scrapy——3 crawlSpider——爱问
scrapy——3 crawlSpider
crawlSpider
- 爬取一般网站常用的爬虫类。其定义了一些规则(rule)来提供跟进link的方便的机制。
- 也许该spider并不是完全适合您的特定网站或项目,但其对很多情况都使用。因此您可以以其为起点,根据需求修改部分方法。当然您也可以实现自己的spider。

- CrawlSpider使用rules来决定爬虫的爬取规则,并将匹配后的url请求提交给引擎。所以在正常情况下,CrawlSpider不需要单独手动返回请求了。
- 在rules中包含一个或多个Rule对象,每个Rule对爬取网站的动作定义了某种特定操作,比如提取当前相应内容里的特定链接,是否对提取的链接跟进爬取,对提交的请求设置回调函数等。
- 如果多个rule匹配了相同的链接,则根据规则在本集合中被定义的顺序,第一个会被使用。


- link_extractor:是一个Link Extractor对象,用于定义需要提取的链接。
- callback: 从link_extractor中每获取到链接时,参数所指定的值作为回调函数,该回调函数接受一个response作为其第一个参数。
- 注意:当编写爬虫规则时,避免使用parse作为回调函数。由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了 parse方法,crawl spider将会运行失败。
- follow:是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback为None,follow 默认设置为True ,否则默认为False。
- process_links:指定该spider中哪个的函数将会被调用,从link_extractor中获取到链接列表时将会调用该函数。该方法主要用来过滤。
- process_request:指定该spider中哪个的函数将会被调用, 该规则提取到每个request时都会调用该函数。 (用来过滤request)


实战 爱问网站数据爬取
我们需要用crawlScrapy的规则匹配出每个问题的链接,对连接内的提问标题,和提问人进行爬取,以及匹配下一页的url
前面讲过scrapy shell ,可以在scrapy shell https://iask.sina.com.cn/c/1073.html 中,先进行匹配测试
先在scrapycrawl中导入LineExtractor再匹配,用extract_links(response)取出数据
In [1]: from scrapy.linkextractors import LinkExtractor In [2]: page = LinkExtractor(allow='/c/1073-all-\d+-new\.html').extract_links(response) # 匹配下一页url In [3]: page
Out[3]:
[Link(url='https://iask.sina.com.cn/c/1073-all-180-new.html', text='', fragment='', nofollow=False),
Link(url='https://iask.sina.com.cn/c/1073-all-191-new.html', text='', fragment='', nofollow=False),
.........
Link(url='https://iask.sina.com.cn/c/1073-all-8608-new.html', text='', fragment='', nofollow=False),
Link(url='https://iask.sina.com.cn/c/1073-all-8618-new.html', text='', fragment='', nofollow=False)] In [4]: page = LinkExtractor(restrict_xpaths='//li[@class="list"]').extract_links(response) # 要获取标题和提问人,需要先找到这个贴的url In [5]: page
Out[5]:
[Link(url='https://iask.sina.com.cn/b/1SXKZurG8ST9.html', text='avg说猎杀潜航3主程序是backdoor.seed', fragment='', nofollow=False),
Link(url='https://iask.sina.com.cn/b/1SWo9FvedMVJ.html', text='怎么去掉关于应用程序错误的提示???', fragment='', nofollow=False),
Link(url='https://iask.sina.com.cn/b/gWP5Ttnm8NDB.html', text='在超声波测距仪的设计中用到了cx20106a,在protel中怎么找不 到啊?', fragment='', nofollow=False),
.......... Link(url='https://iask.sina.com.cn/b/87xMZOVEB3Dr.html', text='景德镇哪家公司做网页设计比较靠谱?有电话吗?', fragment='', nofollow=False),
Link(url='https://iask.sina.com.cn/b/87L5oCMvbsKB.html', text='景德镇有专业的做网页设计的公司吗?', fragment='', nofollow=False)]
方便看的话还可以用.url提取出url
In [7]: page[0].url
Out[7]: 'https://iask.sina.com.cn/b/1SXKZurG8ST9.html' In [8]: page[1].url
Out[8]: 'https://iask.sina.com.cn/b/1SWo9FvedMVJ.html' In [9]: page[2].url
Out[9]: 'https://iask.sina.com.cn/b/gWP5Ttnm8NDB.html'
随便挑一个url继续scrapy shell url解析我们需要的数据
scrapy shell https://iask.sina.com.cn/b/gWP5Ttnm8NDB.html
In [1]: question = response.xpath('//h2[@class="question-title "]/text()').extract_first()
In [2]: question
Out[2]: '在超声波测距仪的设计中用到了cx20106a,在protel中怎么找不到啊?'
In [3]: ask_people = response.xpath('//span[@class="user-name"]/text()').extract_first()
In [4]: ask_people
Out[4]: '距离会产生美只有时间不要太长'
准备完毕就可以开始写代码了
- 先创建项目
- 注意:crawl spider 创建项目方法略有不同 Scrapy genspider –t crawl “spider_name”“url”
- IAsk\items.py 确定需要的数据
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class IaskItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
question_title = scrapy.Field()
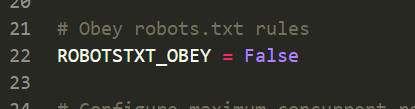
ask_name = scrapy.Field() - IAsk\settings.py 激活管道,以及设置忽略爬虫协议(有些网站会设置爬虫协议,礼貌式反爬,可无视)

- IAsk\spiders\iask.py 编写代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule from ..items import IaskItem class IaskSpider(CrawlSpider):
name = 'iask'
allowed_domains = ['iask.sina.com.cn']
start_urls = ['https://iask.sina.com.cn/c/1073.html'] rules = (
Rule(LinkExtractor(allow='/c/1073-all-\d+-new\.html'), callback='parse_item', follow=True), # 设置规则匹配下一页url,无需跳转方法,此处只是打印出来看
Rule(LinkExtractor(restrict_xpaths='//li[@class="list"]'), callback='parse_item1', follow=True), # 设置匹配每一个贴的url,再跳转匹配问题和提问人
) def parse_item(self, response):
print(response.url,) def parse_item1(self, response):
ask_item = IaskItem() # 创建管道对象
ask_item['question_title'] = response.xpath('//h2[@class="question-title "]/text()').extract_first()
ask_item['ask_name'] = response.xpath('//span[@class="user-name"]/text()').extract_first()
yield ask_item # 将数据以字典形式传给管道 - IAsk\pipelines.py 在保存数据,json格式
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class IaskPipeline(object):
def __init__(self):
self.f = open('ask.json', 'w', encoding='utf-8') def start_spider(self):
pass def process_item(self, item, spider):
s = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.f.write(s)
return item def close_spider(self):
self.f.close() - 在scrapy——2中,实战介绍的是scrapy spider 的实现方法,点此查看, 这里展示crawl spider的方法,做个对比
scrapy——3 crawlSpider——爱问的更多相关文章
- VC 最爱问的问题:你这个创业项目,如果腾讯跟进了,而且几乎是产品上完全复制,你会怎么办?
VC 最爱问的问题:你这个创业项目,如果腾讯跟进了,而且几乎是产品上完全复制,你会怎么办? http://www.zhihu.com/question/19607233 朱继玉,独立精神,自由思想. ...
- 芝麻HTTP:Python爬虫实战之抓取爱问知识人问题并保存至数据库
本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表达式的简 ...
- python爬虫之Scrapy框架(CrawlSpider)
提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpi ...
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
- Java面试官最爱问的volatile关键字
在Java的面试当中,面试官最爱问的就是volatile关键字相关的问题.经过多次面试之后,你是否思考过,为什么他们那么爱问volatile关键字相关的问题?而对于你,如果作为面试官,是否也会考虑采用 ...
- 大厂面试官竟然这么爱问Kafka,一连八个Kafka问题把我问蒙了?
本文首发于公众号:五分钟学大数据 在面试的时候,发现很多面试官特别爱问Kafka相关的问题,这也不难理解,谁让Kafka是大数据领域中消息队列的唯一王者,单机十万级别的吞吐量,毫秒级别的延迟,这种天生 ...
- Scrapy框架-CrawlSpider
目录 1.CrawlSpider介绍 2.CrawlSpider源代码 3. LinkExtractors:提取Response中的链接 4. Rules 5.重写Tencent爬虫 6. Spide ...
- scrapy 中crawlspider 爬虫
爬取目标网站: http://www.chinanews.com/rss/rss_2.html 获取url后进入另一个页面进行数据提取 检查网页: 爬虫该页数据的逻辑: Crawlspider爬虫类: ...
- Scrapy 框架 CrawlSpider 全站数据爬取
CrawlSpider 全站数据爬取 创建 crawlSpider 爬虫文件 scrapy genspider -t crawl chouti www.xxx.com import scrapy fr ...
随机推荐
- 杂项-Java:JMX
ylbtech-杂项-Java:JMX 1.返回顶部 1. JMX(Java Management Extensions,即Java管理扩展)是一个为应用程序.设备.系统等植入管理功能的框架.JMX可 ...
- codeforces round #416 div2
A:暴力模拟 #include<bits/stdc++.h> using namespace std; int a, b; int main() { scanf("%d%d&qu ...
- PCB Winform使用谷歌webkit内核 应用
我们Winfrom界面嵌入网页最常用的是WebBrowser控件,因为微软自带的,使用方便,但在实际使用起来,会遇到各种麻烦(JS,不兼容问题,渲染等问题) 而实际WebBrowser控件内核是微软的 ...
- js返回上一层
Javascript 返回上一页 1. Javascript 返回上一页 history.go(-1), 返回两个页面: history.go(-2); 2. history.back(). wind ...
- HDU 3007 最小圆覆盖 计算几何
思路: 随机增量法 (好吧这数据范围并不用) //By SiriusRen #include <cmath> #include <cstdio> #include <al ...
- django 菜单权限
一.什么是权限 能做哪些事情,不能做哪些事情,可以做的权限 二.设计权限 思路: web应用中,所谓的权限,其实就是一个用户能够访问的url,通过对用户访问的url进行控制,从而实现对用户权限的控制. ...
- ACM_最值差(线段树区间查询最值)
最值差 Time Limit: 2000/1000ms (Java/Others) Problem Description: 给定N个数A1A2A3A4...AN.求任意区间Ai到Aj中的最大数与最小 ...
- 为什么选择Android Studio 而是 Eclipse
Android Studio 现在的版本已经比较稳定了,刚出来时也是各种BUG,自己用了下,摸索了一天,感觉挺好的. 优点之一:代码提示和搜索功能非常强大,非常智能. 1).自定义theme有个名字叫 ...
- SVN系列学习(一)-SVN的安装与配置
1.SVN的介绍 SVN是Subversion的简称,是一个开发源代码的版本控制系统,采用了分支管理系统. 文件保存在中央版本库,除了能记住文件和目录的每次修改以外,版本库非常像普通的文件服务器.你可 ...
- Miller Rabin 大素数测试
PS:本人第一次写随笔,写的不好请见谅. 接触MillerRabin算法大概是一年前,看到这个算法首先得为它的神奇之处大为赞叹,竟然可以通过几次随机数据的猜测就能判断出这数是否是素数,虽然说是有误差率 ...