10.shard、replica机制及单node下创建index
主要知识点
1、shard&replica机制梳理
2、单node环境下创建index的情况
1、shard&replica机制再次梳理
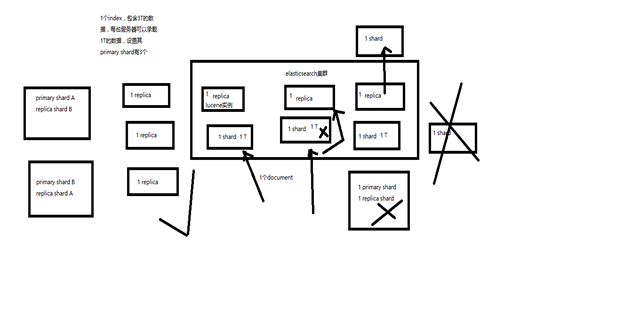
(1)index包含多个shard,也就是说,如果一个index有3T的数据,每个服务器都是1T的容量,es会把这个index自动分配到3个shard上。
(2)每个shard都是一个最小工作单元,承载部分数据,每个shrard都是一个lucene实例,都有完整的建立索引和处理请求的能力
(3)增减节点时,shard会自动在nodes中负载均衡
(4)shard分两种:primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard中。
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载。
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
(7)primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard,在创建index 时primary shard已定义,定义之后就不能更改。replica shard 可以更改。
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
2、单node环境下创建index的情况
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard
(2)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的,集群状态status是yellow.
(3)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
设置语法:
PUT /test_index
{
"settings" : {
"number_of_shards" : 3, # 3个primary shard
"number_of_replicas" : 1 # 每个primary shard的replica shard 为1,这样就有3个primary shard.
}
}
10.shard、replica机制及单node下创建index的更多相关文章
- Elasticsearch技术解析与实战--shard&replica机制
序言 1.shard&replica机制 (1)index包含多个shard (2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力 (3)增 ...
- Elasticsearch技术解析与实战(四)shard&replica机制
序言 shard&replica机制 1.index包含多个shard 2.每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力 3.增减节点时, ...
- elasticsearch:shard 和 replica 机制
shard 和 replica 机制: index包含多个shard 每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力 增减节点时,shard会自动在 ...
- Elasticsearch 模块 - Shard Allocation 机制
原文 1. 背景 shard allocation 意思是分片分配, 是一个将分片分配到节点的过程; 可能发生该操作的过程包括: 初始恢复(initial recovery) 副本分配(replica ...
- solr的collection,shard,replica,core概念
一.collection 1.由多个cores组成一个逻辑索引叫做一个collection.一个collection本质上是一个可以跨越多个核的索引,同时包含冗余索引. 2.collection由不同 ...
- MongoDBV3.0.7版本(shard+replica)集群的搭建及验证
集群的模块介绍: 从MongoDB官方给的集群架构了解,整个集群主要有4个模块:Config Server.mongs. shard.replica set: Config Server:用来存放集群 ...
- 05_Elasticsearch 单模式下API的增删改查操作
05_Elasticsearch 单模式下API的增删改查操作 安装marvel 插件: zjtest7-redis:/usr/local/elasticsearch-2.3.4# bin/plugi ...
- Elasticsearch 单模式下API的增删改查操作
<pre name="code" class="html">Elasticsearch 单模式下API的增删改查操作 http://192.168. ...
- windows单节点下安装es集群
linux下的es的tar包,拖到windows下,配置后,启动bin目录下的bat文件,也是可以正常运行的. 从linux下拷的tar包,需要修改虚拟机的内存elasticsearch.in.bat ...
随机推荐
- Zend_Form 创建、校验和解析表单的基础--(手冊)
1. 创建表单对象 创建表单对象很easy:仅仅要实现 Zend_Form: <?php $form = newZend_Form; ? > 对于高级用例.须要创建 Zend_Form ...
- 在CentOS 6 中安装 Apache,Mysql, PHP
1.安装Apache 在终端中输入以下的命令就能够安装Apache了: sudo yum install httpd sudo的意思是用root用户做什么操作.要点击y就确认下载安装了,非常方便. 然 ...
- PHP中JSON的应用
文章来源:PHP开发学习门户 地址: http://www.phpthinking.com/archives/513 互联网的今天,AJAX已经不是什么陌生的词汇了.说起AJAX,可能会马上想起因R ...
- 小米手机 js 脚本取src为空的适配问题
今天測试提上来一个问题 我android webview 中运行了一段js脚本.去替换原来的图片.可是小米手机上竟然没起作用 花了一个中午的午休看问题 贴出来帮助下遇到相同的问题的朋友吧.我百度了半天 ...
- java的死锁学习
学习java的死锁写的代码 也是看书上的然后自己敲了一个 <span style="font-size:18px;">package synchronization.j ...
- Parallel in C#
https://docs.microsoft.com/en-us/dotnet/standard/parallel-programming/how-to-write-a-simple-parallel ...
- 从vs中删除自带的Microsoft Git Provider
https://researchaholic.com/2015/02/02/remove-the-microsoft-gitprovider-from-visual-studio-2013/ vs自带 ...
- Python 下的数据结构实现
既然采用了 Python 编程语言实现数据结构,就要充分发挥 Python 语言的语法特性. 参考<Python 算法教程><数据结构与算法 -- Python 语言描述>: ...
- Redis的事务讲解
1. Redis事务的概念 是什么: 可以一次执行多个命令,本质是一组命令的集合.一个事务中的所有命令都会序列化,按顺序串行化的执行而不会被其他命令插入 能干嘛:一个队列中,一次性.顺序性.排他性的执 ...
- php 过滤敏感关键词
php 过滤敏感关键词 function badwords($content){ $keywords=M("config")->where("name='badwo ...