Spark Tachyon编译部署(含单机和集群模式安装)
Tachyon编译部署
编译Tachyon
单机部署Tachyon
集群模式部署Tachyon
1、Tachyon编译部署
Tachyon目前的最新发布版为0.7.1,其官方网址为http://tachyon-project.org/。Tachyon文件系统有3种部署方式:单机模式、集群模式和高可用集群模式,集群模式相比于高可用集群模式区别在于多Master节点。下面将介绍单机和集群环境下去安装、配置和使用Tachyon。
1.1 编译Tachyon
1.1.1 下载并上传源代码
第一步 下载到Tachyon源代码:
对于已经发布的版本可以直接从github下载Tachyon编译好的安装包并解压,由于Tachyon与Spark版本有对应关系,另外该系列搭建环境为Spark1.1.0,对应下载Tachyon0.5.0,版本对应参考http://tachyon-project.org/documentation/Running-Spark-on-Tachyon.html描述

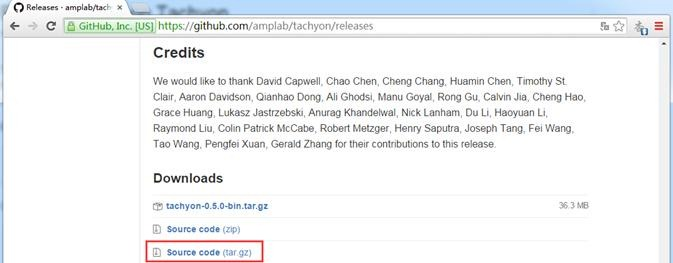
下载地址为https://github.com/amplab/tachyon/releases ,为以下演示我们在这里下载的是tachyon-0.5.0.tar.gz源代码包,文件大小为831K,如下图所示:
第二步 在主节点上解压缩
$cd /home/hadoop/upload/
$tar -xzf tachyon-0.5..tar.gz
第三步 把tachyon-0.5.0.tar.gz改名并移动到/app/complied目录下
$mv tachyon-0.5. /app/complied/tachyon-0.5.-src $ll /app/complied
1.1.2编译代码
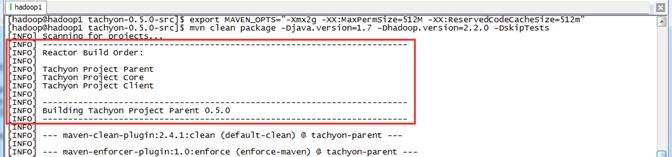
为了更好地契合用户的本地环境,如Java版本、Hadoop版本或其他一些软件包的版本,可以下载Tachyon源码自行编译。Tachyon开源在GitHub上,可以很方便地获得其不同版本的源码。Tachyon项目采用Maven进行管理,因此可以采用 mvn package 命令进行编译打包。编译Tachyon源代码的时候,需要从网上下载依赖包,所以整个编译过程机器必须保证在联网状态。编译执行如下脚本:
$cd /app/complied/tachyon-0.5.-src $export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m" $mvn clean package -Djava.version=1.7 -Dhadoop.version=2.2. -DskipTests
整个编译过程编译了约3个任务,整个过程耗时大约4分钟。

使用如下命令查看编译后该Tachyon项目大小为72M。
$cd /app/complied/tachyon-0.5.-src
$du -s /app/complied/tachyon-0.5.-src

完成这一步后,我们就得到了能够运行在用户本地环境的Tachyon,下面我们分别介绍如何在单机和分布式环境下配置和启动Tachyon,在进行部署之前先把编译好的文件复制到/app/hadoop下并把文件夹命名为Tachyon-0.5.0:
$cd /app/complied $cp -r tachyon-0.5.-src /app/hadoop/tachyon-0.5. $ll /app/hadoop
1.2 单机部署Tachyon
这里要注意一点,Tachyon在单机(local)模式下启动时会自动挂载RamFS,所以请保证使用的账户具有sudo权限。
【注】编译好的Tachyon将本系列附属资源/install中提供,具体名称为10.tachyon-0.5.0-hadoop2.2.0-complied.zip
1.2.1 配置Tachyon
Tachyon相关配置文件在$TACHYON_HOME/conf目录下,在workers文件中配置需要启动TachyonWorker的节点,默认是localhost,所以在单机模式下不用更改(在Tachyon-0.5.0版本中,该文件为slaves)。在这里需要修改tachyon-env.sh配置文件,具体操作是将tachyon-env.sh.template复制为tachyon-env.sh:
$cd /app/hadoop/tachyon-0.5./conf
$cp tachyon-env.sh.template tachyon-env.sh
$ll
$vi tachyon-env.sh
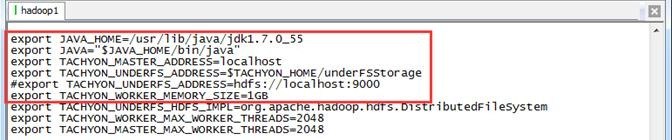
并在tachyon-env.sh中修改具体配置,下面列举了一些重要的配置项:
- JAVA_HOME:系统中java的安装路径
- TACHYON_MASTER_ADDRESS:启动TachyonMaster的地址,默认为localhost,所以在单机模式下不用更改
- TACHYON_UNDERFS_ADDRESS:Tachyon使用的底层文件系统的路径,在单机模式下可以直接使用本地文件系统,如"/tmp/tachyon",也可以使用HDFS,如"hdfs://ip:port"
- TACHYON_WORKER_MEMORY_SIZE:每个TachyonWorker使用的RamFS大小
1.2.2 格式化Tachyon
完成配置后即可以单机模式启动Tachyon,启动前需要格式化存储文件,格式化和启动Tachyon的命令分别为:
$cd /app/hadoop/tachyon-0.5./bin $./tachyon format
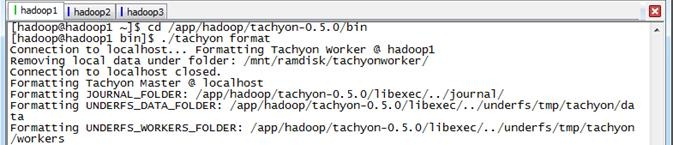
存储文件为$TACHYON_HOME/underfs/tmp/tachyon目录下。
1.2.3 启动Tachyon
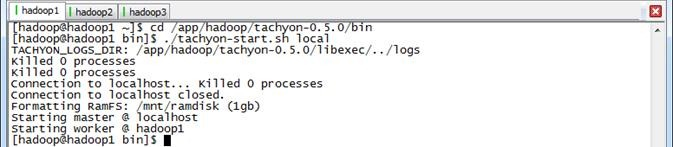
使用如下命令启动Tachyon,可以看到在/nmt/ramdisk目录下格式化RamFS
$cd /app/hadoop/tachyon-0.5./bin
$./tachyon-start.sh local
1.2.4 验证启动
使用JPS命令查看Tachyon进程,分别为:TachyonWorker和TachyonMaster

查看Tachyon监控页面,访问地址为http://hadoop1:19999
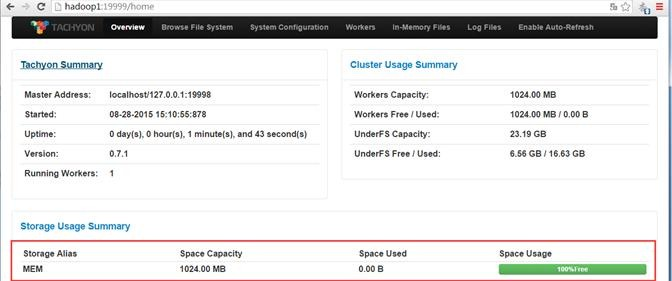
1.2.5 停止Tachyon
停止Tachyon的命令为:
$cd /app/hadoop/tachyon-0.5./bin $./tachyon-stop.sh

1.3 集群模式部署Tachyon
1.3.1 集群环境
集群包含三个节点,运行进程分布如下:
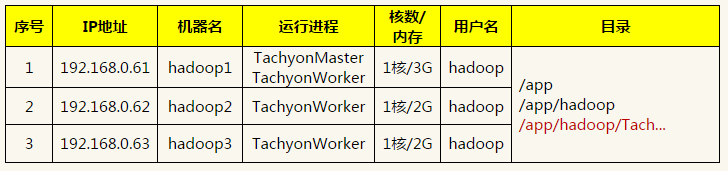
1.3.2 配置conf/worker
Tachyon相关配置文件在$TACHYON_HOME/conf目录下,对slaves文件中配置需要启动TachyonWorker的节点,在这里需要设置hadoop1、hadoop2和hadoop3三个节点:
$cd /app/hadoop/tachyon-0.5./conf
$vi slaves

1.3.3 配置conf/tachyon-env.sh
在$TACHYON_HOME/conf目录下,将tachyon-env.sh.template复制为tachyon-env.sh,并在achyon-env.sh中修改具体配置。不同于单机模式,这里需要修改TachyonMaster地址以及底层文件系统路径:
$cd /app/hadoop/tachyon-0.5./conf
$cp tachyon-env.sh.template tachyon-env.sh
$vi tachyon-env.sh
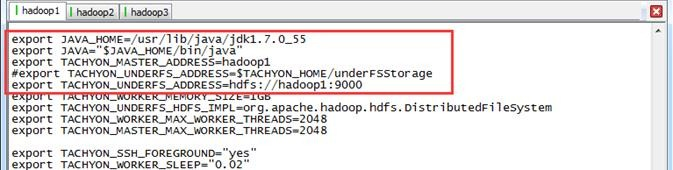
在该文件中修改一下两个参数,这里使用底层文件系统为HDFS:
export TACHYON_MASTER_ADDRESS=hadoop1
export TACHYON_UNDERFS_ADDRESS=hdfs://hadoop1:9000
1.3.4 向各个节点分发Tachyon
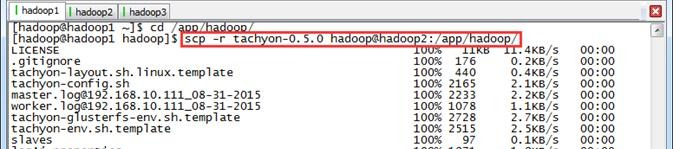
使用如下命令把hadoop文件夹复制到hadoop2和hadoop3机器
$cd /app/hadoop/
$scp -r tachyon-0.5. hadoop@hadoop2:/app/hadoop/
$scp -r tachyon-0.5. hadoop@hadoop3:/app/hadoop/
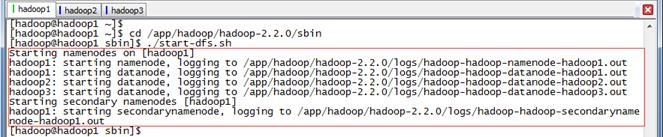
1.3.5 启动HDFS
$cd /app/hadoop/hadoop-2.2./sbin
$./start-dfs.sh
1.3.6 格式化Tachyon
启动前需要格式化存储文件,格式化命令为:
$cd /app/hadoop/tachyon-0.5./bin
$./tachyon format
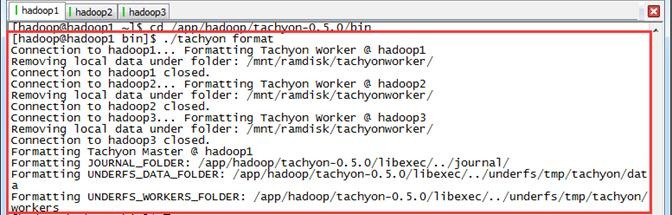
可以看到在HDFS的/tmp创建了tachyon文件夹。
1.3.7 启动Tachyon
在这里使用SudoMout参数,需要在启动过程中输入hadoop的密码,具体过程如下:
$cd /app/hadoop/tachyon-0.5./bin
$./tachyon-start.sh all SudoMount
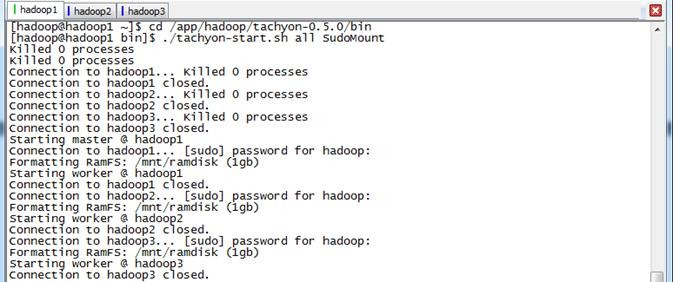
启动Tachyon有了更多的选项:
- ./tachyon-start.sh all Mount在启动前自动挂载TachyonWorker所使用的RamFS,然后启动TachyonMaster和所有TachyonWorker。由于直接使用mount命令,所以需要用户为root;
- ./tachyon-start.sh all SudoMount在启动前自动挂载TachyonWorker所使用的RamFS,然后启动TachyonMaster和所有TachyonWorker。由于使用sudo mount命令,所以需要用户有sudo权限;
- ./tachyon-start.sh all NoMount认为RamFS已经挂载好,不执行挂载操作,只启动TachyonMaster和所有TachyonWorker
因此,如果不想每次启动Tachyon都挂载一次RamFS,可以先使用命令./tachyon-mount.sh Mount workers 或./tachyon-mount.sh SudoMount workers挂载好所有RamFS,然后使用./tachyon-start.sh all NoMount 命令启动Tachyon。
单机和集群式模式的区别就在于节点配置和启动步骤,事实上,也可以在集群模式下只设置一个TachyonWorker,此时就成为伪分布模式。
1.3.8 验证启动
使用JPS命令查看Tachyon进程,分别为:TachyonWorker和TachyonMaster

可以在浏览器内打开Tachyon的WebUI,如 http://hadoop1:19999,查看整个Tachyon的状态,各个TachyonWorker的运行情况、各项配置信息和浏览文件系统等。
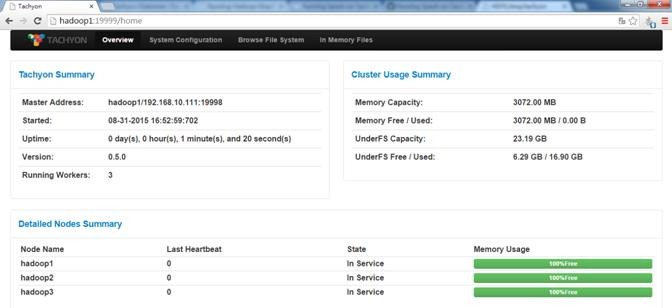
$cd /app/hadoop/tachyon-0.5./bin
$./tachyon runTests
Spark Tachyon编译部署(含单机和集群模式安装)的更多相关文章
- hadoop单机and集群模式安装
最近在学习hadoop,第一步当然是亲手装一下hadoop了. 下面记录我hadoop安装的过程: 注意: 1,首先明确hadoop的安装是一个非常简单的过程,装hadoop的主要工作都在配置文件上, ...
- Greenplum源码编译安装(单机及集群模式)完全攻略
公司有个项目需要安装greenplum数据库,让我这个gp小白很是受伤,在网上各种搜,结果找到的都是TMD坑货帖子,但是经过4日苦战,总算是把greenplum的安装弄了个明白,单机及集群模式都部署成 ...
- Redis 5.0.7 讲解,单机、集群模式搭建
Redis 5.0.7 讲解,单机.集群模式搭建 一.Redis 介绍 不管你是从事 Python.Java.Go.PHP.Ruby等等... Redis都应该是一个比较熟悉的中间件.而大部分经常写业 ...
- Zookeeper简介及单机、集群模式搭建
1.zookeeper简介 一个开源的分布式的,为分布式应用提供协调服务的apache项目. 提供一个简单的原语集合,以便于分布式应用可以在它之上构建更高层次的同步服务. 设计非常易于编程,它使用的是 ...
- Presto单机/集群模式安装笔记
Presto单机/集群模式安装笔记 一.安装环境 二.安装步骤 三.集群模式安装: 3.1 集群模式修改配置部分 3.1.1 coordinator 节点配置. Node172配置 3.1.2 nod ...
- Apache Spark 2.2.0 中文文档 - 集群模式概述 | ApacheCN
集群模式概述 该文档给出了 Spark 如何在集群上运行.使之更容易来理解所涉及到的组件的简短概述.通过阅读 应用提交指南 来学习关于在集群上启动应用. 组件 Spark 应用在集群上作为独立的进程组 ...
- Hadoop学习笔记(4)hadoop集群模式安装
具体的过程参见伪分布模式的安装,集群模式的安装和伪分布模式的安装基本一样,只有细微的差别,写在下面: 修改masers和slavers文件: 在hadoop/conf文件夹中的配置文件中有两个文件ma ...
- Kafka集群模式安装(二)
我们来安装Kafka的集群模式,三台机器: 192.168.131.128 192.168.131.130 192.168.131.131 Kafka集群需要依赖zookeeper,所以需要先安装好z ...
- Spark 官方文档(2)——集群模式
Spark版本:1.6.2 简介:本文档简短的介绍了spark如何在集群中运行,便于理解spark相关组件.可以通过阅读应用提交文档了解如何在集群中提交应用. 组件 spark应用程序通过主程序的Sp ...
随机推荐
- opencv——图像的灰度处理(线性变换/拉伸/直方图/均衡化)
实验内容及实验原理: 1.灰度的线性变换 灰度的线性变换就是将图像中所有的点的灰度按照线性灰度变换函数进行变换.该线性灰度变换函数是一个一维线性函数:f(x)=a*x+b 其中参数a为线性函数的斜率, ...
- ubuntu 安装Gremlin 的图形化环境
参考文档:https://www.jianshu.com/p/618cf6667381 部署HugeGraphServer # 直接下载release包 网址:https://github.com/h ...
- VS2015使用过程中参考过的有用链接
VS中的第一个C程序:如何在Visual Studio 2015中编写C程序:https://www.bilibili.com/video/av5921799?from=search&seid ...
- Python IO编程-组织文件
对于日常中遇到的批量任务,有些可以通过请求python完成自动化,我非常渴望拥有这些能力,在去年学习了python读写文件之后,我马上迫不及待的开始学习‘组织文件’,经过学习,我发现python组织文 ...
- [NOIP1999]进制位(搜索)
P1013 进制位 题目描述 著名科学家卢斯为了检查学生对进位制的理解,他给出了如下的一张加法表,表中的字母代表数字. 例如: + L K V E L L K V E K K V E KL V V E ...
- CF17E Palisection(回文树)
题意翻译 给定一个长度为n的小写字母串.问你有多少对相交的回文子 串(包含也算相交) . 输入格式 第一行是字符串长度n(1<=n<=2*10^6),第二行字符串 输出格式 相交的回文子串 ...
- 一个Web报表项目的性能分析和优化实践(四):MySQL建立索引,唯一索引和组合索引
先大致介绍下项目的数据库信息. 数据库A:主要存放的通用的表,如User.Project.Report等. 数据库B.C.D:一个项目对应一个数据库,而且这几个项目的表是完全一样的. 数据库表的特点 ...
- 杯子 (glass)
题目 试题1:杯子 (glass) 源代码:glass.cpp 输入文件:glass.in 输出文件:glass.out 时间限制:1s 空间限制:256MB 题目描述 小明买了N个容积可以 ...
- hbase启动报错
前一段时间vmware上的ubuntu的hbase用不了了,而hadoop能正常的操作,非常的奇怪. 错误信息好像是connect fail, RPC什么的,看来跟网路有关. 想起以前曾经解决过hba ...
- 解决MAC下PHP连接MYSQL错误Warning: mysql_connect(): No such file or directory in conn.php
今天在mac上用php去连接mysql数据库,出现了 mac PHP Warning: mysql_connect(): [2002] No such file... 详细例如以下所看到的: Dir ...