcode-cn.com/problems/remove-linked-list-elements/solution/javalian ...
- 关于er图的几个工具
建立数据库包括其他的er图,这个太重要了.因为这关于效率和清晰思路. 但是目前感觉好用的还是ER/Studio.如果不差银子还是建议用这一款.真的好方便. 1.正向逆向工程非常顺利和快捷. 2.物理模 ...
- langchain0.3教程:聊天机器人进阶之方法调用
我们思考一个问题:大语言模型是否能帮我们做更多的事情,比如帮我们发送邮件.默认情况下让大模型帮我们发送邮件,大模型会这样回复我们: 可以看到,大模型无法发送邮件,它只会帮我们生成一个邮件模板,然后让我 ...