Flink处理函数实战之四:窗口处理
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
Flink处理函数实战系列链接
- 深入了解ProcessFunction的状态操作(Flink-1.10);
- ProcessFunction;
- KeyedProcessFunction类;
- ProcessAllWindowFunction(窗口处理);
- CoProcessFunction(双流处理);
本篇概览
本文是《Flink处理函数实战》系列的第四篇,内容是学习以下两个窗口相关的处理函数:
- ProcessAllWindowFunction:处理每个窗口内的所有元素;
- ProcessWindowFunction:处理指定key的每个窗口内的所有元素;
关于ProcessAllWindowFunction
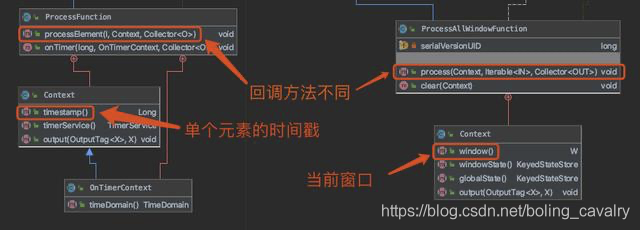
- ProcessAllWindowFunction和《Flink处理函数实战之二:ProcessFunction类》中的ProcessFunction类相似,都是用来对上游过来的元素做处理,不过ProcessFunction是每个元素执行一次processElement方法,ProcessAllWindowFunction是每个窗口执行一次process方法(方法内可以遍历该窗口内的所有元素);
- 用类图对比可以更形象的认识差别,下图左侧是ProcessFunction,右侧是ProcessAllWindowFunction:
关于ProcessWindowFunction
- ProcessWindowFunction和KeyedProcessFunction类似,都是处理分区的数据,不过KeyedProcessFunction是每个元素执行一次processElement方法,而ProcessWindowFunction是每个窗口执行一次process方法(方法内可以遍历该key当前窗口内的所有元素);
- 用类图对比可以更形象的认识差别,下图左侧是KeyedProcessFunction,右侧是ProcessWindowFunction:
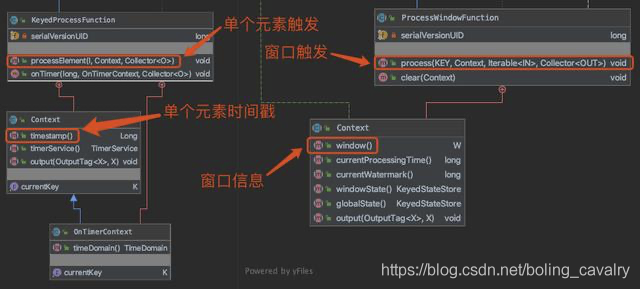
- 另外还一个差异:ProcessWindowFunction.process方法的入参就有分区的key值,而KeyedProcessFunction.processElement方法的入参没有这个参数,而是需要Context.getCurrentKey()才能取到分区的key值;
注意事项
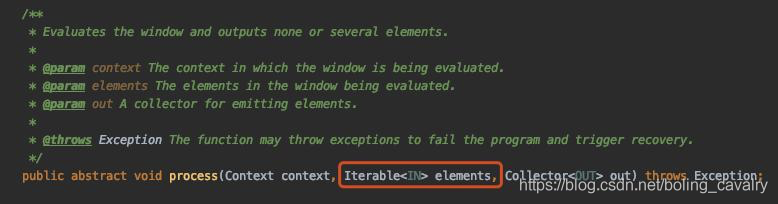
窗口处理函数的process方法,以ProcessAllWindowFunction为例,如下图红框所示,其入参可以遍历当前窗口内的所有元素,这意味着当前窗口的所有元素都保存在堆内存中,所以请在设计阶段就严格控制窗口内元素的内存使用量,避免耗尽TaskManager节点的堆内存:
接下来通过实战学习ProcessAllWindowFunction和ProcessWindowFunction;
版本信息
- 开发环境操作系统:MacBook Pro 13寸, macOS Catalina 10.15.4
- 开发工具:IntelliJ IDEA 2019.3.2 (Ultimate Edition)
- JDK:1.8.0_121
- Maven:3.3.9
- Flink:1.9.2
源码下载
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
这个git项目中有多个文件夹,本章的应用在flinkstudy文件夹下,如下图红框所示:
如何实战ProcessAllWindowFunction
接下来通过以下方式验证ProcessAllWindowFunction功能:
- 每隔1秒发出一个Tuple2<String, Integer>对象,对象的f0字段在aaa和bbb之间变化,f1字段固定为1;
- 设置5秒的滚动窗口;
- 自定义ProcessAllWindowFunction扩展类,功能是统计每个窗口内元素的数量,将统计结果发给下游算子;
- 下游算子将统计结果打印出来;
- 核对发出的数据和统计信息,看是否一致;
开始编码
- 继续使用《Flink处理函数实战之二:ProcessFunction类》一文中创建的工程flinkstudy;
- 新建ProcessAllWindowFunctionDemo类,如下:
package com.bolingcavalry.processwindowfunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessAllWindowFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.text.SimpleDateFormat;
import java.util.Date;
public class ProcessAllWindowFunctionDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 使用事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
// 并行度为1
env.setParallelism(1);
// 设置数据源,一共三个元素
DataStream<Tuple2<String,Integer>> dataStream = env.addSource(new SourceFunction<Tuple2<String, Integer>>() {
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
for(int i=1; i<Integer.MAX_VALUE; i++) {
// 只有aaa和bbb两种name
String name = 0==i%2 ? "aaa" : "bbb";
// 使用当前时间作为时间戳
long timeStamp = System.currentTimeMillis();
// 将数据和时间戳打印出来,用来验证数据
System.out.println(String.format("source,%s, %s\n",
name,
time(timeStamp)));
// 发射一个元素,并且带上了时间戳
ctx.collectWithTimestamp(new Tuple2<String, Integer>(name, 1), timeStamp);
// 每发射一次就延时1秒
Thread.sleep(1000);
}
}
@Override
public void cancel() {
}
});
// 将数据用5秒的滚动窗口做划分,再用ProcessAllWindowFunction
SingleOutputStreamOperator<String> mainDataStream = dataStream
// 5秒一次的滚动窗口
.timeWindowAll(Time.seconds(5))
// 统计当前窗口内的元素数量,然后把数量、窗口起止时间整理成字符串发送给下游算子
.process(new ProcessAllWindowFunction<Tuple2<String, Integer>, String, TimeWindow>() {
@Override
public void process(Context context, Iterable<Tuple2<String, Integer>> iterable, Collector<String> collector) throws Exception {
int count = 0;
// iterable可以访问当前窗口内的所有数据,
// 这里简单处理,只统计了元素数量
for (Tuple2<String, Integer> tuple2 : iterable) {
count++;
}
// 将当前窗口的起止时间和元素数量整理成字符串
String value = String.format("window, %s - %s, %d\n",
// 当前窗口的起始时间
time(context.window().getStart()),
// 当前窗口的结束时间
time(context.window().getEnd()),
// 当前key在当前窗口内元素总数
count);
// 发射到下游算子
collector.collect(value);
}
});
// 打印结果,通过分析打印信息,检查ProcessWindowFunction中可以处理所有key的整个窗口的数据
mainDataStream.print();
env.execute("processfunction demo : processallwindowfunction");
}
public static String time(long timeStamp) {
return new SimpleDateFormat("hh:mm:ss").format(new Date(timeStamp));
}
}
- 关于ProcessAllWindowFunctionDemo,有几点需要注意:
a. 滚动窗口设置用timeWindowAll方法;
b. ProcessAllWindowFunction的匿名子类的process方法中,context.window().getStart()方法可以取得当前窗口的起始时间,getEnd()方法可以取得当前窗口的结束时间;
- 编码结束,执行ProcessAllWindowFunctionDemo类验证数据,如下图,检查其中一个窗口的元素详情和ProcessAllWindowFunction执行结果,可见符合预期:

- ProcessAllWindowFunction已经了解,接下来尝试ProcessWindowFunction;
如何实战ProcessWindowFunction
接下来通过以下方式验证ProcessWindowFunction功能:
- 每隔1秒发出一个Tuple2<String, Integer>对象,对象的f0字段在aaa和bbb之间变化,f1字段固定为1;
- 以f0字段为key进行分区;
- 分区后的数据进入5秒的滚动窗口;
- 自定义ProcessWindowFunction扩展类,功能之一是统计每个key在每个窗口内元素的数量,将统计结果发给下游算子;
- 功能之二是在更新当前key的元素总量,然后在状态后端(backend)保存,这是验证KeyedStream在处理函数中的状态读写能力;
- 下游算子将统计结果打印出来;
- 核对发出的数据和统计信息(每个窗口的和总共的分别核对),看是否一致;
开始编码
- 新建ProcessWindowFunctionDemo.java:
package com.bolingcavalry.processwindowfunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.text.SimpleDateFormat;
import java.util.Date;
public class ProcessWindowFunctionDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 使用事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
// 并行度为1
env.setParallelism(1);
// 设置数据源,一共三个元素
DataStream<Tuple2<String,Integer>> dataStream = env.addSource(new SourceFunction<Tuple2<String, Integer>>() {
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
int aaaNum = 0;
int bbbNum = 0;
for(int i=1; i<Integer.MAX_VALUE; i++) {
// 只有aaa和bbb两种name
String name = 0==i%2 ? "aaa" : "bbb";
//更新aaa和bbb元素的总数
if(0==i%2) {
aaaNum++;
} else {
bbbNum++;
}
// 使用当前时间作为时间戳
long timeStamp = System.currentTimeMillis();
// 将数据和时间戳打印出来,用来验证数据
System.out.println(String.format("source,%s, %s, aaa total : %d, bbb total : %d\n",
name,
time(timeStamp),
aaaNum,
bbbNum));
// 发射一个元素,并且戴上了时间戳
ctx.collectWithTimestamp(new Tuple2<String, Integer>(name, 1), timeStamp);
// 每发射一次就延时1秒
Thread.sleep(1000);
}
}
@Override
public void cancel() {
}
});
// 将数据用5秒的滚动窗口做划分,再用ProcessWindowFunction
SingleOutputStreamOperator<String> mainDataStream = dataStream
// 以Tuple2的f0字段作为key,本例中实际上key只有aaa和bbb两种
.keyBy(value -> value.f0)
// 5秒一次的滚动窗口
.timeWindow(Time.seconds(5))
// 统计每个key当前窗口内的元素数量,然后把key、数量、窗口起止时间整理成字符串发送给下游算子
.process(new ProcessWindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {
// 自定义状态
private ValueState<KeyCount> state;
@Override
public void open(Configuration parameters) throws Exception {
// 初始化状态,name是myState
state = getRuntimeContext().getState(new ValueStateDescriptor<>("myState", KeyCount.class));
}
@Override
public void process(String s, Context context, Iterable<Tuple2<String, Integer>> iterable, Collector<String> collector) throws Exception {
// 从backend取得当前单词的myState状态
KeyCount current = state.value();
// 如果myState还从未没有赋值过,就在此初始化
if (current == null) {
current = new KeyCount();
current.key = s;
current.count = 0;
}
int count = 0;
// iterable可以访问该key当前窗口内的所有数据,
// 这里简单处理,只统计了元素数量
for (Tuple2<String, Integer> tuple2 : iterable) {
count++;
}
// 更新当前key的元素总数
current.count += count;
// 更新状态到backend
state.update(current);
// 将当前key及其窗口的元素数量,还有窗口的起止时间整理成字符串
String value = String.format("window, %s, %s - %s, %d, total : %d\n",
// 当前key
s,
// 当前窗口的起始时间
time(context.window().getStart()),
// 当前窗口的结束时间
time(context.window().getEnd()),
// 当前key在当前窗口内元素总数
count,
// 当前key出现的总数
current.count);
// 发射到下游算子
collector.collect(value);
}
});
// 打印结果,通过分析打印信息,检查ProcessWindowFunction中可以处理所有key的整个窗口的数据
mainDataStream.print();
env.execute("processfunction demo : processwindowfunction");
}
public static String time(long timeStamp) {
return new SimpleDateFormat("hh:mm:ss").format(new Date(timeStamp));
}
static class KeyCount {
/**
* 分区key
*/
public String key;
/**
* 元素总数
*/
public long count;
}
}
- 上述代码有几处需要关注:
a. 静态类KeyCount.java,是用来保存每个key元素总数的数据结构;
b. timeWindow方法设置了市场为5秒的滚动窗口;
c. 每个Tuple2元素以f0为key进行分区;
d. open方法对名为myState的自定义状态进行注册;
e. process方法中,state.value()取得当前key的状态,tate.update(current)更新当前key的状态;
- 接下来运行ProcessWindowFunctionDemo类检查数据,如下图,process方法内,对窗口内元素的统计和数据源打印的一致,并且从backend取得的总数在累加后和数据源的统计信息也一致:

至此,处理函数中窗口处理相关的实战已经完成,如果您也在学习Flink的处理函数,希望本文能给您一些参考;
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
Flink处理函数实战之四:窗口处理的更多相关文章
- Flink处理函数实战之五:CoProcessFunction(双流处理)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之一:深入了解ProcessFunction的状态(Flink-1.10)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之二:ProcessFunction类
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之三:KeyedProcessFunction类
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之四:自定义
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之三:cassandra3
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之一:初探
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之二:kafka
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive常用函数 wordCount--Hive窗口函数1.1.1 聚合开窗函数聚合开窗函数实战
第三天笔记 第三天笔记 SQL练习Hive 常用函数关系运算数值计算条件函数日期函数重点!!!字符串函数Hive 中的wordCount1.1 Hive窗口函数1.1.1 聚合开窗函数聚合开窗函数实战 ...
随机推荐
- matplotlib直方图
import matplotlib.pyplot as plt import matplotlib as mpl from matplotlib.font_manager import FontPro ...
- C# 微支付 JSAPI支付方式 V3.3.6版本
<script type="text/javascript">//结算 (订单号) function PayClearing(num) { $.ajax({ type: ...
- 微信小程序学习心得
我们写小程序时都要跳转页面的,也会有底部导航来进行切换 这个时候就要介绍下窗口是怎样配置的 要在app.json文件里写一个tabBer对象 里面在定义一个list数组里面放我们定义的几个需要切换的页 ...
- 逻辑运算 - js笔记
&& 与 || undefined null NaN "" 0 => false 在 && 中,当第一个值为false停止运行,返回该值,即遇 ...
- js 实现吸顶效果 || 小程序的吸顶效果
小程序吸顶效果 <!--index.wxml--> <view class="container"> <view class='outside-img ...
- Zotero使用教程
之前一直想有一个管理文献的好工具,但囿于麻烦都没有去做.最近需要阅读大量的文献,便重新拾起了这个念头,在几经搜索后,选定了Zotero作为文献管理工具. 至于为什么选择这个软件,我也许并说不清,网上有 ...
- VMware Workstation Pro 虚拟机安装
1.简介 虚拟机指通过软件莫比的具体有完整硬件系统功能的.运行在一个完全隔离环境中的完整计算机系统. 我们可以通过虚拟机软件,可以在一台物理计算机模拟出一台或多台虚拟的计算机,这些虚拟的计算机完全就像 ...
- mysql自动化建表脚本
主脚本 配置文件 执行结果 主脚本内容 由于在awk中用常规方法无法转译单引号,所以用了单引号的八进制编码进行转译代替\047 等价于 ' [root@hadoop01 data]# cat crea ...
- java开发-前后端分离
众所周知,做java开发是后端的开发,我们时常与前端打交道,但更加注重后端代码的实现,前台的页面都是由前端开发人员做的,那么,是怎么做到前后端分离的呢? 首先,是后端的开发, 在mapper层:Stu ...
- Java学习的第五天
1.值域转化的规则:值域小的类型可以自动转化成值域大的类型,值域大的类型可以强行转化成值域小的类型,但要注意精度,除了基本类型可以转换,引用类型之间也可以转换. 引用类型可以是类,借口,数组. 常见的 ...