Reservoir Sampling 蓄水池抽样算法,经典抽样
随机读取数据,如何保证真随机是不可能的,因为计算机的随机函数是伪随机的。
但是在不考虑计算机随机函数的情况下,如何保证数据的随机采样呢?
1.系统提供的shuffle函数
C++/Java都提供有shuffle函数,可以对容器内部的数据打乱,保持随机排序。
C++:
template <class RandomAccessIterator, class URNG>
void shuffle (RandomAccessIterator first, RandomAccessIterator last, URNG&& g);
Java:
static void shuffle(List<?> list);
static void shuffle(List<?> list, Random rnd);
这些函数对数量一定的数据的随机打乱顺序,并不能处理数量不定的数据流。
2.在序列流中取一个数,如何确保随机性,即取出某个数据的概率为:1/(已读取数据个数)
假设已经读取n个数,现在保留的数是Ax,取到Ax的概率为(1/n)。
对于第n+1个数An+1,以1/(n+1)的概率取An+1,否则仍然取Ax。依次类推,可以保证取到数据的随机性。
数学归纳法证明如下:
当n=1时,显然,取A1。取A1的概率为1/1。
假设当n=k时,取到的数据Ax。取Ax的概率为1/k。
当n=k+1时,以1/(k+1)的概率取An+1,否则仍然取Ax。
(1)如果取Ak+1,则概率为1/(k+1);
(2)如果仍然取Ax,则概率为(1/k)*(k/(k+1))=1/(k+1)
所以,对于之后的第n+1个数An+1,以1/(n+1)的概率取An+1,否则仍然取Ax。依次类推,可以保证取到数据的随机性。
代码如下:
//在序列流中取一个数,保证均匀,即取出数据的概率为:1/(已读取数据个数)
void RandNum(){
int res=;
int num=;
num=;
cin>>res; int tmp;
while(cin>>tmp){
if(rand()%(num+)+>num)
res=tmp;
num++;
}
cout<<"res="<<res<<endl;
}
3.在序列流中取k个数,如何确保随机性,即取出某个数据的概率为:k/(已读取数据个数)
建立一个数组,将序列流里的前k个数,保存在数组中。(也就是所谓的"蓄水池")
对于第n个数An,以k/n的概率取An并以1/k的概率随机替换“蓄水池”中的某个元素;否则“蓄水池”数组不变。依次类推,可以保证取到数据的随机性。
数学归纳法证明如下:
当n=k是,显然“蓄水池”中任何一个数都满足,保留这个数的概率为k/k。
假设当n=m(m>k)时,“蓄水池”中任何一个数都满足,保留这个数的概率为k/m。
当n=m+1时,以k/(m+1)的概率取An,并以1/k的概率,随机替换“蓄水池”中的某个元素,否则“蓄水池”数组不变。则数组中保留下来的数的概率为:
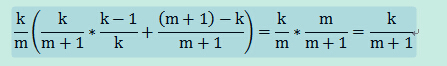
所以,对于第n个数An,以k/n的概率取An并以1/k的概率随机替换“蓄水池”中的某个元素;否则“蓄水池”数组不变。依次类推,可以保证取到数据的随机性。
代码如下:
//在序列流中取n个数,保证均匀,即取出数据的概率为:n/(已读取数据个数)
void RandKNum(int n){
int *myarray=new int[n];
for(int i=;i<n;i++)
cin>>myarray[i]; int tmp=;
int num=n;
while(cin>>tmp){
if(rand()%(num+)+<n)
myarray[rand()%n]=tmp;
} for(int i=;i<n;i++)
cout<<myarray[i]<<endl;
}
Reservoir Sampling 蓄水池抽样算法,经典抽样的更多相关文章
- Reservoir Sampling 蓄水池采样算法
https://blog.csdn.net/huagong_adu/article/details/7619665 https://www.jianshu.com/p/63f6cf19923d htt ...
- Reservoir Sampling - 蓄水池抽样问题
问题起源于编程珠玑Column 12中的题目10,其描述如下: How could you select one of n objects at random, where you see the o ...
- Reservoir Sampling - 蓄水池抽样
问题起源于编程珠玑Column 12中的题目10,其描述如下: How could you select one of n objects at random, where you see the o ...
- Reservoir Sampling - 蓄水池抽样算法&&及相关等概率问题
蓄水池抽样——<编程珠玑>读书笔记 382. Linked List Random Node 398. Random Pick Index 从n个数中随机选取m个 等概率随机函数面试题总结 ...
- leetcode398 and leetcode 382 蓄水池抽样算法
382. 链表随机节点 给定一个单链表,随机选择链表的一个节点,并返回相应的节点值.保证每个节点被选的概率一样. 进阶:如果链表十分大且长度未知,如何解决这个问题?你能否使用常数级空间复杂度实现? 示 ...
- 【算法34】蓄水池抽样算法 (Reservoir Sampling Algorithm)
蓄水池抽样算法简介 蓄水池抽样算法随机算法的一种,用来从 N 个样本中随机选择 K 个样本,其中 N 非常大(以至于 N 个样本不能同时放入内存)或者 N 是一个未知数.其时间复杂度为 O(N),包含 ...
- 【数据结构与算法】蓄水池抽样算法(Reservoir Sampling)
问题描述 给定一个数据流,数据流长度 N 很大,且 N 直到处理完所有数据之前都不可知,请问如何在只遍历一遍数据(O(N))的情况下,能够随机选取出 m 个不重复的数据. 比较直接的想法是利用随机数算 ...
- 蓄水池抽样算法 Reservoir Sampling
2018-03-05 14:06:40 问题描述:给出一个数据流,这个数据流的长度很大或者未知.并且对该数据流中数据只能访问一次.请写出一个随机选择算法,使得数据流中所有数据被选中的概率相等. 问题求 ...
- Spark MLlib之水塘抽样算法(Reservoir Sampling)
1.理解 问题定义可以简化如下:在不知道文件总行数的情况下,如何从文件中随机的抽取一行? 首先想到的是我们做过类似的题目吗?当然,在知道文件行数的情况下,我们可以很容易的用C运行库的rand函数随机的 ...
随机推荐
- ReferenceQueue的使用
转:http://www.iflym.com/index.php/java-programe/201407140001.html 1 何为ReferenceQueue 在java的引用体系中,存在着强 ...
- Adding AirDrop File Sharing Feature to Your iOS Apps
http://www.appcoda.com/ios7-airdrop-programming-tutorial/ Adding AirDrop File Sharing Feature to You ...
- iOS IPv6兼容支持和IPv6审核被拒收集整理
最近遇到一个大坑:IPv6审核被拒问题,于是广寻解决方案,先把一些可以用资料文档收集起来备用.也希望同行能用得着. 官方文档说明:Supporting IPv6 DNS64/NAT64 Network ...
- 图片大小的模式UIViewContentMode
- mysql 语句执行顺序问题
今天在写程序的时候,做分页查找时无意中,将计算数据库查询数量的语句,放到了limit之中,导致出现了bug. 所以发现以下问题: select count(1) from table limit 0, ...
- codeforces 429D
题意:给定一个数组你个数的数组a,定义sum(i, j)表示sigma(a[i],...a[j]),以及另外一个函数f(i, j) = (i - j)^2 + sum(i+1, j)^2 求最小的f( ...
- Druid的使用步骤
一.关于Druid Druid是一个JDBC组件,它包括三部分: DruidDriver 代理Driver,能够提供基于Filter-Chain模式的插件体系. DruidDataSource 高效可 ...
- Orchard Compact v1.7.2
1. 仅包留了Core中的Settings和Shapes, 及Modules, Themes和jQuery模块. 2. 添加了对Oracle的支持. 下载地址: 二进制: Orchard.Compac ...
- Reading Notes of Acceptance Test Engineering Guide
The Acceptance Test Engineering Guide will provide guidance for technology stakeholders (developers, ...
- 手机H5 web调试利器——WEINRE (WEb INspector REmote)
手机H5 web调试利器--WEINRE (WEb INspector REmote) 调试移动端页面,优先选择使用chrome浏览器调试,如果是hybrid形式的页面,可以使用chrome提供的ch ...