Canopy聚类算法分析
原文链接:http://blog.csdn.net/yclzh0522/article/details/6839643
Canopy聚类算法是可以并行运行的算法,数据并行意味着可以多线程进行,加快聚类速度,开源ML库Mahout使用。
一、概念
与传统的聚类算法(比如 K-means )不同,Canopy 聚类最大的特点是不需要事先指定 k 值( 即 clustering 的个数),因此具有很大的实际应用价值。与其他聚类算法相比,Canopy聚类虽然精度较低,但其在速度上有很大优势,因此可以使用 Canopy 聚类先对数据进行“粗”聚类,(摘自于Mahout一书:Canopy算法是一种快速地聚类技术,只需一次遍历数据科技得到结果,无法给出精确的簇结果,但能给出最优的簇数量。可为K均值算法优化超参数..K....)得到
k 值后再使用 K-means 进行进一步“细”聚类。这种Canopy + K-means的混合聚类方式分为以下两步:
Step1、聚类最耗费计算的地方是计算对象相似性的时候,Canopy 聚类在第一阶段选择简单、计算代价较低的方法计算对象相似性,将相似的对象放在一个子集中,这个子集被叫做Canopy ,通过一系列计算得到若干Canopy,Canopy 之间可以是重叠的,但不会存在某个对象不属于任何Canopy的情况,可以把这一阶段看做数据预处理;
Step2、在各个Canopy 内使用传统的聚类方法(如K-means),不属于同一Canopy 的对象之间不进行相似性计算。
从这个方法起码可以看出两点好处:首先,Canopy 不要太大且Canopy 之间重叠的不要太多的话会大大减少后续需要计算相似性的对象的个数;其次,类似于K-means这样的聚类方法是需要人为指出K的值的,通过Stage1得到的Canopy 个数完全可以作为这个K值,一定程度上减少了选择K的盲目性。
二、聚类精度
对传统聚类来说,例如K-means、Expectation-Maximization、Greedy Agglomerative Clustering,某个对象与Cluster的相似性是该点到Cluster中心的距离,那么聚类精度能够被很好保证的条件是:
对于每个Cluster都存在一个Canopy,它包含所有属于这个Cluster的元素。
如果这种相似性的度量为当前点与某个Cluster中离的最近的点的距离,那么聚类精度能够被很好保证的条件是:
对于每个Cluster都存在若干个Canopy,这些Canopy之间由Cluster中的元素连接(重叠的部分包含Cluster中的元素)。
数据集的Canopy划分完成后,类似于下图:
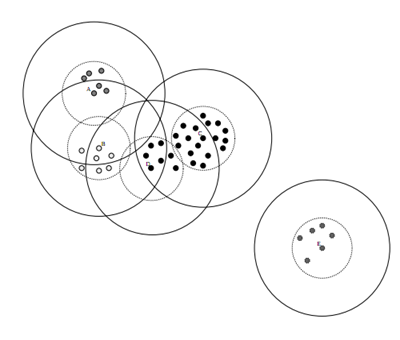
三、Canopy算法流程
(1)将数据集向量化得到一个list后放入内存,选择两个距离阈值:T1和T2,其中T1 > T2,对应上图,实线圈为T1,虚线圈为T2,T1和T2的值可以用交叉校验来确定;
(2)从list中任取一点P,用低计算成本方法快速计算点P与所有Canopy之间的距离(如果当前不存在Canopy,则把点P作为一个Canopy),如果点P与某个Canopy距离在T1以内,则将点P加入到这个Canopy;
(3)如果点P曾经与某个Canopy的距离在T2以内,则需要把点P从list中删除,这一步是认为点P此时与这个Canopy已经够近了,因此它不可以再做其它Canopy的中心了;
(4)重复步骤2、3,直到list为空结束。
注意:Canopy聚类不要求指定簇中心的个数,中心的个数仅仅依赖于举例度量,T1和T2的选择。
Python代码:
#-*- coding:utf-8 -*-
'''
'''
import numpy as np
import matplotlib as nlp #The first op
import scipy as sp
import scipy.sparse.linalg
import time
from Old_regression import crossValidation #使用K均值
import kMeans as km def canopyClustering(datalist):
state =[];
#交叉验证获取T1和T2;
T1,T2 = crossValidation(datalist);
#canopy 预聚类
canopybins= canopy(datalist, T1 , T2);
#使用K均值聚类
k =len(canopybins);
createCent = [canopy[0] for canopy in canopybins];#获取canopybins中心
dataSet = datalist;
centroids, clusterAssment =km.kMeans(dataSet, k, distMeas=distEclud, createCent);
return clusterAssment; #得到一个list后放入内存,选择两个距离阈值:T1和T2,其中T1 > T2
#Canopy聚类不要求指定簇中心的个数,中心的个数仅仅依赖于举例度量,T1和T2的选择。
def canopy(datalist, T1 , T2):
#state = [];datalist = [];
#初始化第一个canopy元素
canopyInit = datalist.pop();
canopyCenter= calCanopyCenter([canopyInit] ); canopyC = [canopyInit];#建立第一个canopy
canopybins = [];
canopybins.append([canopyCenter,canopyC ] ); while not(len(datalist) ==0 ):
PointNow =datalist[len(datalist)-1 ];#PointNow =datalist.pop();
counter = 0;
for canopy in canopybins:
dis =calDis(PointNow, canopy[0]);
#如果点P与某个Canopy距离在T1以内,则将点P加入到这个Canopy;
if dis<T1:
canopy[1].append(PointNow);
counter +=1;
#break;
if dis<T2:
#点P曾经与某个Canopy的距离在T2以内,则需要把点P从list中删除,
#这一步是认为点P此时与这个Canopy已经够近了,因此它不可以再做其它Canopy的中心了
if not(counter ==0):#保证必须率属于一个canopy
del list[len(datalist)-1 ];
break;
else:#建立一个新的Canopy
canopyC = [PointNow];
canopyCenter= PointNow;
canopybins.append([canopyCenter,canopyC ] ); return canopybins; def calDis(va,vb):
dis =0;
for i in range(len(va) ):
dis += va[i]*va[i]+ vb[i]*vb[i];
return dis; #计算canopy中心
def calCanopyCenter(datalist):
center =datalist[0];
for i in len(range(center) ):
center[i]=0; for data in datalist:
center +=data;
center /= len(center); return center;
Canopy聚类算法分析的更多相关文章
- Mahout canopy聚类
Canopy 聚类 一.Canopy算法流程 Canopy 算法,流程简单,容易实现,一下是算法 (1)设样本集合为S,确定两个阈值t1和t2,且t1>t2. (2)任取一个样本点p,作为一个C ...
- Canopy聚类算法
Canopy聚类算法(经典,看图就明白) 聚类算法. 这个算法获得的并不是最终结果,它是为其他算法服务的,比如k-means算法.它能有效地降低k-means算法中计算点之间距离的复杂度. 图中有一个 ...
- Canopy聚类算法(经典,看图就明白)
只有这个算法思想比较对,其他 的都没有一开始的remove: 原网址:http://www.shahuwang.com/?p=1021 Canopy Clustering 这个算法是2000年提出来的 ...
- canopy聚类算法的MATLAB程序
canopy聚类算法的MATLAB程序 凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. canopy聚类算法简介 Canopy聚类算法是一个将对象分组到 ...
- Kmeans聚类算法分析(转帖)
原帖地址:http://www.opencvchina.com/thread-749-1-1.html k-means是一种聚类算法,这种算法是依赖于点的邻域来决定哪些点应该分在一个组中. ...
- Canopy算法聚类
Canopy一般用在Kmeans之前的粗聚类.考虑到Kmeans在使用上必须要确定K的大小,而往往数据集预先不能确定K的值大小的,这样如果 K取的不合理会带来K均值的误差很大(也就是说K均值对噪声的抗 ...
- Kmeans算法的K值和聚类中心的确定
0 K-means算法简介 K-means是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一. K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的 ...
- mahout中kmeans算法和Canopy算法实现原理
本文讲一下mahout中kmeans算法和Canopy算法实现原理. 一. Kmeans是一个很经典的聚类算法,我想大家都非常熟悉.虽然算法较为简单,在实际应用中却可以有不错的效果:其算法原理也决定了 ...
- Mahout 系列之--canopy 算法
Canopy 算法,流程简单,容易实现,一下是算法 (1)设样本集合为S,确定两个阈值t1和t2,且t1>t2. (2)任取一个样本点p属于S,作为一个Canopy,记为C,从S中移除p. (3 ...
随机推荐
- springcloud(七): 使用Feign调用Eureka Server客户端服务
当我们通过RestTemplate调用其它服务的API时,所需要的参数须在请求的URL中进行拼接,如果参数少的话或许我们还可以忍受,一旦有多个参数的话,这时拼接请求字符串就会效率低下,并且显得好傻. ...
- 【CodeCraft-19 and Codeforces Round #537 (Div. 2) C】Creative Snap
[链接] 我是链接,点我呀:) [题意] 横坐标1..2^n对应着2^n个复仇者的基地,上面有k个复仇者(位置依次给出). 你是灭霸你要用以下方法消灭这k个复仇者: 一开始你获取整个区间[1..2^n ...
- 【hdu 2108】Shape of HDU
[题目链接]:http://acm.hdu.edu.cn/showproblem.php?pid=2108 [题意] [题解] 逆时针; 可以想象一下; 如果是凸多边形的话; 逆时针的相邻的两条边; ...
- Beetl学习总结(4)——Web集成
4.1. Web提供的全局变量 Web集成模块向模板提供web标准的变量,做如下说明 request 中的所有attribute.在模板中可以直接通过attribute name 来引用,如在cont ...
- Git学习总结(3)——代码托管平台简介
可以说GitHub的出现完全颠覆了以往大家对代码托管网站的认识.GitHub不但是一个代码托管网站,更是一个程序员的SNS社区.GitHub真正迷人的是它的创新能力与Geek精神,这些都是无法模仿的. ...
- qwb VS 去污棒
qwb VS 去污棒 Time Limit: 2 Sec Memory Limit: 256 MB Description qwb表白学姐失败后,郁郁寡欢,整天坐在太阳底下赏月.在外人看来,他每天自 ...
- F - Many Moves
F - Many Moves Time limit : 2sec / Memory limit : 256MB Score : 900 points Problem Statement There a ...
- 神奇的幻方 noip2015day1 T1
题目描述 Description 幻方是一种很神奇的N∗N矩阵:它由数字 1,2,3, … … ,N∗N构成,且每行.每列及两条对角线上的数字之和都相同. 当N为奇数时,我们可以通过以下方法构建一个 ...
- Mac下使用OpenMP
Mac下使用OpenMP,修改Build Options 下面的compiler for c/c++/objective-C 为 LLVM GCC 4.2 - Language 则可以找到Enable ...
- 在win10下改变默认的输入法切换Ctrl+Space
在win10下改变默认的输入法切换Ctrl+Space 学习了:https://www.zhihu.com/question/22288432 在win10下面,有两种风格的控制面板设置: 在输入法上 ...