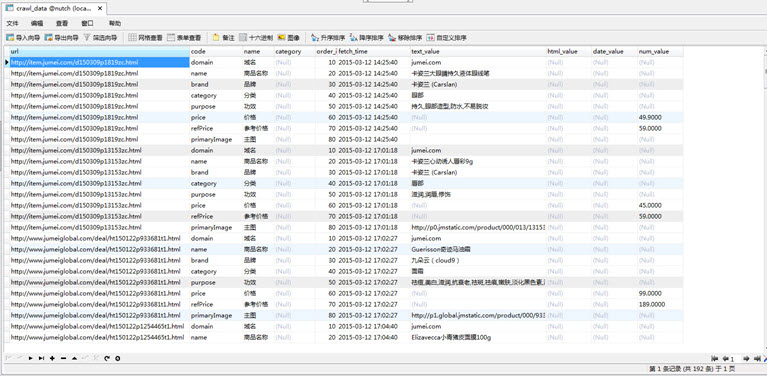
解析数据存储MySQL
为了适应不同项目对不同感兴趣属性的解析存储,数据存储结构采用纵向的属性列表方式,即一个url页面多个属性存储多条记录方式,并且按照text,html,
data,num几大典型类型分别对应存储。
创建UTF-8字符集的nutch数据库,并执行表初始化脚本,参考DDL:
CREATE TABLE `crawl_data` (
`url` varchar(255) NOT NULL,
`code` varchar(255) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`category` varchar(255) DEFAULT NULL,
`order_index` int(255) DEFAULT NULL,
`fetch_time` datetime NOT NULL,
`text_value` text, `html_value` text,
`date_value` datetime DEFAULT NULL,
`num_value` decimal(18,2) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
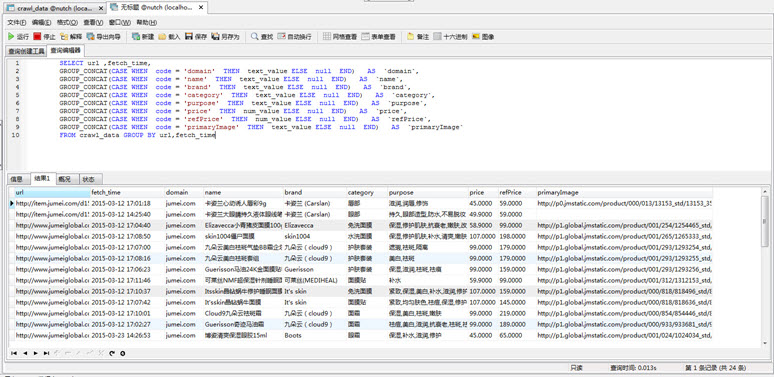
为了一般在业务系统获取同一个url的多个属性或友好查询显示,参考如下MySQL脚本实现把纵向的属性列表属性转换为横向的多列显示模式。网上有 相关
参考脚本大多是基于数字字段sum汇总等模式的纵转横SQL脚本,本项目需求是单一的基于字符串信息转换,经过一段摸索最后找到基于 GROUP_CONCAT可
以实现:
SELECT url ,fetch_time,
GROUP_CONCAT(CASE WHEN code = 'domain' THEN text_value ELSE null END) AS `domain`,
GROUP_CONCAT(CASE WHEN code = 'name' THEN text_value ELSE null END) AS `name`,
GROUP_CONCAT(CASE WHEN code = 'brand' THEN text_value ELSE null END) AS `brand`,
GROUP_CONCAT(CASE WHEN code = 'category' THEN text_value ELSE null END) AS `category`,
GROUP_CONCAT(CASE WHEN code = 'purpose' THEN text_value ELSE null END) AS `purpose`,
GROUP_CONCAT(CASE WHEN code = 'price' THEN num_value ELSE null END) AS `price`,
GROUP_CONCAT(CASE WHEN code = 'refPrice' THEN num_value ELSE null END) AS `refPrice`,
GROUP_CONCAT(CASE WHEN code = 'primaryImage' THEN text_value ELSE null END) AS `primaryImage` FROM crawl_data GROUP BY url,fetch_time
技术分享:www.kaige123.com
解析数据存储MySQL的更多相关文章
- zookeeper原理解析-数据存储
Zookeeper内存结构 Zookeeper是怎么存储数据的,什么机制保证集群中数据是一致性,在网络异常,当机以及停电等异常情况下恢复数据的,我们知道数据库给我们提供了这些功能,其实zookeepe ...
- Python数据存储 — MySQL数据库操作
本地安装MySQL 调试环境python3.6,调试python操作mysql数据库,首先要在本地或服务器安装mysql数据库. 安装参考:https://mp.csdn.net/postedit/8 ...
- 1.zookeeper原理解析-数据存储之Zookeeper内存结构
Zookeeper是怎么存储数据的,什么机制保证集群中数据是一致性,在网络异常,当机以及停电等异常情况下恢复数据的,我们知道数据库给我们提供了这些功能,其实zookeeper也实现了类似数据库的功能. ...
- scrapy 数据存储mysql
#spider.pyfrom scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Ru ...
- scrapy存储mysql
scrapy 数据存储mysql #spider.pyfrom scrapy.linkextractors import LinkExtractor from scrapy.spiders imp ...
- 重新学习MySQL数据库3:Mysql存储引擎与数据存储原理
重新学习Mysql数据库3:Mysql存储引擎与数据存储原理 数据库的定义 很多开发者在最开始时其实都对数据库有一个比较模糊的认识,觉得数据库就是一堆数据的集合,但是实际却比这复杂的多,数据库领域中有 ...
- 冰河,能不能讲讲如何实现MySQL数据存储的无限扩容?
写在前面 随着互联网的高速发展,企业中沉淀的数据也越来越多,这就对数据存储层的扩展性要求越来越高.当今互联网企业中,大部分企业使用的是MySQL来存储关系型数据.如何实现MySQL数据存储层的高度可扩 ...
- MySQL数据存储
MySQL体系架构 客户端连接器 提供与MySQL服务器建立的支持.目前几乎支持所有主流的服务端编程技术,例如常见的 Java.C.Python..NET等,它们通过各自API技术与MySQL建立连接 ...
- scrapy架构与目录介绍、scrapy解析数据、配置相关、全站爬取cnblogs数据、存储数据、爬虫中间件、加代理、加header、集成selenium
今日内容概要 scrapy架构和目录介绍 scrapy解析数据 setting中相关配置 全站爬取cnblgos文章 存储数据 爬虫中间件和下载中间件 加代理,加header,集成selenium 内 ...
随机推荐
- delete 类对象指针的注意事项]
http://blog.csdn.net/infoworld/article/details/45560219 场景:1. C++类有构造和析构函数,析构函数是在类对象被delete时(或局部变量自动 ...
- Struts2标签库
一. 写jsp页面的时候,在struts2中,用的是s标记,先引入标记: <%@ taglib prefix="s" uri="/struts-tags" ...
- 数码管的封装实验 --- verilog
数码管的封装实验.显示使能信号置高才可以显示.对于小数点不用,故不显示. 数码管分为共阴数码管和共阳数码管,数码管不同,编码不同,下面是两种数码管显示0-F以及消隐的不同编码: 共阴数码管(高有效): ...
- 3.工厂方法模式(Factory Method)
using System; using System.Reflection; namespace ConsoleApplication1 { class Program { static void M ...
- SQL Server 2012 OFFSET/FETCH NEXT分页示例(转载)
原文:http://beyondrelational.com/modules/29/presentations/483/scripts/12983/sql-server-2012-server-sid ...
- AngularJS深入(5)——provider
太精彩,不得不全文引用. 到这个层次,可能才敢说自己懂了吧... http://syaning.com/2015/07/21/dive-into-angular-5/ 在使用AngularJS的时候, ...
- hdu 1011 树形dp
题意:是有n个洞组成一棵树,你有m个士兵,你从1号房间开始攻打,每个洞有a个"bugs"和b的价值.你的一个士兵可以打20 个"bugs",为了拿到这个洞的价值 ...
- Kinect学习笔记(六)——深度数据测量技术及应用
一.Kinect视角场 1.43°垂直方向和57°水平方向可视范围. 2.视角场常量值定义 属性 描述 Format 获取或设置深度图像格式 MaxDepth 获取最大深度值 MinDepth 获取最 ...
- Hark的数据结构与算法练习之圈排序
算法说明 圈排序是选择排序的一种.其实感觉和快排有一点点像,但根本不同之处就是丫的移动的是当前数字,而不像快排一样移动的是其它数字.根据比较移动到不需要移动时,就代表一圈结束.最终要进行n-1圈的比较 ...
- HTML-a
链接的其他使用 电话 <a href="tel:(phonenumber)">Tel</a> 短信 <a href="sms:(phonen ...