scrapy 中crawlspider 爬虫
爬取目标网站:
http://www.chinanews.com/rss/rss_2.html
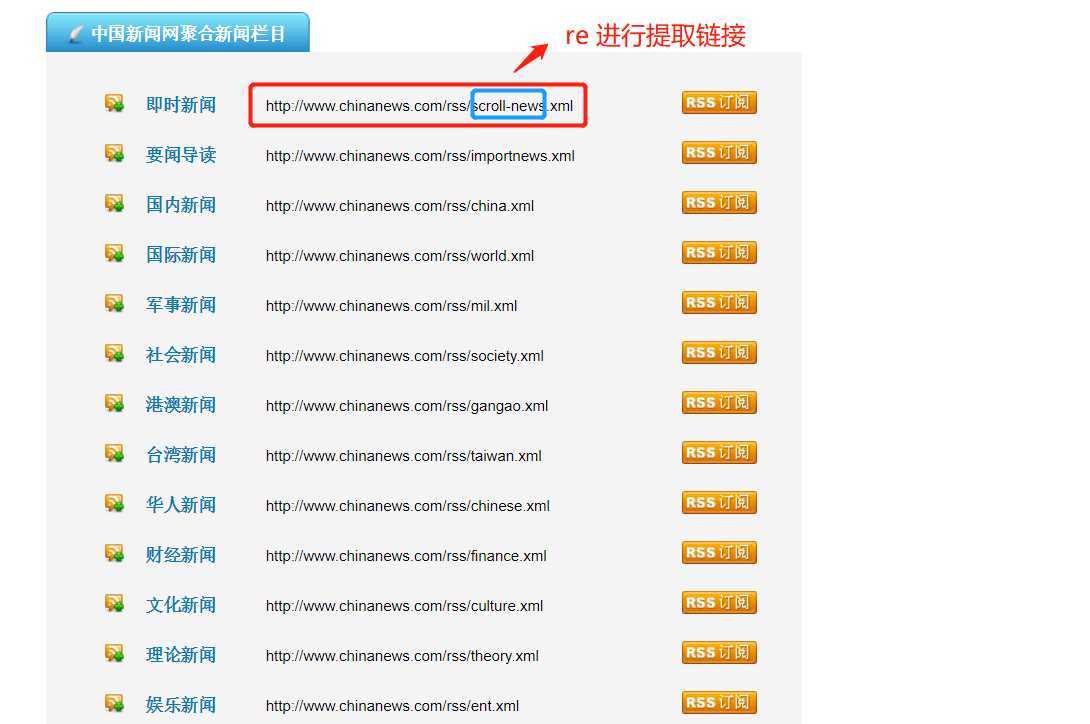
获取url后进入另一个页面进行数据提取

检查网页:
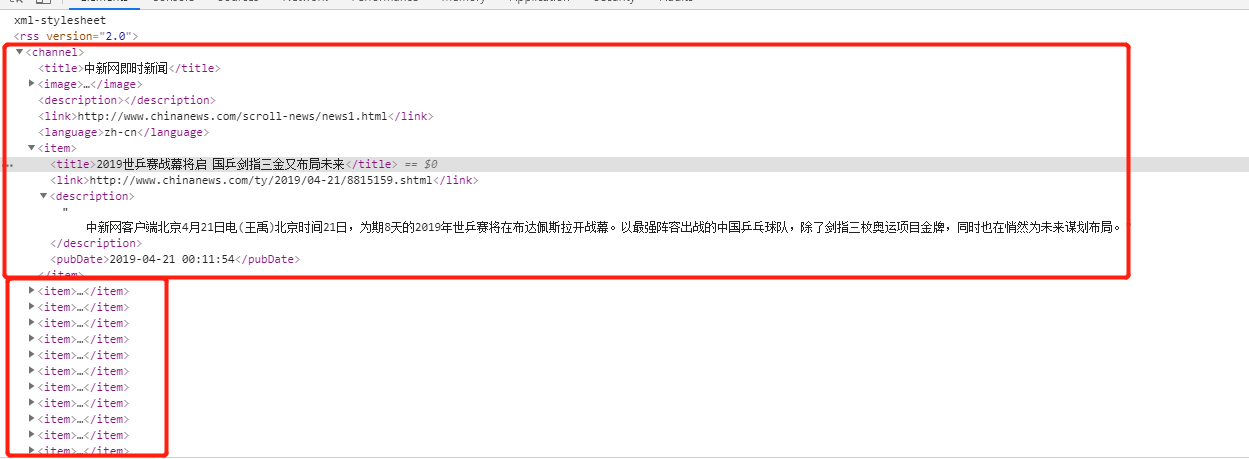
爬虫该页数据的逻辑:
Crawlspider爬虫类:
# -*- coding: utf-8 -*-
import scrapy
import re
#from scrapy import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule class NwSpider(CrawlSpider):
name = 'nw'
# allowed_domains = ['www.new.com']
start_urls = ['http://www.chinanews.com/rss/rss_2.html'] rules = (
Rule(LinkExtractor(allow='http://www.chinanews.com/rss/.*?\.xml'), callback='parse_item'),
) def parse_item(self, response):
selector = Selector(response)
items =response.xpath('//item').extract()
for node in items:
# print(type(node))
#
item = {}
item['title'] = re.findall(r'<title>(.*?)</title>',node,re.S)[0]
item['link'] = re.findall(r'<link>(.*?)</link>',node,re.S)[0]
item['desc'] = re.findall(r'<description>(.*?)</description>',node,re.S)[0]
item['pub_date'] =re.findall(r'<pubDate>(.*?)</pubDate>',node,re.S)[0]
print(item)
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get() #item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
# yield item
scrapy 中crawlspider 爬虫的更多相关文章
- python框架Scrapy中crawlSpider的使用——爬取内容写进MySQL
一.先在MySQL中创建test数据库,和相应的site数据表 二.创建Scrapy工程 #scrapy startproject 工程名 scrapy startproject demo4 三.进入 ...
- python框架Scrapy中crawlSpider的使用
一.创建Scrapy工程 #scrapy startproject 工程名 scrapy startproject demo3 二.进入工程目录,根据爬虫模板生成爬虫文件 #scrapy genspi ...
- scrapy中运行爬虫时出现twisted critical unhandled error错误
1. 试试这条命令: twisted critical unhandled error on scrapy tutorial python python27\scripts\pywin32_posti ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- Scrapy - CrawlSpider爬虫
crawlSpider 爬虫 思路: 从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数. 1. 创建项目 scrapy startproject mysp ...
- python爬虫之Scrapy框架(CrawlSpider)
提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpi ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
- 爬虫开发12.selenium在scrapy中的应用
selenium在scrapy中的应用阅读量: 370 1 引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝 ...
随机推荐
- bfs经典
题意:地图上分别用‘.’表示硬地,‘#’表示禁地,‘E’表示易碎地面.你的任务操作一个1*1*2的长方体.长方体有两种状态分别为:立在地面上,躺在地面上.把长方体从入口移动到出口,求需要的最小步数. ...
- windows10误删Administrator用户的家目录之后
今天在玩Windows10的用户管理的时候,把Administrator用户给开启了,然后还用这个用户登录了系统. 结果就是,第一次登录的时候,闪过一条条初始化配置欢迎信息,Windows系统为Adm ...
- Centos7 update dotnet 无法识别
使用了yum update 后 原来好好的dotnet 用不了了 /usr/bin/dotnet 找不到 卸载重装都没法了.... 解决方法: 把dotnet 拷贝到 /usr/bin 下面去就好了 ...
- PureMVC 官方文档翻译(一)
最近在学习PureMVC框架,感觉最权威的还是阅读官方文档,顺便翻译了下全当记笔记了. PureMVC概览 这篇文档他讨论PureMVC框架的类和接口,使用UML来阐述它们的角色.职责和协作. Pur ...
- uva 10123 - No Tipping dp 记忆化搜索
这题的题意是 在双脚天平上有N块东西,依次从上面取走一些,最后使得这个天平保持平衡! 解题: 逆着来依次放入,如果可行那就可以,记得得有木板自身的重量. /********************** ...
- HTTP笔记1
传输层:提供进程地址 TCP:传输控制协议,面向连接的协议:通信前需要建立虚拟链路:结束后拆除链路.端口号:0-65535 UDP:用户报文协议,无连接的协议.端口号:0-65535 IANA(互联网 ...
- 【JavaScript】JS知识点复习
1.引入的两种方式:直接在标签里行内js,在body最下端引入. 2.变量的5种类型:number,string,boolean,null,undefined以及一种特殊类型:object 3.变量命 ...
- js 对url进行某个参数的删除,并返回url
两种情况 1对当前页面的url进行操作 function funcUrlDel(name){ var loca = window.location; var baseUrl = loca.origin ...
- php 把数组保存为标准的数组格式,存储到文件中
<?php $file='./test.php'; $array=array('color'=> array('blue','red','green'),'size'=> array ...
- Kafka启动报错 : ERROR Processor got uncaught exception
参照我之前的一篇博文Kafka学习之(二)Centos下安装Kafka安装了kafka并启动,状况并不像我之前最初的预期,报错了,并且我在当前Linux环境下安装的Java版本.Kafka版本都是和之 ...