python-基础案例
Linux有很多很好的内存、IO调度机制,但是并不会适用于所有场景。对于运维人员来说,Linux比较让人头疼的一个地方是:它不会因为MySQL很重要就避免将分配给MySQL的地址空间映射到swap上。对于频繁进行读写操作的系统而言,数据看似在内存而实际上在磁盘是非常糟糕的,响应时间的增长很可能直接拖垮整个系统。所以,作为运维人员,怎样做到尽量避免MySQL惨遭Swap的毒手将显得尤为重要!
SWAP是操作系统虚拟出来的一部分内存地址,它的物理存储元件是磁盘。在备份数据或恢复数据时,文件系统会向Linux系统请求大量的内存作为cache。在物理内存使用殆尽时候,为了确保程序运行,往往会将另外的一些占用物理内存地址空间的程序映射到swap分区上。
操作系统设置swap的目的
程序运行的一个必要条件就是足够的内存,而内存往往是系统里面比较紧张的一种资源。为了满足更多程序的要求,操作系统虚拟了一部分内存地址,并将之映射到swap上。对于程序来说,它只知道操作系统给自己分配了内存地址,但并不清楚这些内存地址到底映射到物理内存还是swap。
物理内存和swap在功能上是一样的,只是因为物理存储元件的不同(内存和磁盘),性能上有很大的差别。操作系统会根据程序使用内存的特点进行换入和换出,尽可能地把物理内存留给最需要它的程序。但是这种调度是按照预先设定的某种规则的,并不能完全符合程序的需要。一些特殊的程序(比如MySQL)希望自己的数据永远寄存在物理内存里,以便提供更高的性能。于是操作系统就设置了几个api,以便为调用者提供"特殊服务"。
服务器产生Swa分区的原因
1)copy一个大文件,比如上百G的backup包
2)正在mysqldump以及mysql import一个很大的库的时候。
3)大批量的并发操作的io writer和io read操作。
MySQL程序运行时,物理内存为MySQL分配了大量的物理地址空间,以提高执行的速率。为了避免在执行消耗大量内存的操作时将MySQL所拥有的部分物理内存地址空间映射到swap分区上(比如出现了MySQL服务器Swap满了100%导致db很慢很卡的现象),可做一下调整(解决办法):
1)改系统内核参数/proc/sys/vm/swappiness。调整系统使用swap分区的倾向性,数值越低越倾向于释放文件系统的cache,不能避免Linux系统使用swap分区。swappiness=0表示最大限度使用物理内存,然后才是swap分区。swappiness=100表示积极使用swap分区,并且将内存上的数据及时的映射到swap分区上。
/proc/sys/vm/swappiness的内容改成0(临时),/etc/sysctl.conf上添加vm.swappiness=0(永久)这个参数,Linux是倾向于使用swap,还是倾向于释放文件系统cache。在内存紧张的情况下,数值越低越倾向于释放文件系统cache。当然,这个参数只能减少使用swap的概率,并不能避免Linux使用swap。
2)改MySQL参数innodb_flush_method,开启O_DIRECT模式。Innodb的buffer pool会直接绕过文件系统cache来访问磁盘,但是redo log依旧会使用文件系统cache。Redo Log是覆写模式的,即使使用了文件系统的cache也不会占用太多
3)加MySQL配置参数memlock。将MySQL锁定在内存中防止被swapping out。这个参数会强迫mysqld进程的地址空间一直被锁定在物理内存上,对于os来说是非常霸道的一个要求。必须要用root帐号来启动MySQL才能生效。
4)指定MySQL使用大页内存(Large Page)。Linux上的大页内存是不会被换出物理内存的,和memlock有异曲同工之妙。
5)临时释放锁占据的swap。
=========================================================
在Mysql数据库维护中,会遇到的一个现象: MySQL内存持续增加,最高时物理内存消耗达到90%以上,导致swap使用率100%,进而造成内存不足,系统自动kill mysql进程。Mysql服务挂掉,查看Mysql的error日志信息:
[ERROR] InnoDB: Unable to lock /usr/local/mysql/var/ibdata1, error: 11
或者
InnoDB: mmap(137363456 bytes) failed; errno 12
2016-03-01 01:38:42 13064 [ERROR] InnoDB: Cannot allocate memory for the buffer pool
2016-03-01 01:38:42 13064 [ERROR] Plugin 'InnoDB' init function returned error.
2016-03-01 01:38:42 13064 [ERROR] Plugin 'InnoDB' registration as a STORAGE ENGINE failed.
2016-03-01 01:38:42 13064 [ERROR] Unknown/unsupported storage engine: InnoDB
2016-03-01 01:38:42 13064 [ERROR] Aborting
出现上面报错的原因一般是系统内存资源不足造成的(error 11在mysql中是资源临时不可用),解决方法是升级系统内存或者添加swap;
MySQL的内存消耗分为:
1)会话级别的内存消耗:如sort_buffer_size等,每个会话都会开辟一个sort_buffer_size来进行排序操作。
2)全局的内存消耗:例如:innodb_buffer_pool_size等,全局共享的内存段。 会话级的内存消耗可能是一个原因。关于会话级的内存消耗解释如下:
read_buffer_size, sort_buffer_size, read_rnd_buffer_size, tmp_table_size这些参数在需要的时候才分配,操作后释放。
这些会话级的内存,不管使用多少都分配该size的值,即使实际需要远远小于这些size。
每个线程可能会不止一次需要分配buffer,例如子查询,每层都需要有自己的read_buffer,sort_buffer, tmp_table_size 等。
找到每次内存消耗峰值是不切实际的,因此建议可以用来衡量一下你实际修改一些变量值产生的反应,例如把 sort_buffer_size
从1MB增加到4MB并且在max_connections为1000 的情况下,内存消耗增长峰值并不是你所计算的3000MB而是30MB。
首先在/etc/my.cnf的mysqld配置区域下增加下面一句(根据机器本身的内存配置来设置下面这个参数值):
[root@mysql01 ~]# vim /etc/my.cnf
[mysqld]
.......
innodb_buffer_pool_size = 128M
然后开启Swap分区,重启Mysql服务。
开启SWAP分区的方法
1)创建用于交换分区的文件(block_size、number_of_block 大小可以根据机器本身配置情况进行自定义,)
[root@mysql01 ~]# dd if=/dev/zero of=/mnt/swap bs=1M count=4096 2)设置交换分区文件:
[root@mysql01 ~]# mkswap /mnt/swap 3)立即启用交换分区文件
[root@mysql01 ~]# swapon /mnt/swap 温馨提示:
如果在/etc/rc.local中有"swapoff -a",则需要修改为"swapon -a" 4)设置开机时自启用 SWAP 分区:
需要修改文件 /etc/fstab 中的 SWAP 行,添加:
[root@mysql01 ~]# vim /etc/fstab
/mnt/swap swap swap defaults 0 0 5)修改swpapiness参数
在Linux系统中,可以通过查看/proc/sys/vm/swappiness内容的值来确定系统对SWAP分区的使用原则。
当swappiness内容的值为0时,表示最大限度地使用物理内存,物理内存使用完毕后,才会使用SWAP分区。
当swappiness内容的值为100时,表示积极地使用SWAP分区,并且把内存中的数据及时地置换到SWAP分区。 查看修改前为0,需要在物理内存使用完毕后才会使用SWAP分区:
[root@mysql01 ~]# echo 0 > /proc/sys/vm/swappiness 可以上面的方法临时修改此参数,假设我们配置为空闲内存少于10%时才使用SWAP分区,则操作方法如下:
[root@mysql01 ~]# echo 10 > /proc/sys/vm/swappiness 若需要永久修改此配置,在系统重启之后也生效的话,可以修改 /etc/sysctl.conf 文件,并增加以下内容:
[root@mysql01 ~]# vim /etc/sysctl.conf
vm.swappiness=10
[root@mysql01 ~]# sysctl -p 6)最后重启mysql服务
[root@mysql01 ~]# /etc/init.d/mysqld restart
关闭SWAP分区的方法
当系统出现内存不足时,开启 SWAP 可能会因频繁换页操作,导致 IO 性能下降。如果要关闭 SWAP,可以采用如下方法。 1)free -m 查询 SWAP 分区设置:
[root@mysql01 ~]# free -m 2)使用命令 swapoff 关闭 SWAP,比如:
[root@mysql01 ~]# swapoff /mnt/swap 3)修改 /etc/fstab 文件,删除或注释相关配置,取消SWAP的自动挂载:
[root@mysql01 ~]# vim /etc/fsta
#/mnt/swap swap swap defaults 0 0 4)通过 free -m 确认 SWAP 已经关闭。
[root@mysql01 ~]# free -m 5)swappiness 参数调整:
可以使用下述方法临时修改此参数,这里配置为 0%:
[root@mysql01 ~]# echo 0 >/proc/sys/vm/swappiness 若需要永久修改此配置,在系统重启之后也生效的话,可以修改 /etc/sysctl.conf 文件,并增加以下内容:
[root@mysql01 ~]# vim /etc/sysctl.conf
vm.swappiness=0
[root@mysql01 ~]# sysctl -p
=========================================================
来看看曾经碰到的一个由于MySQL内存交换区引起的一场事故
事故现象:公司的一个业务系统程序会调用大量的SQL,一天,发现MySQL的负载极其不稳定,尤其是Slave的负载有点猛,然后经过讨论准备再加一台Slave,。另加了一台Slave后,发现Slave的负载确实都回归正常了,本以为息事宁人,但是过了两个小时后,新添加的Slave的负载暴增至100以上!原来的Slave服务则显示正常。大概过了两个小时,新增加的Slave的负载又回归正常了,但是又过了两个小时后,负责又飙升至100以上!于是乎,赶紧Troubleshooting!过程如下:
1)考虑到新增的server,因为内存,CPU等硬件的配置和原来数据库的server都不一样(新增的Slave比原来的Slave的内存少了一半),必然配置参数的值也会不同。所以就从MySQl的配置文件查起,如:sort_buffer_size的大小(因为考虑到有许多SQL包含排序),join_buffer_size(用于连接的缓存的大小),max_connections(最大连接数,可是通过show processlist;发现也没有超过设置的值),innodb_buffer_pool_size(确认是否为物理内存的合适比例)等等。
2)使用free -m查看内存时,发现SWAP既然使用了500MB!通过vmsata,发现si和so的值不断的变化,可以肯定的是发生了内存交换。原来是SWAP捣的蛋!
内存交换区:当操作系统因为没有足够的内存而将一些虚拟内存写到磁盘就会发生内存交换。
内存交换对MySQL性能影响是极其糟糕的。它破坏了缓存在内存的目的,并且相对于使用很小的内存做缓存,使用交换区的性能更差。MySQL和存储引擎有很多算法来区别对待内存中的数据和硬盘上的数据,因为一般都是假设内存数据访问代价更低。
因为内存交换对用户进程不可见,MySQL(或存储引擎)并不知道数据实际上已经移动到磁盘,还会以为仍然在内存中呢。
结果会导致很差的性能。例如。若存储引擎认为数据依然在内存,可能觉得为"短暂"的内存操作锁定一个全局互斥变量(例如,InnoDB缓冲池Mutex)是OK的。如果这个操作实际上引起了硬盘I/O,直到I/O操作完成前任何操作都会被挂起。这意味着内存交换比直接做硬盘I/O操作还要糟糕。
在Linux上,可以用vmstat来监控内存交换。最好查看si和so列报告的内存交换I/O活动,这比看swapd列报告的交换区利用率更重要。我们都喜欢si和so列的值为0,并且一定要保证它们低于每秒10块。
可以通过正确地配置MySQL缓冲来解决大部分内存交换问题,但是有时操作系统的虚拟内存系统还是会决定交换MySQL内存。这通常发生在操作系统看到MySQL发出了大量I/O,因此尝试增加文件缓存来保存更多数据时。如果没有足够的内存,有些东西就必须交换出去,有些可能就是MySQL本身。
有些人主张完全禁用交换文件。这样做是很危险的,因为禁用内存交换就相当于给虚拟内存设置了一个不可动摇的限制。如果MySQL需要临时使用很大一块内存,或者有很耗内存的进程运行在同一台server上(如夜间的批量任务),MySQL可能会内存溢出,崩溃,或者被操作系统kill掉。
操作系统通常允许对虚拟内存和I/O进行一些控制。最基本的方法就是修改/proc/sys/vm/swappiness为一个很小的值,如0或1。这等同于告诉内核除非虚拟内存完全满了,否则不要使用交换区。下面是如何检查这个值的例子:
$ cat /proc/sys/vm/swappiness
60
这个值显示为60,这是默认的设置(范围是0~100)。对于服务器而言这是个很糟糕的默认值。服务器应该设置为0:
$ echo 0 > /proc/sys/vm/swappiness
另一个选项是修改存储引擎怎么读取和写入数据。使用innodb_flush_method=O_DIRECT,减轻I/O压力。DIRECT I/O并不缓存,因此操作系统并不能把MySQL视为增加文件缓存的原因。这个参数只对InnoDB有效。你也可以使用大页,不参与换入换出,这对MyISAM和InnoDB都有效。
另一个选择是使用MySQL的memlock配置项,可以把MySQL锁定在内存。这可以避免交换,但是也可能带来危险:如果没有足够的可锁定内存,MySQL在尝试分配更多内存时就会崩溃。
解决问题:
第一种方法:修改系统对虚拟内存的控制
[root@mysql01 ~]# echo 0 > /proc/sys/vm/swappiness #要想永久生效,将其配置写入/etc/sysctl.conf文件中
[root@mysql01 ~]# echo "vm.swappiness=0" >> /etc/sysctl.conf
#令其立即生效
[root@mysql01 ~]# sysctl -p 第二种方法:修改innodb_flush_method参数
#注意innodb_flush_method是个全局变量,并且不支持动态修改,所以修改配置文件,重启MySQL
[root@mysql01 ~]# vim /etc/my.cnf
innodb_flush_method=O_DIRECT #添加其参数的配置,如果线上正在运行的数据库,就要先:
mysql> stop slave; #然后重启MySQL
[root@mysql01 ~]# /etc/init.d/mysqld restart
对于修改memlock配置项,不推荐。
结果:新增加的slave负载正常。swap的使用也降到了10MB的样子。
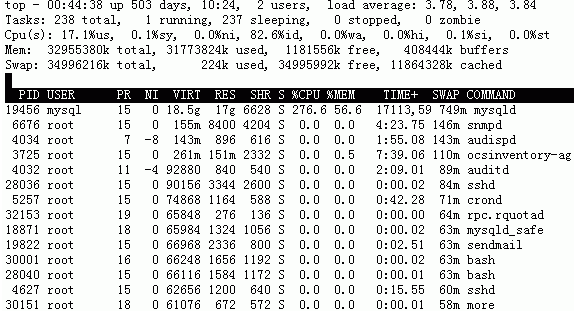
最后说下如何查看那个进程占用swap?
第一步:
[root@mysql01 ~]# top 第二步:
按大写的O 第三步:
输入小写字母p 第四步:
回车
显示的结果如下图:
python-基础案例的更多相关文章
- Python基础案例练习:制作学生信息管理系统
一.前言 学生信息管理系统,相信大家或多或少都有做过 最近看很多学生作业都是制作一个学生信息管理系统 于是,今天带大家做一个简单的学生信息管理系统 二.开发环境: 我用到的开发环境 Python 3. ...
- Python基础案例教程
一.超市买薯片 # 用户输入薯片的单价 danjia = float(input("薯片的单价")) # 用户输入购买袋数 daishu = int(input("购买的 ...
- Python基础案例1如何实现对应位置上的元素相乘/相加/相减
如何通过a b得到c 本文以“乘”引入,其他运算,类似.案例逻辑如下: a = [[1, 2, 3], [4, 5, 6], [1, 1, 1]]b = [[1, 1, 2], [1, 3, 2], ...
- Python基础+Pythonweb+Python扩展+Python选修四大专题 超强麦子学院Python35G视频教程
[保持在百度网盘中的, 可以在观看,嘿嘿 内容有点多,要想下载, 回复后就可以查看下载地址,资源收集不易,请好好珍惜] 下载地址:http://www.fu83.cc/ 感觉文章好,可以小手一抖 -- ...
- Python基础:函数式编程
一.概述 Python是一门多范式的编程语言,它同时支持过程式.面向对象和函数式的编程范式.因此,在Python中提供了很多符合 函数式编程 风格的特性和工具. 以下是对 Python中的函数式编程 ...
- Python基础:序列(列表、元组)
一.概述 列表(list)是由一个个 Python对象 组成的序列.其中,Python对象 可以是任何类型的对象,包括 Python标准类型(数值.字符串.列表.元组和字典)以及 用户自定义类型(类) ...
- Python基础(二) —— 字符串、列表、字典等常用操作
一.作用域 对于变量的作用域,执行声明并在内存中存在,该变量就可以在下面的代码中使用. 二.三元运算 result = 值1 if 条件 else 值2 如果条件为真:result = 值1如果条件为 ...
- 第一篇:python基础
python基础 python基础 本节内容 python起源 python的发展史 为什么选择python3 第一个python程序 变量定义 表达式和运算符 用户输入 流程控制 判断 流程控制 ...
- Day3 - Python基础3 函数、递归、内置函数
Python之路,Day3 - Python基础3 本节内容 1. 函数基本语法及特性 2. 参数与局部变量 3. 返回值 嵌套函数 4.递归 5.匿名函数 6.函数式编程介绍 7.高阶函数 8. ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
随机推荐
- yii url美化 urlManager组件
yii的官方文档对此的解释如下: urlSuffix 此规则使用的url后缀,默认使用CurlManger::urlSuffix,值为null.例如可以将此设置为.html,让url看起来“像”是一 ...
- iOS打包ipa select a method for export几个选项的意思
他们的意思分别为:Save for iOS App Store Deployment保存到本地 准备上传App Store 或者在越狱的iOS设备上使用,需要提供发布证书 Save for Ad Ho ...
- OC中的复合
#import <Foundation/Foundation.h> #import "Car.h" int main(int argc, const char * ar ...
- 关于tableView中tableHeaderView/tableFooterView/sectionHeader/sectionFooter/contentInset的理解
其实每个人的理解有所不同,找到最有利于自己的理解方式即可.有人把Cell,tableHeaderView,tableFooterView,sectionHeader,sectionFooter这些属性 ...
- eclipse执行单元测试报CreateProcess error=87的解决方法
原因是classpath的路径过长导致,在网上看了很多文章,发现解决方法有2种: 1.更改项目路径 或者 maven本地库的路径,减少classpath的深度. 2.由于这是eclipse自身的bug ...
- 阿里云ECS服务器(ubuntu)下基本配置以及升级git
最近需要在阿里云服务器上远程搭建调试环境,这里把遇到的问题做一下记录: 1.ECS Linux解决SSH会话连接超时问题 用SSH客户端(我使用的Xshell)连接linux服务器时,经常会出现与服务 ...
- 敏捷软件开发:原则、模式与实践——第8章 SRP:单一职责原则
第8章 SRP:单一职责原则 一个类应该只有一个发生变化的原因. 8.1 定义职责 在SRP中我们把职责定义为变化的原因.如果你想到多于一个的动机去改变一个类,那么这个类就具有多于一个的职责.同时,我 ...
- [Tomcat]如何在同一台机部署多个tomcat服务
背景:往往不知情的同学在同一台机器上部署多个tomcat会发现第二个tomcat启动会报错.而有些同学会想到可能是端口重复,然而,在server.xml改了端口还是发现不行.其实要想实现同一台机器部署 ...
- du df 查看文件和文件夹大小
http://www.cnblogs.com/benio/archive/2010/10/13/1849946.html du -h df -h du -h --max-depth=1 // 查看当 ...
- 读书笔记——Windows核心编程(2)比较字符串
1. CompareString 以符合用户语言习惯的方式,EX版本使用UNICODE int CompareString( __in LCID Locale, __in DWORD dwCmpFla ...