Java 重要知识点,踩过的坑
(1),关于 LinkedHashMap TreeMap HashMap 之间的区别:
HashMap 是无序的,LinkedHashMap 由于内部维护了一个记录的链表,数据操作的前后顺序都会在链表上下节点保存着;
而TreeMap 内部的数据是有序的
分析如下:
.LinkedHashMap 我们看类结构上是实现了HashMap ,在添加元素的时候,在实现添加put 方法时候,重写了其newNode 方法,如下: 我们看HashMap newNode 方法: 就是普通的创建了一个节点对象 // Create a regular (non-tree) node
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
} 我们再看LinkedHashMap 重写的newNode 方法:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
} //链表操作
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
我们看一看TreeMap 结构: 对于数据都要进行比较,然后再判断放到数的左边还是右边,然后进行红黑树自旋
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
(2).java 类加载器,以及委托机制
java 类加载器分为引导,扩展,系统 三类类加载器 引导类加载器主要负责加载java 类库下的包,扩展类加载器主要负责加载扩展包(e x t),系统类加载器主要负责加载我们的Java 文件 以及第三方j a r包
双亲委托机制原理:
1.当系统加载器加载一个class 的时候,他自己不会自己器加载这个类,而是把这个类加载的请求交给他的父加载器(扩展加载器)ExtClassLoader 去完成;
2.到了扩展加载器加载时候,他首先也不会自己去尝试加载这个类,而是又把这个类加载请求交给你它的父加载器(引导加载器)去完成
3.然后到了引导加载器加载的时候,如果加载未找到,则会让它下级ExtClassLoader 加载;
4.如果ExtClassLoader也加载失败,则就使用系统加载器进行加载,系统记载器如果没有发现,就会抛出ClassNotFound 异常
为什么会设计这种双亲委托机制进行类的加载:
为了安全,为了防止外部恶意进行自定义java 类库的类,达到安全的作用以及优先级作用
(3).线程池:
创建线程池又如下参数需要进行配置:
corePoolSize:核心线程数
maximumPoolSize:最大线程数
keepAliveTime:线程存活的时间
workQueue:任务队列
threadFactory:线程工厂
handler:在队列满了以及线程数已经到达了最大线程数的时候,触发此handler
线程池要与数据库连接池要区别开,线程池这里的实现是如果我的Runnable 任务能够被队列一直容纳的话,线程的数量始终是核心线程的数量,只有在队列满了
之后,才会进行创建新的线程<最大线程数;这个是要注意的;
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {....}
举个例子:如下代码,只会创建两个核心线程,剩余的4个任务是放到了LinkedBlockingQueue 中;
public static void main(String[] args) {
/**
* 核心线程为2
* 最大线程为6
* LinkedBlockingQueue 容纳 Integer.MAX_VALUE个任务
*/
ThreadPoolExecutor pool = new ThreadPoolExecutor(2, 6,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
pool.submit(()-> fs());
pool.submit(()-> fs());
pool.submit(()-> fs());
pool.submit(()->fs());
pool.submit(()->fs());
pool.submit(()->fs());
pool.submit(()->fs());
pool.submit(()->fs());
}
public static void fs(){
try {
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName());
}catch (Exception E){
}
}
(4).maven 重要的使用:
1.查看项目完整的依赖数:mvn dependency:tree -Dverbose
2.查看依赖树中包含某个groupId和artifactId的依赖链 mvn dependency:tree -Dverbose -Dincludes=com.alibaba:
(5).git常用命令:
场景:在切换分支,想要保存原有分支修改未提交的文件;在切换回来的时候还原
git stash save "name": 将未提交的文件保存到仓库里并命名;
git stash list :查看仓库保存的文件;
git stash pop stash@{0} :仓库的文件被弹出恢复根据stash list 索引
git 版本会退:
//查看日志
git reflog --pretty=oneline
git reset --hard 目标版本号
(6).SL4J 日志框架体系(使用slf4j 进行统一日志管理):
1. SLF4J 是Java 日志的门面,用于统一管理java 混乱的日志框架与项目日志框架不统一的问题,并不提供日志系统的统一实现;
2.SLF4J 的具体实现有slf4j-simple、logback,要使用log4j 需要使用slf4j-log4j12来实现slf4j;
3.jcl-over-slf4j ,log4j-over-slf4j, jul-to-slf4j 用于替换commons-logging, log4j, java util logging 原有实现;
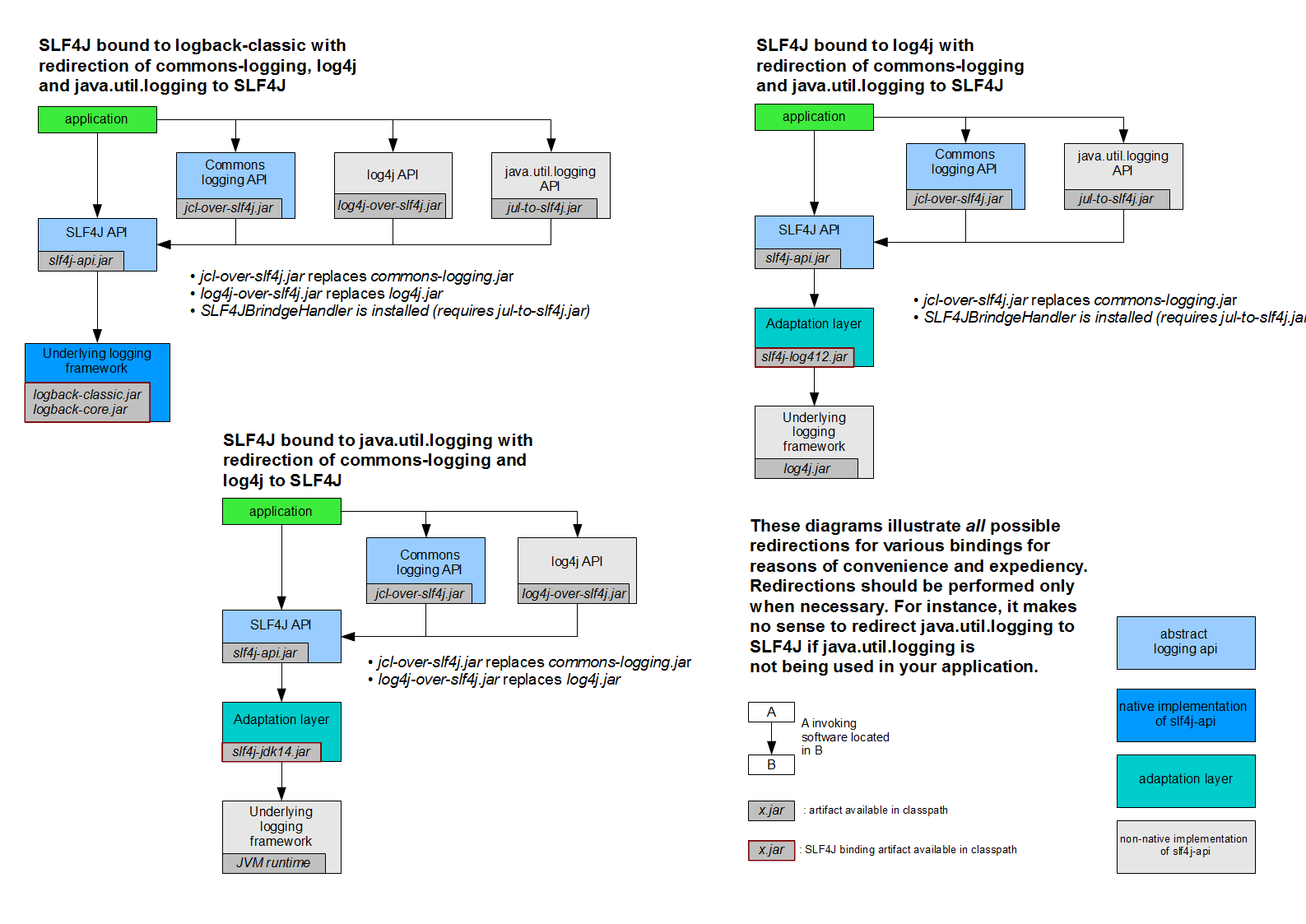
(7) .java 默认的环境变量:
java默认的系统变量有下面这些: java.version:java运行时版本 java.vendor:java运行时环境供应商 java.vendor.url:java供应商url java.home;java安装目录 java.vm.specification.version:java虚拟机规范版本 java.vm.specification.vendor:java虚拟机规范供应商 java.vm.specification.name:java虚拟机规范名称 java.vm.version:java虚拟机实现版本 java.vm.vendor:java虚拟机实现供应商 java.vm.name:java虚拟机实现名称 java.specification.version:java运行时环境规范版本 java.specification.vendor:java运行时环境规范运营商 java.specification.name:java运行时环境规范名称 java.class.version:java类格式版本 java.class.path:java类路径 java.library.path:加载库是搜索的路径列表 java.io.tmpdir:默认的临时文件路径 java.compiler:要使用的JIT编译器的路径 java.ext.dirs:一个或者多个扩展目录的路径 os.name:操作系统的名称 os.arch:操作系统的架构 os.version:操作系统的版本 file.separator:文件分隔符(在unix系统中是“/”) path.separator:路径分隔符(在unix系统中是“:”) line.separator:行分隔符(在unix系统中是“/n”) user.name:用户的账户名称 user.home:用户的主目录 user.dir:用户的当前工作目录
Java 重要知识点,踩过的坑的更多相关文章
- java 反射的踩的一个坑
今天工作的时候用到了一个反射.其业务简单描述为:系统启动时将需要定时调用的方法签名保存到数据库中,开启线程定时从数据库中读取对应的方法签名,通过反射生成实例后调用方法.完成一定的定时任务. 写到的方法 ...
- 踩过无数坑实现的哈夫曼压缩(JAVA)
最近可能又是闲着没事干了,就想做点东西,想着还没用JAVA弄过数据结构,之前搞过算法,就试着写写哈夫曼压缩了. 本以为半天就能写出来,结果,踩了无数坑,花了整整两天时间!!orz...不过这次踩坑,算 ...
- "开发路上踩过的坑要一个个填起来————持续更新······(7月30日)"
欢迎转载,请注明出处! https://gii16.github.io/learnmore/2016/07/29/problem.html 踩过的坑及解决方案记录在此篇博文中! 个人理解,如有偏颇,欢 ...
- 初学spring boot踩过的坑
一.搭建spring boot环境 maven工程 pom文件内容 <project xmlns="http://maven.apache.org/POM/4.0.0" xm ...
- elasticsearch2.3.3集群搭建踩到的坑
本文来自我的github pages博客http://galengao.github.io/ 即www.gaohuirong.cn 摘要: 作者原来搭建的环境是0.95版本 现在升级到2.3.3版本, ...
- wrk 使用记录及踩过的坑
wrk是什么?https://github.com/wg/wrk wrk 是一个非常小巧高效的开源性能测试工具,支持lua脚本来创建复杂的测试场景.wrk 的一个很好的特性就是能用很少的线程压出很大的 ...
- 在Mac osx使用ADT Bundle踩过的坑
前言 本篇博客整理一下笔者在Mac下使用ADT Bundle踩过的坑,Google现在也不支持Eclipse了,开发者也到了抛弃Eclipse的时候,但考虑到大部分Java的开发者还是比较习惯与Ecl ...
- 那些移动端web踩过的坑
原文链接:https://geniuspeng.github.io/2017/08/24/mobile-issues/ 扔了N久,还是捡回来了.好好弄一下吧.刚工作的时候挺忙的,后来不那么忙了,但是变 ...
- 转载:appium踩过的坑
原文地址:http://blog.csdn.net/wirelessqa/article/details/29188665 自己的操作:由于在window上安装appium时,报各种错误:所以选择在u ...
- 初学Java 精简知识点总结
面对Java丰富的知识资料,很多初学者难免觉得迷惘,该学什么,怎么去学?下面给大家讲Java基础知识做了精简总结,来帮助你梳理学习思路,赶快看看吧! 方法/步骤1 对象的初始化(1) 非静态对象的初始 ...
随机推荐
- linux服务器安装svn并上传项目
一.安装svn (1)安装svn服务器: yum install subversion (2)查看版本(随自己意愿): svnserve --version 二.创建svn仓库并配置 (1)创建svn ...
- QT release版QAudioDeviceInfo获取不到音频设备,而debug版可以获取到
新添加了两个模块:QCharts和Multimedia 但自己没有重新打包更新里面的库文件什么的... 坑爹... 害我找了这么久... 解决办法: 方法一: 将Qt安装目录下的plugins文件夹中 ...
- python 之 前端开发( DOM操作)
11.47 DOM操作 查找节点: 11.471 直接查找 document.getElementById //根据ID获取唯一一个标签 document.getElementsByClassName ...
- WUSTOJ 1315: 杜学霸和谭女神(Java)
题目链接:
- 【Linux】一步一步学Linux——Unix发展史(02)
目录 00. 目录 01. 请参考Unix传奇 02. 03. 00. 目录 @ 本博客后面会更新 01. 请参考Unix传奇 链接: https://coolshell.cn/articles/23 ...
- MySQL容量规划和性能测试
性能容量关键指标: 每秒tps,峰值tps 基础数据量,日均增长数据量 最大连接数 内存分配 IOPS 重点关注指标: 业务指标: 每秒并发用户请求.每秒订单数.用户请求响应时长 折算成性能指标: q ...
- 运输计划[二分答案 LCA 树上差分]
也许更好的阅读体验 \(\mathcal{Description}\) 原题链接 概括一下题意 给一颗有\(n\)个点带边权的树,有\(m\)个询问,每次询问\(u,v\)两点间的权值和,你可以将树中 ...
- ubuntu配置fastdfs+Nginx
全程参考主线来自:https://blog.csdn.net/xiaoxie762457/article/details/80690841(文中图片失效不造成影响) Nginx安装主要参考:https ...
- wannafly 挑战赛10 小H和游戏
题解: 先利用dfs找出各个节点之间的关系.然后利用一个sum[i][j] 数组 sum[i][0] 表示i这个节点收到影响的次数 sum[i][1]表示i这个节点的儿子们收到影响的次数 sum[i ...
- vs项目模板创建和使用
一.使用dotnet命令创建(适用于.NET Core,可以创建包含任意数量个项目的模板,但不会出现在vs的新建项目模板中) 官方文档:https://docs.microsoft.com/zh-cn ...