X6在数栈指标管理中的应用
一、需求背景
产品成立之初,产品的需求是需要对各种指标进行公式运算,组合成一个新的复合指标,供后续使用。当时产品提出的形式是有两种:
一种是直接让用户输入,不作任何其他操作,但这种方式带来的问题一个是,需要前端对公式进行复杂的校验,太多不可控的问题,另一个是操作指导性很弱,用户在使用的时候没有任何限制,也并不太能明白如何操作;
另一种方式就是让用户通过拖拽的方式,添加运算符,去组成自己需要的公式,比较直观,且视觉效果更好,所以最终产品交互选定用这种方式。
二、选型考虑
复合指标的高级模式功能点分解:拖拽指标、新增运算符,设置指标的过滤条件,设置条件的过滤,去更新数据;节点新增后,重新计算位置,更新渲染。
关于拖拽后生成一个节点、且有序排列,针对当前节点新增前后节点,使其整齐排列,技术范围确定到G6、X6上面。但对于是选用G6还是X6,从以下五个方面考虑:
1、针对上述需求分解,可以看到我们这个需求是偏重数据编辑的,而官方对于G6、X6的建议是,G6偏向于图可视化和分析,X6偏向于图编辑和数据编辑
2、自定义能力大小。由于指标管理中的节点并非只是个节点,而是可能是指标、操作符、输入框,形式多样,且,指标类型的节点需要展示的信息比较多,里面包含了图片、颜色、文本等信息,如果使用X6是可以直接用html写的,而使用G6就要熟悉了解canvas,新版本的G6可以支持jsx语法自定义节点,但并没有支持的那么好。
3、数据量大小。如果是节点繁多,图的规模较大,想要交互流畅,当然是用canvas的G6更合适,但如果数据量比较小,则都可以。
4、是否需要统计图表节点:G6 支持嵌入 G2 的统计图到一个节点中,而当前需求是不需要嵌入图表节点
5、是否需要支持移动端/小程序:在移动端,G6 可以支持展示和简单交互,且在不断完善中。而且移动端、小程序对性能的要求更高,所以如果是要支持移动端或小程序会优选G6
三、指标管理中复合指标的使用
关于X6在数栈指标管理的应用,主要是在复合指标的新增、编辑、删除模块,其中,分为普通、高级两种模式,其区别是:
普通模式仅可单公式,例如(A+B)*0.3;
而高级模式则可以配置多公式,例如当A >=0时,(A+B)*0.3;当A < 0时,(A+C-B)*0.4;
而本文主要叙述的是高级模式的相关内容,关于其操作,主要分为以下几个方面:
1、新增
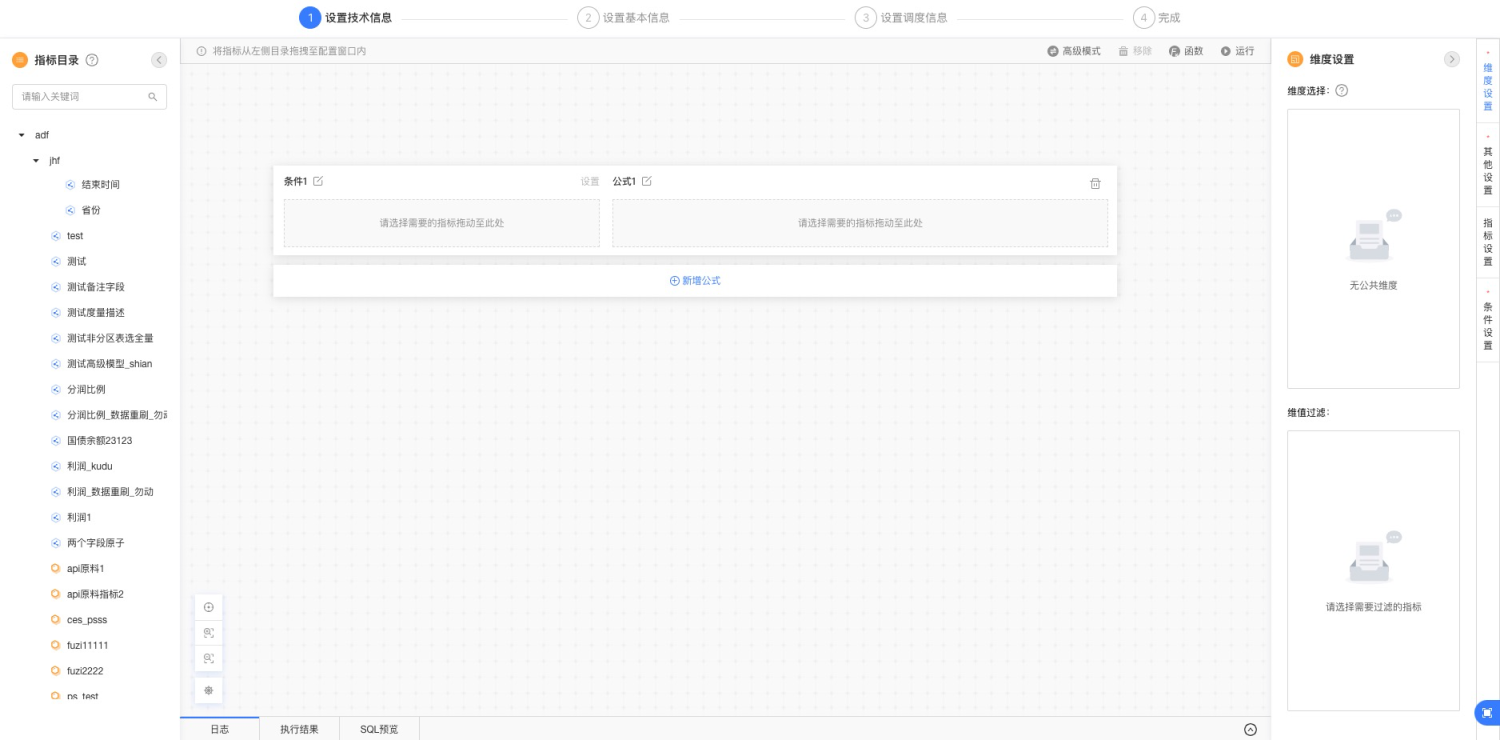

图3-1
参考图3-1,可以点击“新增公式”新增一条包含条件和公式的单公式;拖动左侧指标目录中的指标到右侧对应区域,可以将指标添加到条件或者公式里去。
2、编辑

图3-2

图3-3
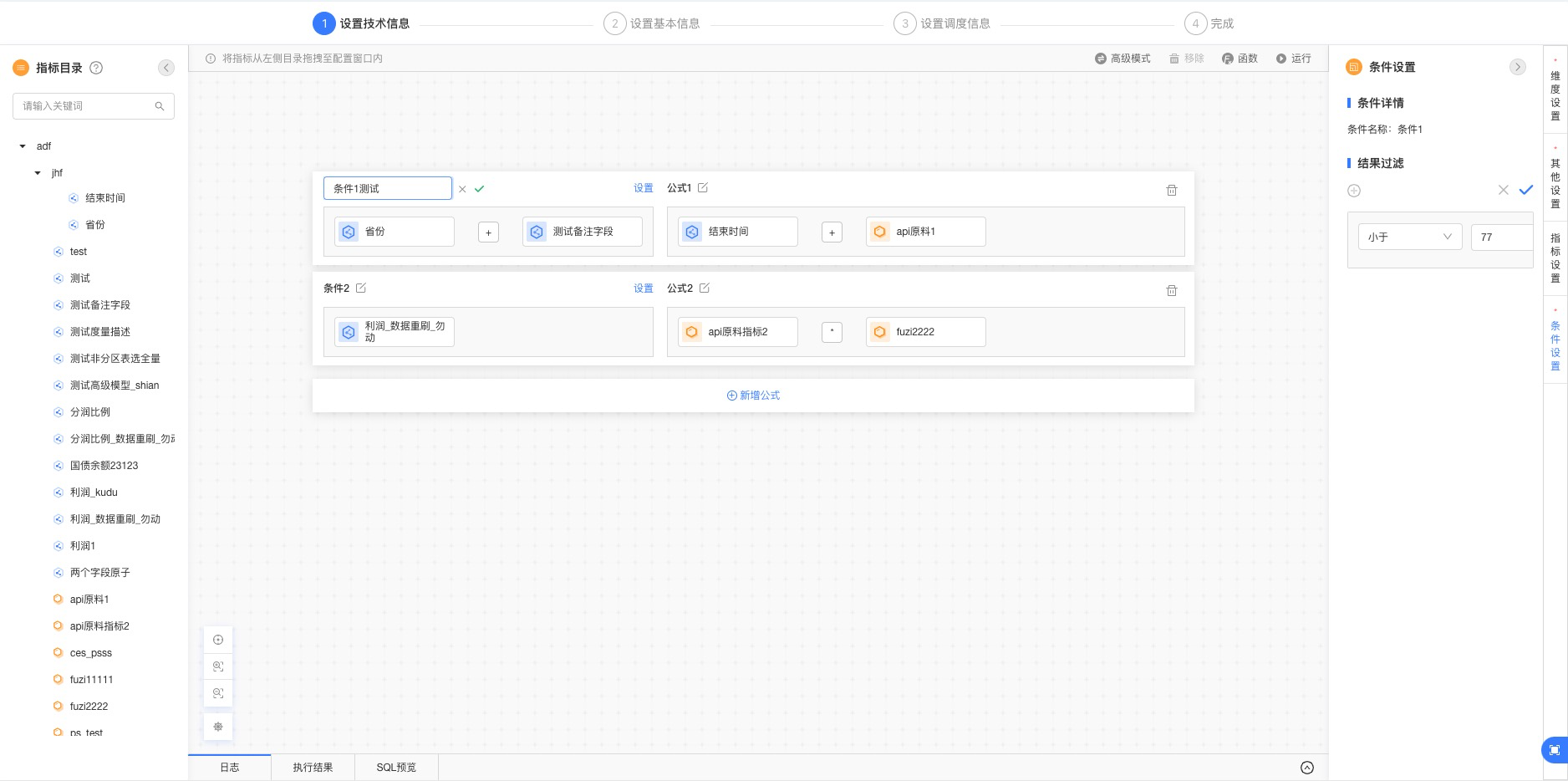
图3-4

图3-5
如图3-2所示,我们可以点击对应指标将其选中,对这个选中指标进行结果过滤设置;如图3-3所示,我们可以点击条件右上角的“设置”按钮,对当前条件进行结果过滤设置;可以点击条件或者公式后的图标,对条件名、公式名进行编辑;如图3-5所示,点击维度设置,可以对当前所有加入到画布中的指标的公共维度进行设置,与此同时选中某一个指标,可以对当前选中指标进行维值过滤设置。
3、删除
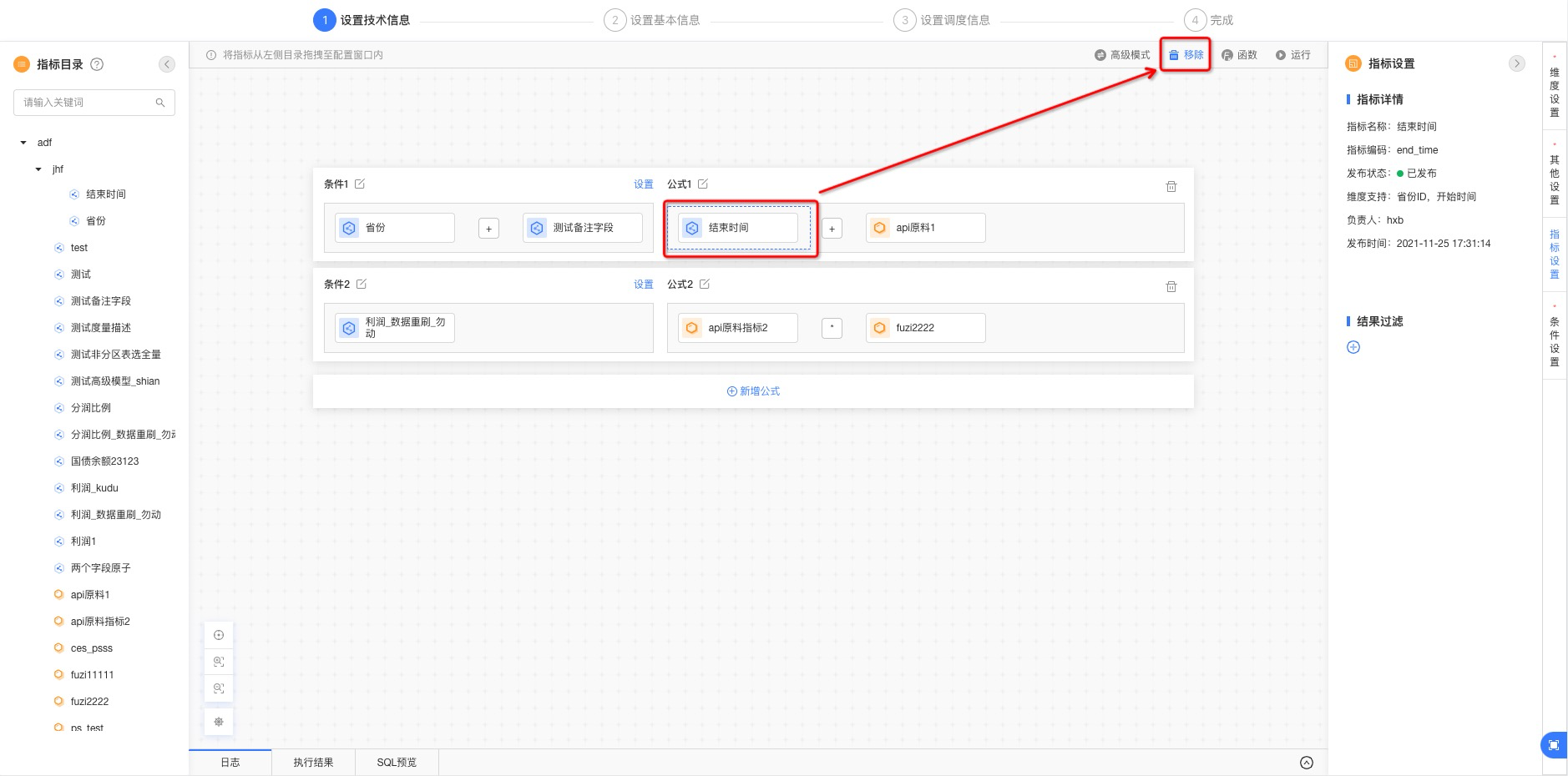
图3-6
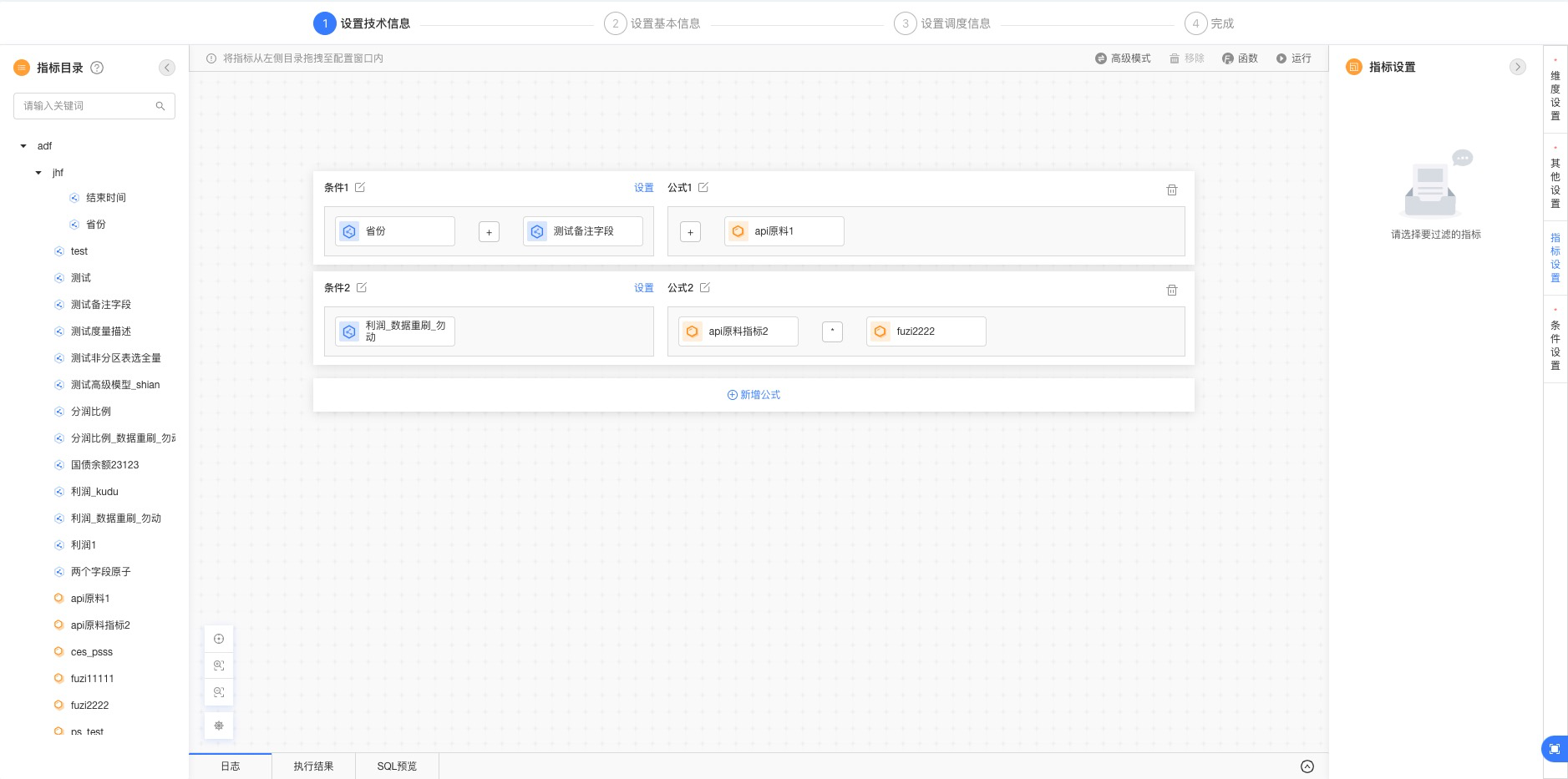
图3-7
如图3-5所示,可以在选中某一个指标之后,点击窗口右上角的“删除”按钮,将选中指标从当前公式中删除,最终得到的结果如图3-6所示;同样可以点击公式右边的删除图标,会将当前一整条公式(包含条件、公式)都删除。
4、查看
查看是指从指标列表里的某个复合指标右侧的“编辑”操作进入编辑页面,可以看到上次保存的配置好的公式信息,选中不同指标、点击不同条件的设置,会回显出上一次你保存的结果过滤信息。
四、X6的具体使用
新手入门快速上手点这里:快速上手 | X6
而关于两种模式的实现区别则是数据处理上的区别,核心使用步骤有以下几点:
1、确定数据结构
高级模式下可以只配置一条公式,但是也可以通过点击新增公式按钮增加多条公式,公式数量上限为5条。对于X6来说,对HTML的支持、自定义的能力都是很不错的,所以对于自定义效果比较高的指标管理中的节点,我们根据视觉效果可以定出整体数据结构为
//指标基础信息
const indexInfo = {
name: '',
code: '',
status: '',
...
}
// 高级模式数据结构
const advancedFormula = [
...
{
condition: {
name: '条件1',
conditionSet: {},
formulaList: [
{
type: 'index', // index--指标节点 operator--运算符节点
value: '', // 当type为operator,且value有值时,则有数值输入框类型
...indexInfo
}
]
},
formula: {
name: '公式1',
formulaList: [
{
type: 'index', // index--指标节点 operator--运算符节点
value: '', // 当type为operator,且value有值时,则有数值输入框类型
...indexInfo
}
]
}
}
]
2、从数据结构到视图的渲染过程
这个过程主要是调用X6的API中提供的graph.addNode方法去添加节点到画布。
但首先要遍历数据结构处理为带着层级信息的数据,然后通过遍历数据结构,并同时将层级关系和指标信息加入到节点信息里,以确保在操作新增、编辑等操作时可以准确获取到层级信息,能够准备新增、插入、编辑节点信息。
drawAdvancedNode = (data: any) => {
// 画高级模式的层级结构,从单条公式父框 ---> 单条公式的条件 + 单条公式的公式 -----> 具体的操作、指标
if (data.length === 0) {
return false;
}
// 遍历数据结构调用graph.addNode方法添加对应节点到画布中: 计算每个节点对应的具体x、y坐标
};
3、更新
更新的过程主要是在进行了新增、插入、编辑等操作后,会更改原数据,生成一份新的数据,这时候需要拿到新的数据进行重新渲染,需要将画布上的内容清空,然后重新绘制,而涉及到画布清空会用到clearCells方法,但高级模式会存在层级,所以会发现,使用这个方法并不能有效的把画布清空,所以最终先将所有节点获取到,再一一移除。在移除之后,将当前新数据渲染到画布中,即重复步骤2中的操作
// 清空所有画布中的节点
const allNodes = this.state.graph.getCells();
allNodes.map((item: any) => {
this.state.graph.removeCell(item.id);
});
4、提交
遍历所有的数据,将层级信息字段去掉;对一些为空字段做过滤处理;将一些额外字段整理到节点数据中去;对画布上的现有公式的合法性做出校验,若是不合法公式则弹出提示。格式化完成后则可允许用户将画布中的数据提交到后端。
X6在数栈指标管理中的应用的更多相关文章
- 袋鼠云研发手记 | 数栈·开源:Github上400+Star的硬核分布式同步工具FlinkX
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 数栈运维实例:Oracle数据库运维场景下,智能运维如何落地生根?
从马车到汽车是为了提升运输效率,而随着时代的发展,如今我们又希望用自动驾驶把驾驶员从开车这项体力劳动中解放出来,增加运行效率,同时也可减少交通事故发生率,这也是企业对于智能运维的诉求. 从人工运维到自 ...
- Molecule实现数栈至简前端开发新体验
Keep It Simple, Stupid. 这是开发人耳熟能详的 KISS 原则,也像是一句有调侃意味的善意提醒,提醒每个前端人,简洁易懂的用户体验和删繁就简的搭建逻辑就是前端开发的至简大道. 这 ...
- OpenStack安装部署管理中常见问题解决方法
一.网络问题-network 更多网络原理机制可以参考<OpenStack云平台的网络模式及其工作机制>. 1.1.控制节点与网络控制器区别 OpenStack平台中有两种类型的物理节点, ...
- 袋鼠云研发手记 | 开源·数栈-扩展FlinkSQL实现流与维表的join
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 堆,栈,内存管理, 拓展补充-Geekband
8, 堆,栈,内存管理 栈: local objects 在离开作用域之后就会被消除. 堆: new MyClass 一直会存在 静态对象: static local object 作用域在 ...
- flask 源码专题(十一):LocalStack和Local对象实现栈的管理
目录 04 LocalStack和Local对象实现栈的管理 1.源码入口 1. flask源码关于local的实现 2. flask源码关于localstack的实现 3. 总结 04 LocalS ...
- 04 flask源码剖析之LocalStack和Local对象实现栈的管理
04 LocalStack和Local对象实现栈的管理 目录 04 LocalStack和Local对象实现栈的管理 1.源码入口 1. flask源码关于local的实现 2. flask源码关于l ...
- 简单设计一个onedata指标管理体系
以阿里云的maxcompute的数据仓库架构为例, 从上往下定义, dwp的数据,来源是dws+dim,最主要是dws.这里不讨论dim的作用. dws的数据来源于dwd. dwd的数据来源于ods. ...
- 袋鼠云出品!数栈UI 5.0全新体验升级,设计背后的故事
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品.我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值. 前言 数栈作为云原⽣⼀站式⼤数据开发平台,从2016年发布第⼀个版本 ...
随机推荐
- Delphi让网页只允许在WebBrowser里面打开
[添加组件] 添加 Internet->WebBrowser //显示网页 [添加事件] 鼠标点击WebBrowser组件,在Events事件选项框中找到. OnNewWindows2,OnSt ...
- 【Ubuntu】vim-9.1.0821 编译安装
[Ubuntu]vim-9.1.0821 编译安装 零.起因 由于 Ubuntu 库中的vim版本只有8点几,满足不了需求,故需要自己编译安装更新的版本,本文介绍如何安装更新的vim版本. 壹.操作步 ...
- rabbitmq防止消息的重复消费
一.rabbitmq出现消息重复的场景 A:消息消费成功,事务已经提交,ack时,机器宕机,导致没有ack成功, Broker的消息重新由unack变为ready,并发送给其他消费者 B:消息消费失败 ...
- mybatis——分页插件PageHelper的使用
项目开发中涉及列表查询时,经常会需要对查询结果进行分页处理:常用的一个插件--PageHelper,是国内非常优秀的一款开源的mybatis分页插件,它支持基本主流与常用的数据库,一致支持mysql. ...
- 1678. 设计 Goal 解析器
1678. 设计 Goal 解析器 class Solution { public String interpret(String command) { char[] ch = command.toC ...
- MySQL清理binlog的正确姿势
本位主要讲述如何正确的清理 MySQL的binlog,里面有哪些坑,注意点有什么. 一. 为什么要清理binlog 如果没有设置MySQL的binlog过期时间或者设置的时间过长, 会 ...
- 关于:js怎么获取元素的自定义属性的问题(原生JavaScript)
最近项目需要把后端传过来的数据隐藏的保存在页面中,方便后边做事件处理时使用.鉴于之前总是在后端处理后的页面中看到元素里除了常见的id.name属性外的data-xxx,就想到:元素的属性必然是可以自定 ...
- MCP协议Streamable HTTP
一.概述 2025 年 3 月 26 日,模型上下文协议(Model Context Protocol,简称 MCP)引入了一项关键更新:用 Streamable HTTP 替代原先的 HTTP + ...
- 【work记录:c++web聊天服务器】解决了聊天窗口的问题|修复了"没有区分好友或者群聊的聊天窗口"的bug|修复了"群聊消息undefined"的bug
日期:2025.4.24 学习内容: 解决了聊天窗口的问题 修复了"没有区分好友或者群聊的聊天窗口"的bug 修复了"群聊消息undefined"的bug 个人 ...
- Vue(五)—Class与style绑定
Vue-Class与style绑定 class.style都属于attribute,所以通过v-bind来绑定 针对class.style属性,v-bind可以通过对象或数组去指定 绑定Html Cl ...