转载:大模型所需 GPU 内存笔记
转载文章:大模型所需 GPU 内存笔记
引言
在运行大型模型时,不仅需要考虑计算能力,还需要关注所用内存和 GPU 的适配情况。这不仅影响 GPU 推理大型模型的能力,还决定了在训练集群中总可用的 GPU 内存,从而影响能够训练的模型规模。
大模型推理的内存计算只需考虑模型权重即可。
大模型训练的内存计算往往会考虑包括模型权重、反向传播的梯度、优化器所用的内存、正向传播的激活状态内存。
接下来以ChatGLM-6B为例,它的参数设置为隐藏层神经元数量(hidden_size)为 4096,层数(num_layers)为 28,token 长度为 2048,注意力头数(attention heads)为 32,讲解怎么计算推理内存和训练内存。
推理内存
模型权重
- 对 int8 而言,模型内存 =1 * 参数量 (字节)
- 对 fp16 和 bf16 而言,模型内存=2 * 参数量(字节)
- 对 fp32 而言,模型内存= 4 * 参数量(字节)
因为 1 GB(\(1024^3\)字节) ≈ 1B字节(???),也正好和1B参数量的数据量级一致,估算时就比较简单了。
例如,对于一个ChatGLM-6B而言,就是:
- 对 int8 而言,模型内存=1 * 6GB=6GB
- 对 fp16 和 bf16 而言,模型内存=2 * 6GB=12GB
- 对 fp32 而言,模型内存=4 * 6GB=24GB
推理总内存
除了用于存储模型权重的内存外,在实际的前向传播过程中还会产生一些额外的开销。根据经验,这些额外开销通常控制在总内存的20%以内(只有80%的有效利用率)
因此,推理总内存≈1.2×模型内存。
训练
模型权重
可以使用纯 fp32 或纯 fp16 训练模型:
- 纯 fp32,模型内存=4 * 参数量(字节)
- 纯 fp16,模型内存=2 * 参数量(字节)
除了常规推理中讨论的模型权重数据类型,训练阶段还涉及混合精度训练。
混合精度 $\approx $ 纯fp16
- 混合精度 (fp16/bf16 + fp32), 模型内存=2 * 参数量(字节)
例如,对于一个ChatGLM-6B而言,就是:
- 纯 fp32,模型内存=4 * 6GB=24GB
- 纯 fp16,模型内存=2 * 6GB=12GB
- 混合精度 (fp16/bf16 + fp32), 模型内存=2 * 6GB=12GB
优化器状态
- 对于纯 AdamW,优化器内存=12 * 参数量(字节)
- 对于像 bitsandbytes 这样的 8 位优化器,优化器内存=6 * 参数量(字节)
- 对于含动量的类 SGD 优化器,优化器内存=8 * 参数量(字节)
例如,对于一个ChatGLM-6B而言,就是:
- 对于纯 AdamW,优化器内存=12 * 6GB=72GB
- 对于像 bitsandbytes 这样的 8 位优化器,优化器内存=6 * 6GB=36GB
- 对于含动量的类 SGD 优化器,优化器内存=8 * 48GB=36GB
梯度
梯度可以存储为 fp32 或 fp16 (梯度数据类型通常与模型数据类型匹配。因此在 fp16 混合精度训练中,梯度数据类型为 fp16)
- 对于 fp32,梯度内存=4 * 参数量(字节)
- 对于 fp16,梯度内存=2 * 参数量(字节)
例如,对于一个ChatGLM-6B而言,就是:
- 对于 fp32,梯度内存=4 * 6GB=24GB
- 对于 fp16,梯度内存=2 * 6GB=12GB
激活状态
在进行LLM(大语言模型)训练时,现代GPU通常会遇到内存问题,而不是算力问题。因此,激活重计算(也称为激活检查点)变得非常流行,它是一种以计算力为代价来减少内存使用的方法。激活重计算/检查点的主要思路是重新计算某些层的激活,而不将它们存储在GPU内存中,从而降低内存使用量。具体来说,减少内存的多少取决于我们选择重新计算哪些层的激活。
接下来,假设激活数据类型为 fp16,没有使用序列并行
- 无重计算的激活内存=token 长度 * batch size * hidden layer 的神经元数量 * 层数(10+24/t+5 * a * token 长度/hidden layer 的神经元数 * t) 字节
- 选择性重计算的激活内存=token 长度 * batch size * hidden layer 的神经元数量 * 层数(10+24/t) 字节
- 全部重计算的激活内存=2 * token 长度 * batch size * hidden layer 的神经元数量 * 层数 字节
其中:
- a :transformer 模型中注意力头 (attention heads) 的个数
- t :张量并行度 (如果无张量并行,则为 1)
对于一个ChatGLM-6B而言,就是:
- token 长度 * batch size * hidden layer 的神经元数量 * 层数 = 2048 * 1 * 4096 * 28 ≈ 0.23GB
- 无重计算的激活内存 = 0.23GB * (10+24/1+5 * 32 * 2048/4096 * 1) = 0.23 * 114 = 26.22G
- 选择性重计算的激活内存 = 0.23GB * (10+24/1) = 7.8G
- 全部重计算的激活内存 = 2 * 0.23GB = 0.46GB
由于重计算的引入也会引起计算成本的增加,具体增加多少取决于选择了多少层进行重计算,但其上界为所有层都额外多了一次前向传播,因此,更新后的前向传播计算成本如下:
2 * token数 * 模型参数 ≤ C(前向传播)≤ 4 * token数 * 模型参数
总结
因为训练大模型时通常会采用AdamW优化器,并用混合精度训练来加速训练,所以训练一个ChatGLM-6B所需的训练总内存为:
训练总内存=模型内存+优化器内存+激活内存+梯度内存 = 12GB + 72GB + 12Gb + 7.8GB = 103GB
将以上内容总结为一个简单的类比(非常粗糙的类比):TPUv3-8机器,对标八卡V100-16GB版本的机器;TPUv4-8机器,对标四卡A100-40GB版本的机器。
ChatGLM-6B使用了八台TPU v3-8 机器训练,共使用内存为 128 GB,和我们计算的基本一致。
推理总内存 ≈1.2×模型内存 = 1.2 * 12 GB = 14.4GB
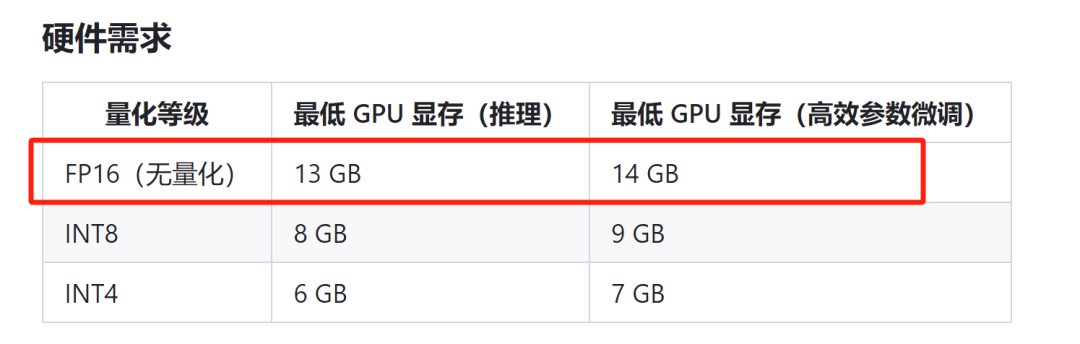
推理总内存的值基本上和ChatGLM-6B官方文档一致。
转载:大模型所需 GPU 内存笔记的更多相关文章
- (转载)CNN 模型所需的计算力(FLOPs)和参数(parameters)数量计算
FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度.是一个衡量硬件性能的指标. FLOPs:注意s小写,是f ...
- PowerDesigner 15学习笔记:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- Tensorflow2对GPU内存的分配策略
一.问题源起 从以下的异常堆栈可以看到是BLAS程序集初始化失败,可以看到是执行MatMul的时候发生的异常,基本可以断定可能数据集太大导致memory不够用了. 2021-08-10 16:38:0 ...
- 千亿参数开源大模型 BLOOM 背后的技术
假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,"一朝看尽长安花"似乎近在眼前 -- 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- java内存模型7-处理器内存模型
处理器内存模型 顺序一致性内存模型是一个理论参考模型,JMM和处理器内存模型在设计时通常会把顺序一致性内存模型作为参照.JMM和处理器内存模型在设计时会对顺序一致性模型做一些放松,因为如果完全按照顺序 ...
- 【转载】 Sqlserver限制最大占用内存
在Sqlserver数据库管理软件中,Sqlserver对系统内存的管理原则是:按需分配,并且分配完成后为了查询有更好的性能,并不会立即自动释放内存,数据取出后,还会一直占用着内存,所以在Sqlser ...
- PowerDesigner 学习:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- OpenCL入门:(三:GPU内存结构和性能优化)
如果我们需要优化kernel程序,我们必须知道一些GPU的底层知识,本文简单介绍一下GPU内存相关和线程调度知识,并且用一个小示例演示如何简单根据内存结构优化. 一.GPU总线寻址和合并内存访问 假设 ...
随机推荐
- 前端性能优化:使用 Web Workers 实现轮询
// pollWorker.js import { Base64 } from 'js-base64'; import RsaAndAes from '~/composables/RsaAndAes' ...
- Visual Studio 快速分析 .NET Dump 文件
前言 在开发和维护 .NET 应用程序的过程中,有时会遇到难以捉摸的性能瓶颈或内存泄漏等问题.这些问题往往发生在生产环境中,难以复现.为了更准确地诊断这些运行时问题,通常会收集应用程序在生产环境中的内 ...
- FreeRTOS LIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY 存在的意义以及高于它的中断不能调用 safe freertos api
This is how I understand it. 我是这样理解的. If we now have 2 tasks and 6 interrupts, among which, and when ...
- Linux下使用谷歌输入法
Linux的中文输入法一直太烂,scim终于出来对googlePinyin的支持了. 安装步骤: 1.安装scim: sudo apt-get install scim 2.从git上checkout ...
- JDBC批处理Select语句
本文由 ImportNew - 刘志军 翻译自 Javaranch.如需转载本文,请先参见文章末尾处的转载要求. 注:为了更好理解本文,请结合原文阅读 在上一篇文章中提到了PreparedStatem ...
- 使用 Antlr 处理文本
高 尚 (gaoshang1999@163.com), 软件工程师, 中国农业银行软件开发中心 简介: Antlr 是一个基于 Java 开发的功能强大的语言识别工具,其主要功能原本是用于识别编程语言 ...
- vue2-路由Router
Vue 中的路由用于实现单页应用(SPA)中的页面导航.它允许你在不刷新整个页面的情况下,根据不同的 URL 路径显示不同的组件,提供了类似于多页面应用的用户体验.例如,在一个电商应用中,可以通过 ...
- highcharts在vue中的应用
1.安装命令 npm install highcharts --save 2.在页面中按需引入 import Highcharts from 'highcharts/highstock'; impor ...
- 深度变分信息瓶颈——Deep Variational Information Bottleneck
Deep Variational Information Bottleneck (VIB) 变分信息瓶颈 论文阅读笔记.本文利用变分推断将信息瓶颈框架适应到深度学习模型中,可视为一种正则化方法. 变分 ...
- 一款可以完整保留排版的PDF翻译,GitHub增长第一
最近看论文较多,顺手给大家推荐一个用下来觉得不错的开源PDF翻译工具:PDFMathTranslate 目前这款开源项目在GitHub上已经收获了7.6K Star,而且由于一直处于增长趋势榜第一的位 ...