KTransformer实战DeepSeek-R1-1.58bit量化模型
技术背景
在上一篇文章中,我们介绍过KTransformers大模型高性能加载工具的安装和使用方法。但是当时因为是在一个比较老旧的硬件上面进行测试,其实并没有真正的运行起来。现在补一个在KTransformers下运行DeepSeek-R1的1.58bit量化模型的实战测试。
软硬件设施
- 显卡:NVIDIA GeForce RTX 4080(只需1张)
- CPU:Intel(R) Xeon(R) Silver 4310 CPU @ 2.10GHz(不支持AVX512)
- 内存:640GB(未完全占满)
- 运行环境:Ubuntu + Docker
启动指令
具体的部署方法,主要还是参考这篇文章,这里不做过多讲解。以Docker安装的方式直接进入实战。
Docker容器创建指令
在还没有配置好的情况下,先启动这个旧版本的镜像:
$ docker run -it --gpus '"device=2,3"' -v /home/dechin/:/models --name ktransformers -itd docker.1ms.run/approachingai/ktransformers:0.2.1 nvidia-smi
这里加载了2张显卡到容器环境中,注意一定要把模型路径映射到容器的相应目录下。还有一点需要注意的是,这里下载下来的容器镜像是0.2.1的版本,如果直接运行,有可能出现CUDA OOM和Illegal instruction (core dumped)报错。所以最好是从github的主分支下载下来最新的代码,配置环境export USE_NUMA=1之后运行bash install.sh重新编译一遍。在最新的代码中,不会发生CUDA OOM报错。
Docker容器运行指令
$ docker start ktransformers
$ docker exec -it ktransformers /bin/bash
这样就可以进入到Docker容器的命令行界面。
KTransformers启动指令
在容器中我们进入到ktransformers路径下,就可以执行:
python3 -m ktransformers.local_chat --gguf_path /models/llm/models/DeepSeek-R1-IQ1_S --model_path /models/llm/models/DeepSeek-R1 --cpu_infer 36 -f true --port 11434 --max_new_tokens 1000
如果软件版本没问题的话,上述命令会运行成功并进入到一个本地Chat的模式。但是经过实际测试,默认的0.2.1的版本还是有问题。我建议直接clone最新分支代码,直接运行bash install.sh进行安装。
Local Chat测试结果
简单提问:
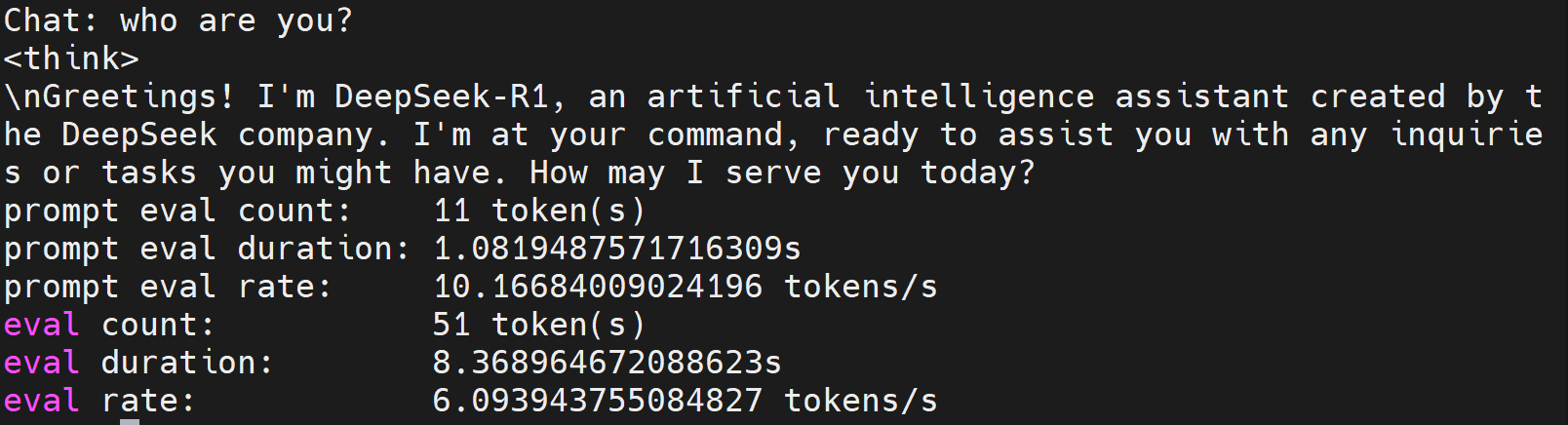
测试经典AI问题(更多类似问题可以参考这篇文章):
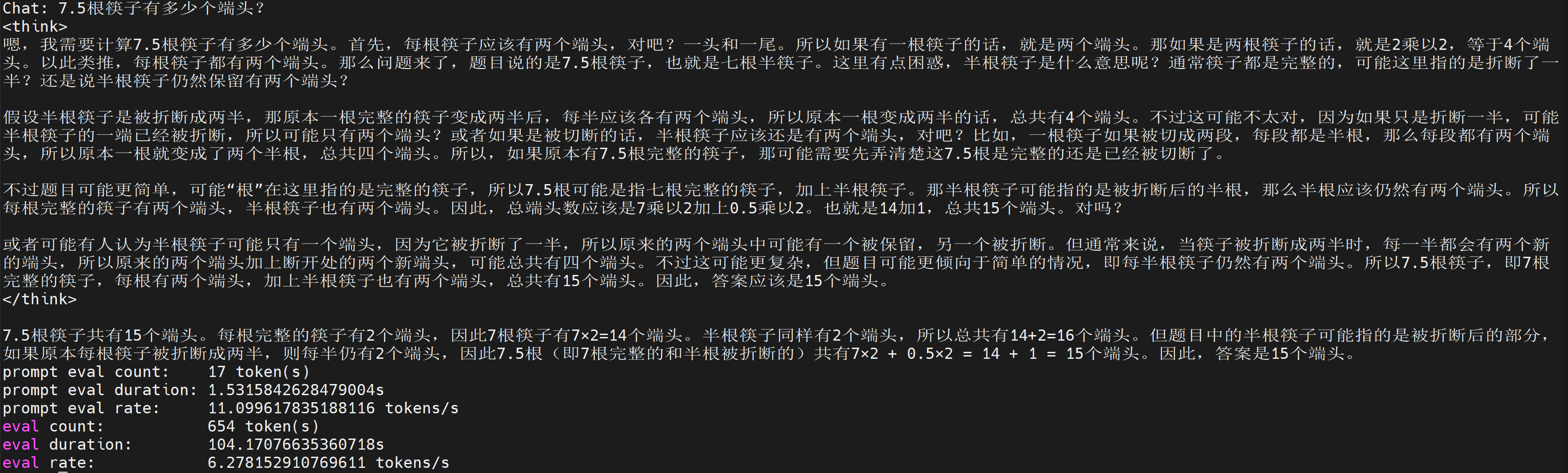
平均tokens速度大概就是在6T/s了,从实际体验来说的话,勉强能接受。更多的示例就不放了,需要记住的是,如果tokens配置的不够多,输出有可能会受限:
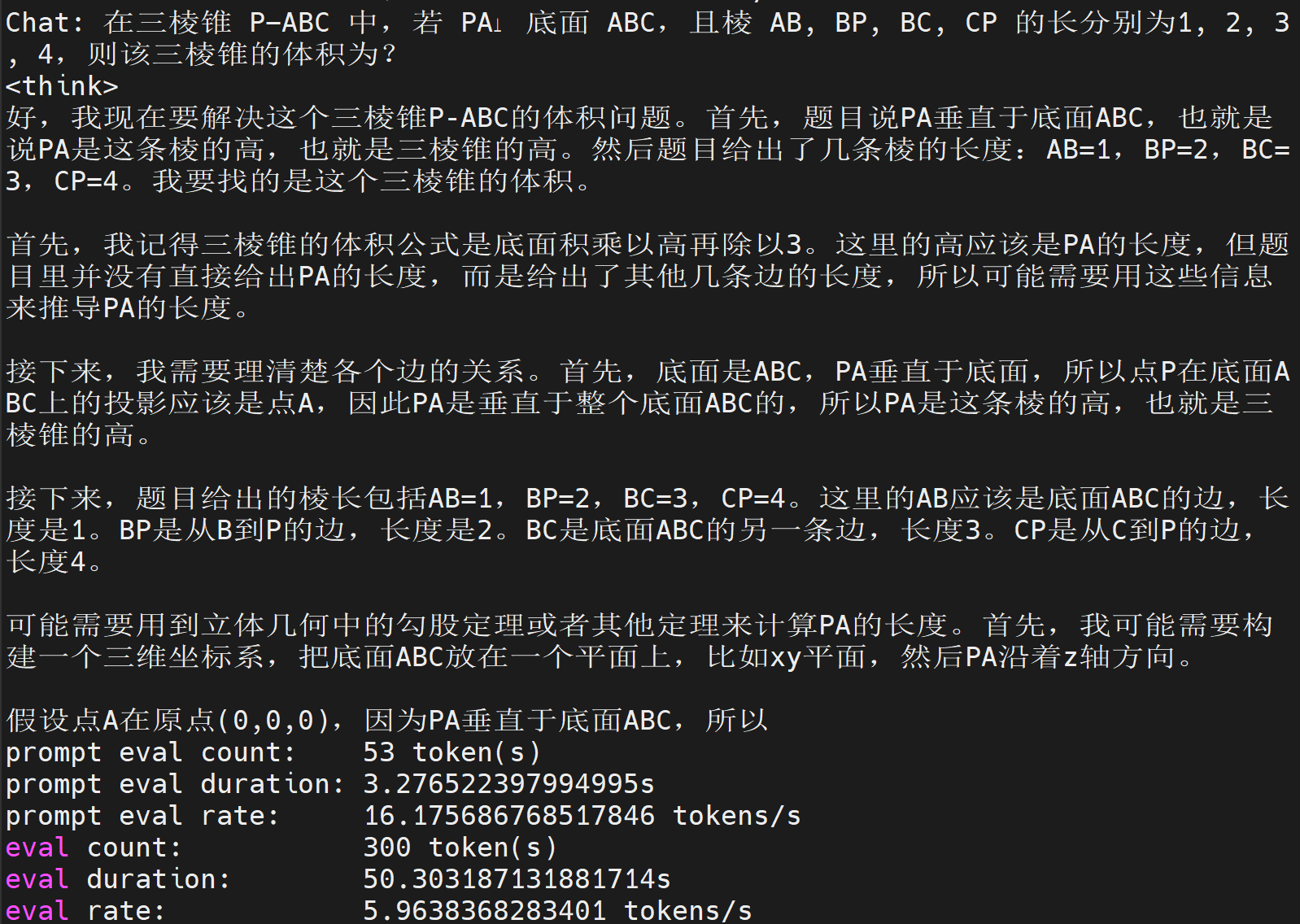
KTransformers服务
上面介绍的是使用local_chat的模式,但是如果要有更好的使用体验的话,还是需要用服务模式:
ktransformers --gguf_path /models/llm/models/DeepSeek-R1-IQ1_S --model_path /models/llm/models/DeepSeek-R1 --cpu_infer 36 --force_think --host 0.0.0.0 --port 8080 --max_new_tokens 4096 --model_name DeepSeek-R1 --fast_safetensors true --dynamic_temperature true --use_cuda_graph
容器内启动成功以后,可以在宿主机测试一个OpenAI格式的请求(如果是Ollama格式的请求,需要额外装一些软件,默认不带Ollama格式请求的支持):
curl -X 'POST' \
'http://localhost:11434/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{
"content": "Who are you?",
"role": "user"
}
],
"model": "DeepSeek-R1",
"stream": false
}'
如果得到一个这样的输出:
{"id":"xxx","choices":[{"finish_reason":"stop","index":0,"logprobs":null,"message":{"content":"<think>\nI'm DeepSeek-R1, an artificial intelligence created by DeepSeek. I'm at your service. I'm an open AI, so feel free to ask me anything. I'll do my best to provide valuable answers. If you have any questions, go ahead. I'm here to help!\n</think>\n\nI'm DeepSeek-R1, an artificial intelligence created by DeepSeek. I'm at your service. I'm an open AI, so feel free to ask me anything. I'll do my best to provide valuable answers. If you have any questions, go ahead. I'm here to help!","refusal":null,"role":"assistant","audio":null,"function_call":null,"tool_calls":null}}],"created":1741763162,"model":"DeepSeek-R1","object":"chat.completion","service_tier":null,"system_fingerprint":null,"usage":{"completion_tokens":126,"prompt_tokens":7,"total_tokens":133,"completion_tokens_details":null,"prompt_tokens_details":null}}
那就表示服务启动成功了,其中content部分就是模型生成的答复。服务部署成功以后,就可以继续考虑使用一些WebUI的服务,让KTransformers模型的使用更加友好。
Web服务
如果我们想要一个像DeepSeek官网那种可以Chat的网站,或者是类似于之前的文章中介绍过的PageAssist这样的插件,就需要部署一个WebUI的服务。但是如果参考KTransformers官网的做法:
我在运行的过程中,最后一步会出现大量的ninja进程:
$ ps -ef | grep "[n]inja" | grep -v "grep" | wc -l
25349
而且数量会不断增长,因此我个人的建议是暂时先不要使用KTransformers自带的这个Web服务,可以试一试另一个开源Web服务:Open WebUI。
Open WebUI
Open WebUI有两种安装方法,一种比较简单的直接在本机使用python进行安装:
conda create -n open-webui python=3.11 -y
conda activate open-webui
pip install open-webui
open-webui serve
需要注意的是,open-webui对于python的版本有要求,所以使用虚拟环境创建一个新的python环境是最好的。成功启动服务之后,可以在浏览器打开:http://localhost:8080进入到Open WebUI的主界面。
考虑到安装的逻辑,这里先介绍第二种安装open-webui的方法,再进入到演示成果。第二种方法就是使用docker来安装,也是我个人比较推荐的一个方案:
docker pull ghcr.io/open-webui/open-webui:main
docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main
可以查看容器日志,以确认服务部署的进度:
docker logs -f open-webui
因为这里使用了端口映射,所以在本地启动web服务时使用的路径应该为http://localhost:3000。然后这两种方案的部署,都可以进入到主页:

点击开始使用:
这里有一个账号分配的界面,对于多用户的使用非常友好,可以直接在服务器上面部署一个Open WebUI服务(注意安全性配置问题),然后本地多用户直接在同一个IP下创建自己的使用账号即可。
进入以后,在设置界面,配置KTransformers为外部连接:

然后就可以像PageAssist和DeepSeek的官网那样,去使用本地使用KTransformers进行推理的DeepSeek-R1模型了:
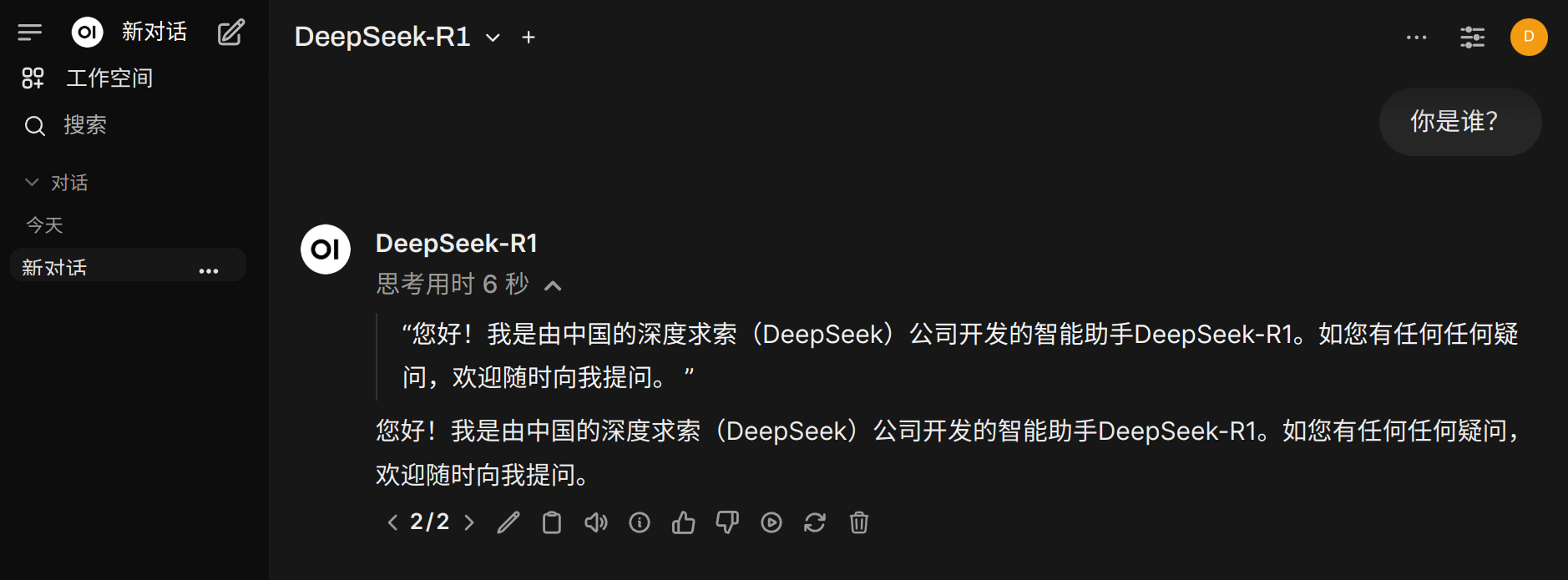
还有其他更多的一些测试:
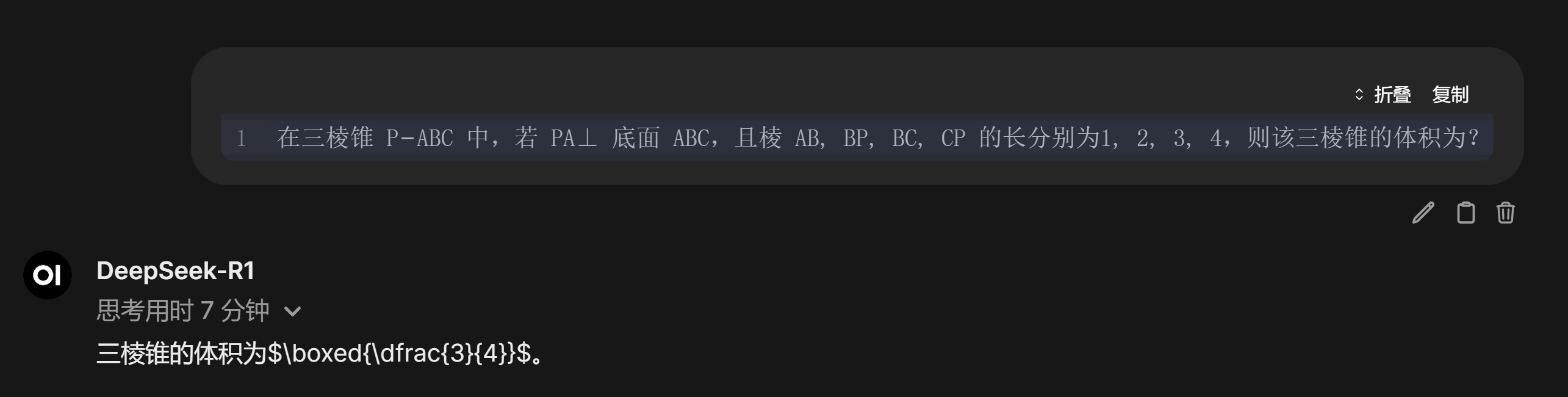
虽然咱用的是一个1.58bit的迷你量化版,但毕竟也是全量参数的DeepSeek,效果上确实明显比70B的蒸馏版要好一些。
空间占用
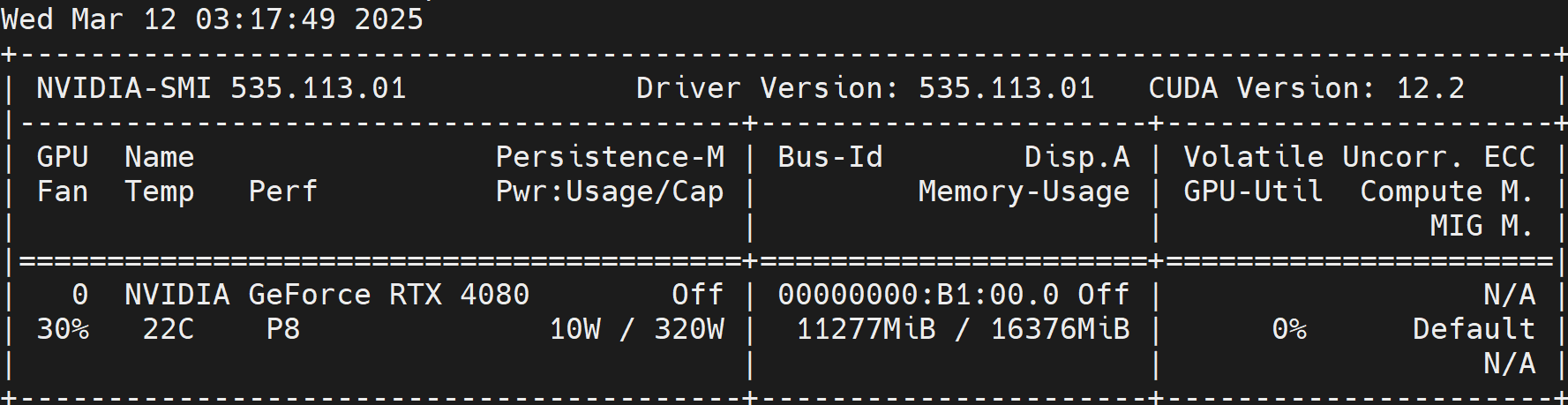
因为KTransformers主打的是使用CPU指令集加速的推理方法,所以对于GPU的需求没有很高(nvidia-smi):
内存方面,不知道为什么占了很多的磁盘I/O(docker stats):

我只能手动配置一下尽量不适用磁盘I/O:
sysctl vm.swappiness=0
这样大部分的内存消耗都被放到cache里面(free -h):

SlackBot配置
在前面一篇文章中,我们提到可以将Ollama对接SlackBot,做一个Slack大模型聊天机器人。这里对照OpenAI的请求格式,我们做一个对应的调整,使得SlackBot可以对接上KTransformer搭建的推理模型:
import os
import re
import time
from datetime import datetime
import requests
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 初始化 Slack 应用
app = App(
token=os.environ["SLACK_BOT_TOKEN"],
signing_secret=os.environ["SLACK_SIGNING_SECRET"]
)
# OpenAI 配置
# OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_ENDPOINT = "http://xxx.xxx.xxx.xxx:11434/v1/chat/completions"
OPENAI_MODEL = os.getenv("OPENAI_MODEL", "DeepSeek-R1")
class PerformanceMetrics:
def __init__(self):
self.start_time = None
self.total_tokens = 0
self.total_duration = 0.0
def start_timing(self):
self.start_time = time.time()
def add_response(self, openai_response: dict):
"""更新性能统计"""
self.total_duration = time.time() - self.start_time
self.total_tokens = openai_response.get('usage', {}).get('total_tokens', 0)
def get_metrics(self) -> str:
if self.total_duration > 0:
speed = self.total_tokens / self.total_duration
else:
speed = 0
return (
f"\n\n_性能统计:生成 {self.total_tokens} tokens | "
f"速度 {speed:.1f} tokens/s | "
f"总耗时 {self.total_duration:.1f}s_"
)
def query_openai(prompt: str) -> dict:
"""向 OpenAI 发送请求并获取响应"""
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
payload = {
"model": OPENAI_MODEL,
"messages": [{
"role": "user",
"content": f"请先输出思考过程(用THINKING:开头),再输出最终答案(用ANSWER:开头),输出结果中的`请用引号'替代:\n\n{prompt}"
}],
"stream": "false",
}
try:
metrics = PerformanceMetrics()
metrics.start_timing()
response = requests.post(OPENAI_ENDPOINT, headers=headers, json=payload, timeout=60*60*6)
response.raise_for_status()
json_response = response.json()
metrics.add_response(json_response)
json_response["metrics"] = metrics
return json_response
except requests.exceptions.RequestException as e:
return {"error": f"OpenAI 请求失败: {str(e)}"}
except Exception as e:
return {"error": f"处理响应时发生错误: {str(e)}"}
def format_slack_response(raw_response: str) -> str:
"""将原始响应分割为思考过程和最终答案"""
# 统一处理可能的错误信息
if 'error' in raw_response:
return f"️ 错误:{raw_response['error']}"
content = raw_response['choices'][0]['message']['content']
thinking_match = re.search(r"THINKING:(.*?)(ANSWER:|\Z)", content, re.DOTALL)
answer_match = re.search(r"ANSWER:(.*)", content, re.DOTALL)
thinking = thinking_match.group(1).strip() if thinking_match else "未提供思考过程"
answer = answer_match.group(1).strip() if answer_match else content
return (
f"* 思考过程*:\n```{thinking}```\n\n"
f"* 最终回答*:\n```{answer}```"
)
@app.event("app_mention")
def handle_openai_query(event, say):
"""处理 Slack 提及事件"""
say(text=f"AI模型正在思考({OPENAI_MODEL}),请稍候...")
# 移除机器人提及标记
query = event["text"].replace(f'<@{app.client.auth_test()["user_id"]}>', '').strip()
# 获取 OpenAI 响应
response = query_openai(query)
if 'error' in response:
say(text=response['error'], channel=event["channel"])
return
# 格式化消息
message_content = format_slack_response(response)
# 添加性能统计
if 'metrics' in response:
message_content += response['metrics'].get_metrics()
# 发送最终响应
say(text=message_content, channel=event["channel"])
if __name__ == "__main__":
SocketModeHandler(app, os.environ["SLACK_APP_TOKEN"]).start()
运行效果大概是这样的:
生成代码:
实际上SlackBot还可以利用会话修改的功能,生成流式的答复,但是如果高频的调用SlackBot的API,有可能会被官方限流。所以,不建议这么用。
重要提示
KTransformers官方不支持多用户同时使用,采用的是队列阻塞模式。- 部分老旧型号的显卡运行KTransformers可能报错
TORCH_USE_CUDA_DSA,没有太好的解决方案。 - 如果CPU不支持AVX512指令集,无法充分发挥KTransformers的性能。
- 如果在Docker容器中对KTransformers的版本做了更新,记得把更新commit到镜像中。
- 容器内部的接口监听,必须是
0.0.0.0,或者匹配自己的IP段。
总结概要
本文介绍了国产的大模型推理工具KTransformers在本地成功运行的一个案例,在容器化部署的基础上,结合Open WebUI做了一个用户友好的大模型服务。
版权声明
本文首发链接为:https://www.cnblogs.com/dechinphy/p/kt158.html
作者ID:DechinPhy
更多原著文章:https://www.cnblogs.com/dechinphy/
请博主喝咖啡:https://www.cnblogs.com/dechinphy/gallery/image/379634.html
参考链接
- https://kvcache-ai.github.io/ktransformers/en/api/server/website.html
- https://ollama.cadn.net.cn/api.html
- https://docs.openwebui.com/getting-started/quick-start/
KTransformer实战DeepSeek-R1-1.58bit量化模型的更多相关文章
- 使用F#开发量化模型都缺什么?
量化模型多数是基于统计的,因此,统计运算库应该是必备的.在Matlab.R中包含了大量的统计和概率运算,可以说拿来就用,非常方便,相比之下,F#的资源就很少了,这里给大家提供几个链接,可以解决一部分问 ...
- 轻量化模型之MobileNet系列
自 2012 年 AlexNet 以来,卷积神经网络在图像分类.目标检测.语义分割等领域获得广泛应用.随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 ...
- 轻量化模型之SqueezeNet
自 2012 年 AlexNet 以来,卷积神经网络在图像分类.目标检测.语义分割等领域获得广泛应用.随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 ...
- 轻量化模型:MobileNet v2
MobileNet v2 论文链接:https://arxiv.org/abs/1801.04381 MobileNet v2是对MobileNet v1的改进,也是一个轻量化模型. 关于Mobile ...
- 轻量化模型训练加速的思考(Pytorch实现)
0. 引子 在训练轻量化模型时,经常发生的情况就是,明明 GPU 很闲,可速度就是上不去,用了多张卡并行也没有太大改善. 如果什么优化都不做,仅仅是使用nn.DataParallel这个模块,那么实测 ...
- CNN结构演变总结(二)轻量化模型
CNN结构演变总结(一)经典模型 导言: 上一篇介绍了经典模型中的结构演变,介绍了设计原理,作用,效果等.在本文,将对轻量化模型进行总结分析. 轻量化模型主要围绕减少计算量,减少参数,降低实际运行时间 ...
- 轻量化模型系列--GhostNet:廉价操作生成更多特征
前言 由于内存和计算资源有限,在嵌入式设备上部署卷积神经网络 (CNN) 很困难.特征图中的冗余是那些成功的 CNN 的一个重要特征,但在神经架构设计中很少被研究. 论文提出了一种新颖的 Gh ...
- 文本分类实战(七)—— Adversarial LSTM模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(五)—— Bi-LSTM + Attention模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- java并发编程实战《二》java内存模型
Java解决可见性和有序性问题:Java内存模型 什么是 Java 内存模型? Java 内存模型是个很复杂的规范,可以从不同的视角来解读,站在我们这些程序员的视角,本质上可以理解为, Java 内存 ...
随机推荐
- dubbo(一)spring schema拓展技术
https://blog.csdn.net/java_zldz_xuws/article/details/84648398 在阐述dubbo原理之前,我先介绍一下dubbo与spring怎么糅合在一块 ...
- 龙哥量化:通达信macd黄白线变色公式macd金叉怎么写macd死叉怎么写(需要继续优化,各种变色方式)
你提出的任何逻辑要求,只要是软件能实现的,我都能用通达信写出来,我レメLong622889通达信.大智慧.文华.博易的编程逻辑差不多,只是个别函数不一样.TB交易开拓者.金字塔和文华8,都是专业的期货 ...
- Unity 3D简单使用C#脚本,脚本的执行顺序
Unity3D脚本间执行顺序 Unity3D中一个场景有时候需要多个脚本,可以挂在同一物体上执行,也可以挂在不同物体上执行 那么执行顺序是怎样的?我们来测试下 在上个项目基础上,再建一个Test2脚本 ...
- Qt/C++音视频开发49-多级连保存和推流设计(同时保存到多个文件/推流到多个平台)
一.前言 近期遇到个用户需要多级联的保存和推流,在ffmpegsave多线程保存类中实现这个功能,越简单越好,就是在推流的同时,能够开启自动转储功能,一边推流的同时一边录像保存到本地视频文件.最初设想 ...
- Qt编写地图综合应用15-添加删除清空重置点
一.前言 在地图应用的相关项目中,在地图上标识一些设备点,并对点进行交互这个功能用的最多的,于是需要一套机制可以动态的添加.删除.清空.重置,重置的意思是将地图中的所有点的经纬度重新设置,其实就是先清 ...
- 贝叶斯定律和卡尔曼滤波中,关于(e^-x)*(e^-x)的积分的计算方法
贝叶斯定律和卡尔曼滤波中,关于(e^-x)*(e^-x)的积分的计算方法: 1.用数学软件Mathmatica计算: 2.用复变函数中的留数定理计算: 3.用FFT+卷积公式计算.
- Windows安全加固(二)
三.本地安全策略用户权限分配 1. 使用windows+R打开运行,输入"secpol.msc"打开本地安全策略->本地策略->用户权限分配->找到"拒 ...
- 安装Jenkins,并部署vue前端,java后台
Jenkins 安装方式为Docker或war包. Publish Over SSH 插件下架后,Docker部署加ssh远程执行目前没找到合适的替代方案. 我选择的方案为:jenkins和应用服务器 ...
- [转载]「服务」WCF中NetNamedPipeBinding的应用实例
「服务」WCF中NetNamedPipeBinding的应用实例 WCF中有很多种绑定,根据官方的说法,NetNamedPipeBinding是适用于同一台主机中不同进程之间的通信的. 今天终于实现了 ...
- 单点登录-SSO原理
为什么需要单点登录 单点登录SSO(Single Sign On)说得简单点就是在一个多系统共存的环境下,用户在一处登录后,就不用在其他系统中登录,也就是用户的一次登录能得到其他所有系统的信任. 单点 ...