虚拟DOM介绍
【转自】:https://www.jianshu.com/p/616999666920
为什么需要虚拟DOM
先介绍浏览器加载一个HTML文件需要做哪些事,帮助我们理解为什么我们需要虚拟DOM。webkit引擎的处理流程,一图胜千言:
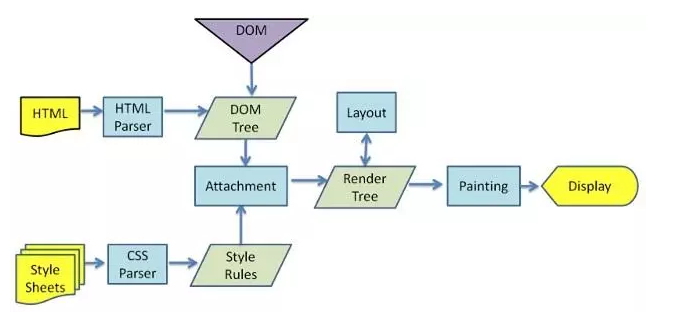
所有浏览器的引擎工作流程都差不多,如上图大致分5步:创建DOM tree –> 创建Style Rules -> 构建Render tree -> 布局Layout –> 绘制Painting
第一步,用HTML分析器,分析HTML元素,构建一颗DOM树。
第二步:用CSS分析器,分析CSS文件和元素上的inline样式,生成页面的样式表。
第三步:将上面的DOM树和样式表,关联起来,构建一颗Render树。这一过程又称为Attachment。每个DOM节点都有attach方法,接受样式信息,返回一个render对象(又名renderer)。这些render对象最终会被构建成一颗Render树。
第四步:有了Render树后,浏览器开始布局,会为每个Render树上的节点确定一个在显示屏上出现的精确坐标值。
第五步:Render数有了,节点显示的位置坐标也有了,最后就是调用每个节点的paint方法,让它们显示出来。
当你用传统的源生api或jQuery去操作DOM时,浏览器会从构建DOM树开始从头到尾执行一遍流程。比如当你在一次操作时,需要更新10个DOM节点,理想状态是一次性构建完DOM树,再执行后续操作。但浏览器没这么智能,收到第一个更新DOM请求后,并不知道后续还有9次更新操作,因此会马上执行流程,最终执行10次流程。显然例如计算DOM节点的坐标值等都是白白浪费性能,可能这次计算完,紧接着的下一个DOM更新请求,这个节点的坐标值就变了,前面的一次计算是无用功。
即使计算机硬件一直在更新迭代,操作DOM的代价仍旧是昂贵的,频繁操作还是会出现页面卡顿,影响用户的体验。真实的DOM节点,哪怕一个最简单的div也包含着很多属性,可以打印出来直观感受一下:

实现虚拟DOM
我们来实现一个虚拟DOM。例如一个真实的DOM节点:代码见仓库里的src/firstStep
<div id="real-container">
<p>Real DOM</p>
<div>cannot update</div>
<ul>
<li className="item">Item 1</li>
<li className="item">Item 2</li>
<li className="item">Item 3</li>
</ul>
</div>
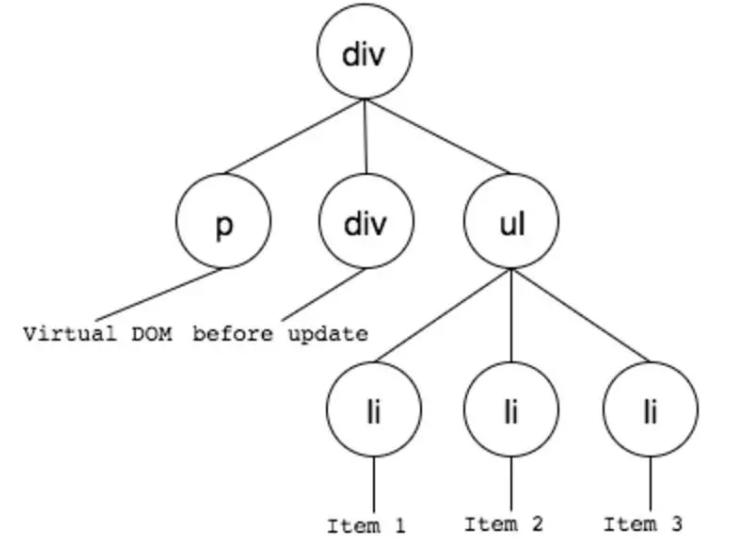
用js对象来模拟DOM节点如下:
const tree = Element('div', { id: 'virtual-container' }, [
Element('p', {}, ['Virtual DOM']),
Element('div', {}, ['before update']),
Element('ul', {}, [
Element('li', { class: 'item' }, ['Item 1']),
Element('li', { class: 'item' }, ['Item 2']),
Element('li', { class: 'item' }, ['Item 3']),
]),
]);
const root = tree.render();
document.getElementById('virtualDom').appendChild(root);
用js对象模拟DOM节点的好处是,页面的更新可以先全部反映在js对象上,操作内存中的js对象的速度显然要快多了。等更新完后,再将最终的js对象映射成真实的DOM,交由浏览器去绘制。
那具体怎么实现呢?看一下Element方法的具体实现:
function Element(tagName, props, children) {
if (!(this instanceof Element)) {
return new Element(tagName, props, children);
}
this.tagName = tagName;
this.props = props || {};
this.children = children || [];
this.key = props ? props.key : undefined;
let count = 0;
this.children.forEach((child) => {
if (child instanceof Element) {
count += child.count;
}
count++;
});
this.count = count;
}
第一个参数是节点名(如div),第二个参数是节点的属性(如class),第三个参数是子节点(如ul的li)。除了这三个参数会被保存在对象上外,还保存了key和count。
有了js对象后,最终还需要将其映射成真实的DOM:
Element.prototype.render = function() {
const el = document.createElement(this.tagName);
const props = this.props;
for (const propName in props) {
setAttr(el, propName, props[propName]);
}
this.children.forEach((child) => {
const childEl = (child instanceof Element) ? child.render() : document.createTextNode(child);
el.appendChild(childEl);
});
return el;
};
上面都是自解释代码,根据DOM名调用源生的createElement创建真实DOM,将DOM的属性全都加到这个DOM元素上,如果有子元素继续递归调用创建子元素,并appendChild挂到该DOM元素上。这样就完成了从创建虚拟DOM到将其映射成真实DOM的全部工作。
Diff算法
我们已经完成了创建虚拟DOM并将其映射成真实DOM的工作,这样所有的更新都可以先反映到虚拟DOM上,如何反映呢?需要明确一下Diff算法。
两棵树如果完全比较时间复杂度是O(n^3),但参照《深入浅出React和Redux》一书中的介绍,React的Diff算法的时间复杂度是O(n)。要实现这么低的时间复杂度,意味着只能平层地比较两棵树的节点,放弃了深度遍历。这样做,似乎牺牲了一定的精确性来换取速度,但考虑到现实中前端页面通常也不会跨层级移动DOM元素,所以这样做是最优的。
我们新创建一棵树,用于和之前的树进行比较,代码见仓库里的src/secondStep:
const newTree = Element('div', { id: 'virtual-container' }, [
Element('h3', {}, ['Virtual DOM']), // REPLACE
Element('div', {}, ['after update']), // TEXT
Element('ul', { class: 'marginLeft10' }, [ // PROPS
Element('li', { class: 'item' }, ['Item 1']),
// Element('li', { class: 'item' }, ['Item 2']), // REORDER remove
Element('li', { class: 'item' }, ['Item 3']),
]),
]);
只考虑平层地Diff的话,就简单多了,只需要考虑以下4种情况:
第一种是最简单的,节点类型变了,例如下图中的P变成了h3。我们将这个过程称之为REPLACE。直接将旧节点卸载(componentWillUnmount)并装载新节点(componentWillMount)就行了。
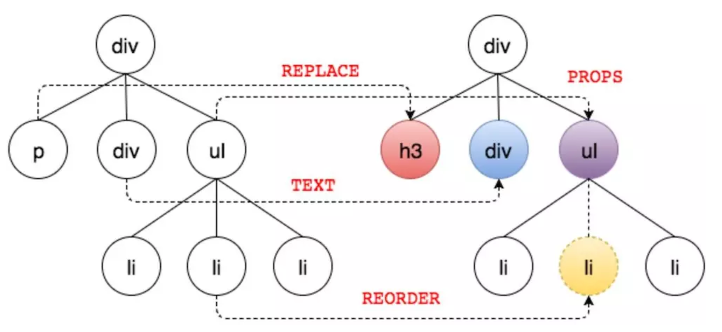
(为简单起见上图隐藏了文本节点)
旧节点包括下面的子节点都将被卸载,如果新节点和旧节点仅仅是类型不同,但下面的所有子节点都一样时,这样做显得效率不高。但为了避免O(n^3)的时间复杂度,这样做是值得的。这也提醒了React开发者,应该避免无谓的节点类型的变化,例如运行时将div变成p就没什么太大意义。
第二种也比较简单,节点类型一样,仅仅属性或属性值变了。
renderA: <ul>
renderB: <ul class: 'marginLeft10'>
=> [addAttribute class "marginLeft10"]
我们将这个过程称之为PROPS。此时不会触发节点的卸载(componentWillUnmount)和装载(componentWillMount)动作。而是执行节点更新(shouldComponentUpdate到componentDidUpdate的一系列方法)。
function diffProps(oldNode, newNode) {
const oldProps = oldNode.props;
const newProps = newNode.props;
let key;
const propsPatches = {};
let isSame = true;
// find out different props
for (key in oldProps) {
if (newProps[key] !== oldProps[key]) {
isSame = false;
propsPatches[key] = newProps[key];
}
}
// find out new props
for (key in newProps) {
if (!oldProps.hasOwnProperty(key)) {
isSame = false;
propsPatches[key] = newProps[key];
}
}
return isSame ? null : propsPatches;
}
第三种是文本变了,文本对也是一个Text Node,也比较简单,直接修改文字内容就行了,我们将这个过程称之为TEXT。
第四种是移动,增加,删除子节点,我们将这个过程称之为REORDER。具体可以看这篇虚拟DOM Diff算法解析。例如:
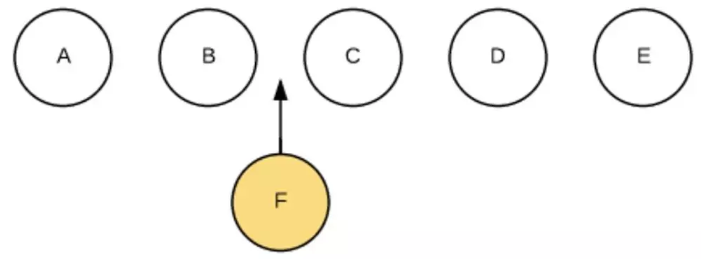
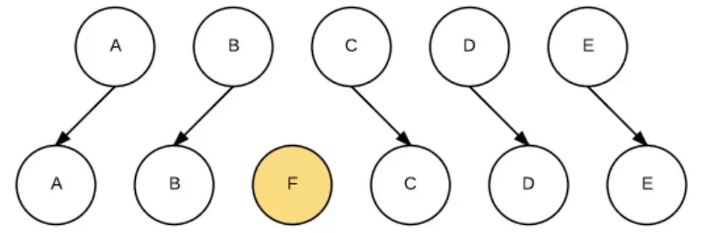
在中间插入一个节点,程序员写代码很简单:$(B).after(F)。但如何高效地插入呢?简单粗暴的做法是:卸载C,装载F,卸载D,装载C,卸载E,装载D,装载E。如下图:

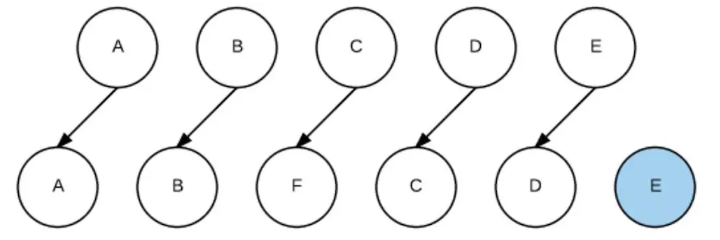
如果我们在JSX里为数组或枚举型元素增加上key后,React就能根据key,直接找到具体的位置进行操作,效率比较高。如下图:
{
1: [ {type: REPLACE, node: Element} ],
4: [ {type: TEXT, content: "after update"} ],
5: [ {type: PROPS, props: {class: "marginLeft10"}}, {type: REORDER, moves: [{index: 2, type: 0}]} ],
6: [ {type: REORDER, moves: [{index: 2, type: 0}]} ],
8: [ {type: REORDER, moves: [{index: 2, type: 0}]} ],
9: [ {type: TEXT, content: "Item 3"} ],
}
映射成真实DOM
虚拟DOM有了,Diff也有了,现在就可以将Diff应用到真实DOM上了。代码见仓库里的src/thirdStep
深度遍历DOM将Diff的内容更新进去:
function dfsWalk(node, walker, patches) {
const currentPatches = patches[walker.index];
const len = node.childNodes ? node.childNodes.length : 0;
for (let i = 0; i < len; i++) {
walker.index++;
dfsWalk(node.childNodes[i], walker, patches);
}
if (currentPatches) {
applyPatches(node, currentPatches);
}
}
具体更新的代码如下,其实就是根据Diff信息调用源生API操作DOM:
function applyPatches(node, currentPatches) {
currentPatches.forEach((currentPatch) => {
switch (currentPatch.type) {
case REPLACE: {
const newNode = (typeof currentPatch.node === 'string')
? document.createTextNode(currentPatch.node)
: currentPatch.node.render();
node.parentNode.replaceChild(newNode, node);
break;
}
case REORDER:
reorderChildren(node, currentPatch.moves);
break;
case PROPS:
setProps(node, currentPatch.props);
break;
case TEXT:
if (node.textContent) {
node.textContent = currentPatch.content;
} else {
// ie
node.nodeValue = currentPatch.content;
}
break;
default:
throw new Error(`Unknown patch type ${currentPatch.type}`);
}
});
}
虚拟DOM的目的是将所有操作累加起来,统计计算出所有的变化后,统一更新一次DOM。其实即使不懂原理,业务代码照样写,但理解原理后,出了什么新东东如React Fiber才能快速跟上。前端就是这样痛并快乐着。
虚拟DOM介绍的更多相关文章
- 解析vue2.0的diff算法 虚拟DOM介绍
react虚拟dom:依据diff算法台 前端:更新状态.更新视图:所以前端页面的性能问题主要是由Dom操作引起的,解放Dom操作复杂性 刻不容缓 因为:Dom渲染慢,而JS解析编译相对非常非常非常快 ...
- React虚拟DOM具体实现——利用节点json描述还原dom结构
前两天,帮朋友解决一个问题: ajax请求得到的数据,是一个对象数组,每个对象中,具有三个属性,parentId,id,name,然后根据这个数据生成对应的结构. 刚好最近在看React,并且了解到其 ...
- 实现一个简单的虚拟DOM
现在的流行框架,无论React还是Vue,都采用虚拟DOM. 好处就是,当我们数据变化时,无需像Backbone那样整体重新渲染,而是局部刷新变化部分,如下组件模版: <ul class=&qu ...
- vue 源码学习三 vue中如何生成虚拟DOM
vm._render 生成虚拟dom 我们知道在挂载过程中, $mount 会调用 vm._update和vm._render 方法,vm._updata是负责把VNode渲染成真正的DOM,vm._ ...
- Vue之虚拟DOM
一.真实DOM和其解析流程? 浏览器渲染引擎工作流程都差不多,大致分为5步,创建DOM树——创建StyleRules——创建Render树——布局Layout——绘制Painting 第一步,用HTM ...
- 从虚拟dom了解vue渲染函数
vue渲染函数就是render函数,他会返回一个VNode,VNode是一个js对象,是dom的映射 vue在介绍渲染函数那个章节看的不是很懂,所以想要彻底的理解渲染函数,首先需要了解vue的虚拟do ...
- 深入Vue2.x的虚拟DOM diff原理
一.前言 Vue的核心是双向绑定和虚拟DOM(下文我们简称为vdom),关于双向绑定可以参阅木琴的文章<剖析Vue原理&实现双向绑定MVVM>,vdom是树状结构,其节点为vnod ...
- 虚拟 DOM
虚拟DOM :virtual dom(以下简称vdom,是vue和react的核心),使用比较简单. 一,vdom是什么,为何会存在vdom 1,什么是vdom:用js模拟DOM结构,DOM操作非常‘ ...
- vue核心之虚拟DOM
一.前言 虚拟DOM概念随着react的诞生而诞生,由facebook提出,其卓越的性能很快得到广大开发者的认可:继react之后vue2.0也在其核心引入了虚拟DOM的概念,本文将以vue2.0使用 ...
随机推荐
- hdu 1532&&poj1273 基础最大流
#include<stdio.h> #include<string.h> #include<queue> #include<iostream> usin ...
- myeclipse git 上下箭头表示什么
myeclipse git 上下箭头表示什么? 向上箭头表示本地有提交(commit),但是还没有推(push)到远程代码库中,旁边的数字表示本地commit的次数: 向下箭头表示你拉(fetch)下 ...
- firedac数据集控件的公共祖先类——TFDAdaptedDataSet
firedac数据集控件的公共祖先类——TFDAdaptedDataSet TFDQuery = class(TFDCustomQuery)TFDCustomQuery = class(TFDRdbm ...
- jvm的运行模式 client和 server两种
jvm的运行模式 client和 server两种 学习了:https://www.cnblogs.com/fsjohnhuang/p/4270505.html 在jdk 9的情况下,好像没有clie ...
- CSS3:box-sizing:不再为盒子模型而烦恼
题外话: W3C奉行的标准,就是content-box,就是须要计算边框,填充还有内容的;可是就我个人而言, 比較喜欢的是传统IE6时候的怪异模式,不用考虑容器是否会被撑开(打乱布局); 盒子模型差异 ...
- luogu2161 [SHOI2009]会场预约
题目大意 随着时间的推移这里有几个任务对应着一段区间.每次要将任务安到时间线上时,要把时间线上已有的与该任务对应区间有交集的区间对应的任务删去.求每次删去的区间个数,以及整个时间线上有几个任务.时间线 ...
- bzoj4034 [HAOI2015]树上操作——树链剖分
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=4034 树剖裸题: 一定要注意 long long !!! update 的时候别忘了 pus ...
- bzoj3436: 小K的农场(差分约束)
3436: 小K的农场 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 1575 Solved: 690[Submit][Status][Discus ...
- 洛谷P1894 [USACO4.2]完美的牛栏The Perfect Stall(二分图)
P1894 [USACO4.2]完美的牛栏The Perfect Stall 题目描述 农夫约翰上个星期刚刚建好了他的新牛棚,他使用了最新的挤奶技术.不幸的是,由于工程问题,每个牛栏都不一样.第一个星 ...
- ROS-URDF-活动关节
前言:介绍活动关节,并使机器人活动起来. 参考自:http://wiki.ros.org/urdf/Tutorials/Building%20a%20Movable%20Robot%20Model%2 ...