面试官: ShardingSphere 学一下吧
文章目录
学习之前先了解下分库分表概念:https://spiritmark.blog.csdn.net/article/details/109524713
一、ShardingSphere简介
在数据库设计时候考虑垂直分库和垂直分表。随着数据库数据量增加,不要马上考虑做水平切分,首先考虑缓存处理,读写分离,使 用索引等等方式,如果这些方式不能根本解决问题了,再考虑做水平分库和水平分表。
分库分表导致的问题:
- 跨节点连接查询问题(分页、排序)
- 多数据源管理问题
Apache ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、 Proxy和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场 景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它通过关注不变,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
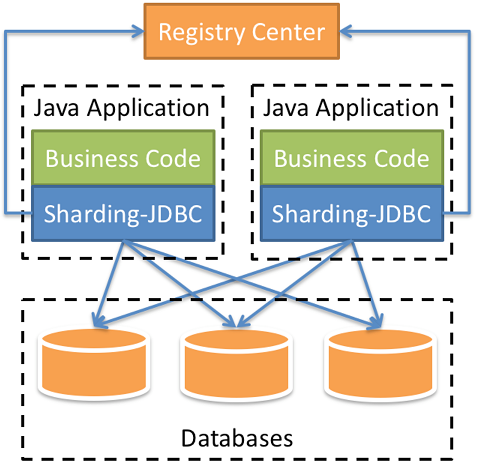
二、Sharding-JDBC
Sharding-JDBC 是轻量级的 java 框架,是增强版的 JDBC 驱动,简化对分库分表之后数据相关操作。
新建项目并添加依赖:
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-parentartifactId>
<version>2.2.1.RELEASEversion>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.1.20version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0-RC1version>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.0.5version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
dependencies>
2.1 Sharding-JDBC实现水平分表
① 按照水平分表的方式,创建数据库和数据库表
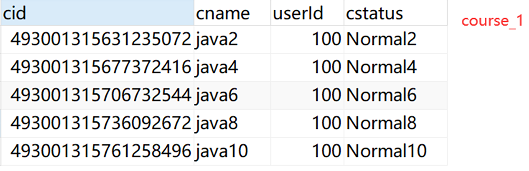
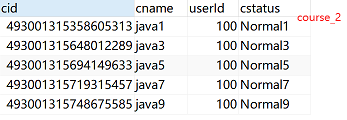
水平分表规则:如果添加 cid是偶数把数据添加 course_1,如果是奇数添加到 course_2

CREATE TABLE `course_1` (
`cid` bigint(16) NOT NULL,
`cname` varchar(255) ,
`userId` bigint(16),
`cstatus` varchar(16) ,
PRIMARY KEY (`cid`)
)
② 编写实体和 Mapper 类
@Data
public class Course {
private Long cid;
private String cname;
private Long userId;
private String cstatus;
}
@Repository
public interface CourseMapper extends BaseMapper<Course> {
}
③ 详细配置文件
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db?serverTimezone=GMT%2B8
username: root
password: 1234
sharding:
tables:
course:
actual-data-nodes: m1.course_$->{1..2}
key-generator:
column: cid
type: SNOWFLAKE
table-strategy:
inline:
shardingcolumn: cid
algorithm-expression: course_$->{cid%2+1}
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
④ 测试
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingSphereTestApplication {
@Autowired
CourseMapper courseMapper;
@Test
public void addCourse() {
for (int i = 1; i 10; i++) {
Course course = new Course();
course.setCname("java" + i);
course.setUserId(100L);
course.setCstatus("Normal" + i);
courseMapper.insert(course);
}
}
@Test
public void queryCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.eq("cid",493001315358605313L);
Course course = courseMapper.selectOne(wrapper);
System.out.println(course);
}
}
2.2 Sharding-JDBC实现水平分库
① 需求分析
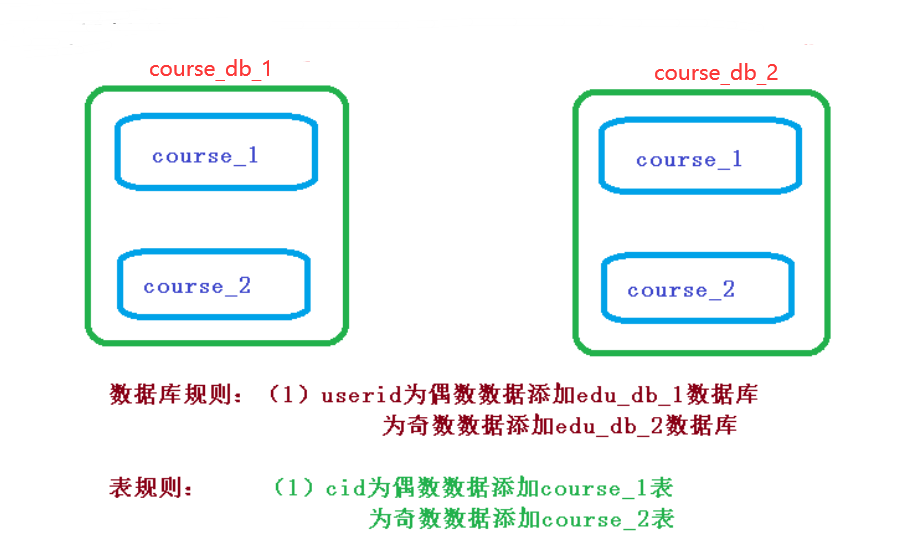
② 创建数据库和表
③ 详细配置文件
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_2?serverTimezone=GMT%2B8
username: root
password: 1234
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_3?serverTimezone=GMT%2B8
username: root
password: 1234
sharding:
tables:
course:
actual-data-nodes: m$->{1..2}.course_$->{1..2}
key-generator:
column: cid
type: SNOWFLAKE
database-strategy:
inline:
sharding-column: userId
algorithm-expression: m$->{userId%2+1}
table-strategy:
inline:
sharding-column: cid
algorithm-expression: course_$->{cid%2+1}
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
④ 测试代码
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingSphereTestApplication {
@Autowired
CourseMapper courseMapper;
@Test
public void addCourse() {
for (int i = 1; i 20; i++) {
Course course = new Course();
course.setCname("java" + i);
int random = (int) (Math.random() * 10);
course.setUserId(100L + random);
course.setCstatus("Normal" + i);
courseMapper.insert(course);
}
}
@Test
public void queryCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.eq("cid", 493001315358605313L);
Course course = courseMapper.selectOne(wrapper);
System.out.println(course);
}
}
查询实际对应的 SQL:

2.3 Sharding-JDBC操作公共表
公共表 :
- 存储固定数据的表,表数据很少发生变化,查询时候经常进行关联
- 在每个数据库中创建出相同结构公共表
① 思路分析
② 在对应数据库创建公共表 t_udict,并创建对应实体和 Mapper``
CREATE TABLE `t_udict` (
`dict_id` bigint(16) NOT NULL,
`ustatus` varchar(16) ,
`uvalue` varchar(255),
PRIMARY KEY (`dict_id`)
)
③ 详细配置文件
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_2?serverTimezone=GMT%2B8
username: root
password: 1234
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_3?serverTimezone=GMT%2B8
username: root
password: 1234
sharding:
tables:
course:
actual-data-nodes: m$->{1..2}.course_$->{1..2}
key-generator:
column: cid
type: SNOWFLAKE
database-strategy:
inline:
sharding-column: userId
algorithm-expression: m$->{userId%2+1}
table-strategy:
inline:
sharding-column: cid
algorithm-expression: course_$->{cid%2+1}
t_udict:
key-generator:
column: dict_id
type: SNOWFLAKE
broadcast-tables: t_udict
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
④ 进行测试
经测试:数据插入时会在每个库的每张表中插入,删除时也会删除所有数据。
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingSphereTestApplication {
@Autowired
UdictMapper udictMapper;
@Test
public void addUdict() {
Udict udict = new Udict();
udict.setUstatus("a");
udict.setUvalue("已启用");
udictMapper.insert(udict);
}
@Test
public void deleteUdict() {
QueryWrapper<Udict> wrapper = new QueryWrapper<>();
wrapper.eq("dict_id", 493080009351626753L);
udictMapper.delete(wrapper);
}
}
2.4 Sharding-JDBC实现读写分离
为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。也就是,第一台数据库服务器是对外提供增删改业务的生产服务器;第二台数据库服务器主要进行读的操作。
Sharding-JDBC通过 sql语句语义分析,实现读写分离过程,不会做数据同步,数据同步通常数据库集群间会自动同步。
详细配置文件:
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m0,s0
m0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db?serverTimezone=GMT%2B8
username: root
password: 1234
s0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3307/course_db?serverTimezone=GMT%2B8
username: root
password: 1234
masterslave:
master-data-source-name: m0
slave-data-source-names: s0
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
经过测试:增删改操作都是会通过 master数据库,同时 master数据库会同步数据给 slave数据库;查操作都是通过 slave数据库.
三、Sharding-Proxy
Sharding-Proxy定位为 透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持, 目前仅 MySQL和 PostgreSQL版本。
Sharding-Proxy是独立应用,需要安装服务,进行分库分表或者读写分离配置,启动使用。
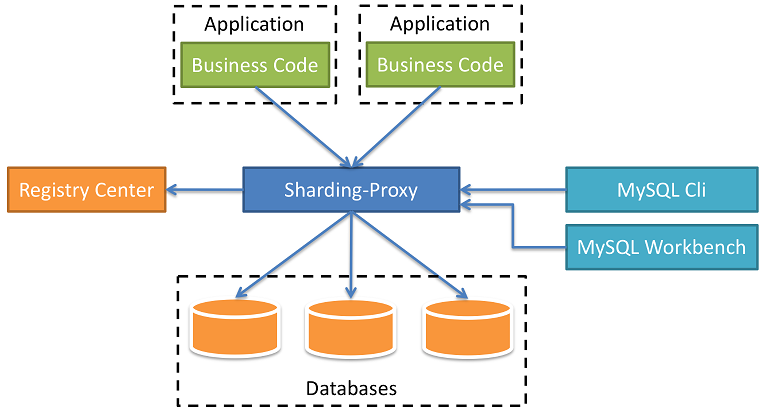
Sharding-proxy的使用参考:Sharding-Proxy的基本使用。
微信搜一搜 : 全栈小刘 ,获取文章 pdf 版本
面试官: ShardingSphere 学一下吧的更多相关文章
- 一些Java中不为人知的特殊方法,学完后面试官可能都没你知道的多!
如果你用过反射并且执行过getDeclaredMethods方法的话,你可能会感到很吃惊.你会发现出现了很多源代码里没有的方法.如果你看一下这些方法的修饰符的话,可能会发现里面有些方法是volatil ...
- 学完了这篇JVM,面试官真拿我没办法了!
在我们面试中经常会遇到面试官问一些有关JVM的问题,下面我大概从运行时数据域.类加载机制.类加载器.垃圾收集器.垃圾收集算法.JVM堆内存模型.JVM内存结构.JVM调优等几个方面来讲一下JVM. 一 ...
- 关键词:ACM & 大小端 & 面试官
关于“ACM” fender0107401 :面试了一个在ACM拿过奖的人 我问了他几个问题: 读取数组中的一个元素,计算复杂度是多少,回答不清楚. 往链表里面存一个数,不排序的情况下,计算复杂度是多 ...
- 走向DBA[MSSQL篇] 面试官最喜欢的问题 ----索引+C#面试题客串
原文:走向DBA[MSSQL篇] 面试官最喜欢的问题 ----索引+C#面试题客串 对大量数据进行查询时,可以应用到索引技术.索引是一种特殊类型的数据库对象,它保存着数据表中一列或者多列的排序结果,有 ...
- 如何写出面试官欣赏的Java单例
单例模式是一种常用的软件设计模式.在它的核心结构中只包含一个被称为单例的特殊类.通过单例模式可以保证系统中一个类只有一个实例. 今天我们不谈单例模式的用途,只说一说如果在面试的时候面试官让你敲一段代码 ...
- 以技术面试官的经验分享毕业生和初级程序员通过面试的技巧(Java后端方向)
本来想分享毕业生和初级程序员如何进大公司的经验,但后来一想,人各有志,有程序员或许想进成长型或创业型公司或其它类型的公司,所以就干脆来分享些提升技能和通过面试的技巧,技巧我讲,公司你选,两厢便利. 毕 ...
- 图解Java线程的生命周期,看完再也不怕面试官问了
文章首发自个人微信公众号: 小哈学Java https://www.exception.site/java-concurrency/java-concurrency-thread-life-cycle ...
- Tomcat相关面试题,看这篇就够了!保证能让面试官颤抖!
Tomcat相关的面试题出场的几率并不高,正式因为如此,很多人忽略了对Tomcat相关技能的掌握. 这次整理了Tomcat相关的系统架构,介绍了Server.Service.Connector.Con ...
- 【长文】Google面试官分步解析自己泄漏前的面试题,超多干货和建议
本文翻译自Google工程师/面试官Alex Golec的文章:Google Interview Questions Deconstructed: The Knight's Dialer:翻译:实验楼 ...
随机推荐
- FL Studio 插件使用技巧——Fruity Reeverb 2 (上)
许多学习FL的用户会发现,自己在听大师的电子音乐作品时都能感受到他们的音乐有一股强大的空间感,有时还能感知到深邃的意境.不少人会因此而疑惑:为什么出自我们之手的音乐就没有这样的效果呢?我们的音乐里到底 ...
- 【ACwing 100】InDec序列——差分
(题面来自AcWing) 给定一个长度为 n 的数列 a1,a2,-,an,每次可以选择一个区间 [l,r],使下标在这个区间内的数都加一或者都减一. 求至少需要多少次操作才能使数列中的所有数都一样, ...
- Java-Netty前菜-NIO
NIO NIO主要有三个核心部分组成: buffer缓冲区 Channel管道 Selector选择器 在NIO中并不是以流的方式来处理数据的,而是以buffer缓冲区和Channel管道配合使用来处 ...
- C语言讲义——dll调用
DLL:Dynamic Link Library,动态链接库.一个应用程序可使用多个DLL文件,一个DLL文件也可以被不同的应用程序使用. 先新建一个dll项目 再创建C项目进行调用 #include ...
- Django 的模板语法之过滤器
后端朝前端页面传递数据的方式 # 第一种 return render(request,'index.html',{'n':n}) # 第二种 return render(request,'index. ...
- oracle 导入导出表,库
Exp/Imp是oracle备份数据的两个命令行工具 1.本地数据库导入导出 1.导出 (运行---cmd中操作) exp 用户名/密码@数据库实例名file=本地存放路径 eg: exp jnjp/ ...
- 浅尝 Elastic Stack (五) Logstash + Beats + Kafka
在 Elasticsearch.Kibana.Beats 安装 中讲到推荐架构: 本文基于 Logstash + Beats 读取 Spring Boot 日志 将其改为上述架构 如果没有安装 Kaf ...
- Spring Boot 中使用 Spring Security, OAuth2 跨域问题 (自己挖的坑)
使用 Spring Boot 开发 API 使用 Spring Security + OAuth2 + JWT 鉴权,已经在 Controller 配置允许跨域: @RestController @C ...
- git全流程
服务器:Ubuntu 使用git前准备工作: 下载git之前先更新: apt-get update 安装git: apt-get install git 创建本地仓库: mkdir test git初 ...
- cf div2 round 688 题解
爆零了,自闭了 小张做项目入职字节 小李ak wf入职ms 我比赛爆零月薪3k 我们都有光明的前途 好吧,这场感觉有一点难了,昨天差点卡死在B上,要不受O爷出手相救我就boom zero了 第一题,看 ...