在Ubuntu里搭建spark环境
注意:1.搭建环境:Ubuntu64位,Linux(也有Windows的,我还没空试)
2.一般的配置jdk、Scala等的路径环境是在/etc/profile里配置的,我自己搭建的时候发现我自己在profile配置环境会有问题,比如说:我配置了spark,source了profile,启动spark是没问题的,但是当我想再次启动spark的时候,
就会启动失败,需要再source一遍profile,所以我把所有的需要配置环境的命令都写在了 ~/.bashrc文件里,只需要source一遍就好了。
3.我只是菜鸟,如果有什么地方说错了,大家一定要跟我说,我改。或者大家有更好的办法,麻烦教我一下,谢谢!
一、设置SSH免密登入:
(一般Ubuntu自带客户端了,所以只需要装服务端即可。可通过命令:dpkg -l | grep ssh 查看是否安装有服务端和客户端,安装客户端命令:sudo apt-get install opendssh-client)
1、安装服务端,安装命令: sudo apt-get install openssh-server,可能会需要输入用户密码,输入按回车继续。可能它还会询问是否继续,输入 Y 回车继续。安装成功后,使用命令 ssh localhost 测试安装的SSH是否能正常连接,连接需要输入用户的密码
2、设置免密码登录步骤:
(1)生成密钥,命令:ssh-keygen。执行过程中会要求你输入连接用的密码,不要输入任何东西,直接回车。系统会在~/.ssh目录生成密钥文件(id_rsa 私钥,id_rsa.pub公钥),执行成功的结果如图所示。
(2)将生成公钥的内容添加到authorized_keys文件中,命令:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(3)修改authorized_keys和~/.ssh文件权限,命令:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
(4)设置成功后,可以验证一下是否成功,命令:ssh localhost ,如果不需要输入用户密码,即为设置成功。
二、JDK的安装与配置
1、解压JDK的安装包,解压命令:tar -zvxf jdk-8u181-linux-x64.tar.gz -C /opt
2、配置环境变量,在 /etc/profile 文件中添加如下内容:
export JAVA_HOME=/opt/jdk1.8.0_181 # 配置JAVA_HOME
export CLASS_PATH=/opt/jdk1.8.0_181/lib # 配置类路径
export PATH=$PATH:$JAVA_HOME/bin # 添加bin路径到PATH,添加后可以在命令行中直接使用java相关命令
3、重新执行刚修改的/etc/profile文件,使配置的环境立即生效,命令: source /etc/profile
4、JDK安装配置完成之后,在命令行输入命令:java –version,检查JDK是否安装无误
三、Scala的安装与配置
1、 解压Scala的安装包,解压命令:tar -zvxf scala-2.11.12.tgz -C /opt
2、 配置环境变量,在 /etc/profile 文件中添加如下内容:
export SCALA_HOME=/opt/scala-2.11.12 # 配置SCALA_HOME
export PATH=$PATH:$SCALA_HOME/bin # 添加bin目录到PATH
3、重新执行刚修改的/etc/profile文件,使配置的环境立即生效,命令: source /etc/profile
4、Scala安装配置完成之后,在命令行输入命令:scala,检查Scala是否安装无误。
四、Spark的安装与配置
1、解压Spark的安装包,解压命令: tar -zvxf spark-2.3.3-bin-hadoop2.7.tgz -C /opt
2、 配置环境变量,在 /etc/profile 文件中添加如下内容:
export SPARK_HOME=/opt/spark-2.3.3-bin-hadoop2.7 # 配置SPARK_HOME
export PATH=$PATH:$SPARK_HOME/bin # 添加bin目录到PATH
3、重新执行刚修改的/etc/profile文件,使配置的环境立即生效,命令: source /etc/profile
4、修改Spark配置文件
(1)复制模板文件,将在Spark的conf目录中的spark-env.sh.template、log4j.properties.template、slaves.template三个文件拷贝为spark-env.sh、log4j.properties、slaves到同一目录下(conf文件夹),注意把.template去掉,然后Spark启动时就会对文件中的配置项进行读取,否则找不到配置。命令如下:
cd /opt/spark-2.3.3-bin-hadoop2.7/conf // 进入到配置文件夹中
sudo cp spark-env.sh.template spark-env.sh // Spark环境相关
sudo cp log4j.properties.template log4j.properties // Spark日志相关
sudo cp slaves.template slaves // Spark集群节点
5、设置spark-2.3.3-bin-hadoop2.7文件夹可读可写可执行权限,命令:
cd /opt
sudo chmod 777 spark-2.3.3-bin-hadoop2.7/
6、Spark已经安装配置完成了,进入到Spark目录中的sbin路径下,运行 ./start-all.sh启动集群,测试一下刚刚安装的Spark。
7、命令行输入spark-shell来检查spark是否安装无误,成功运行的画面如图:(spark默认是用Scala语言,如果想用python编写看第9个步骤。)
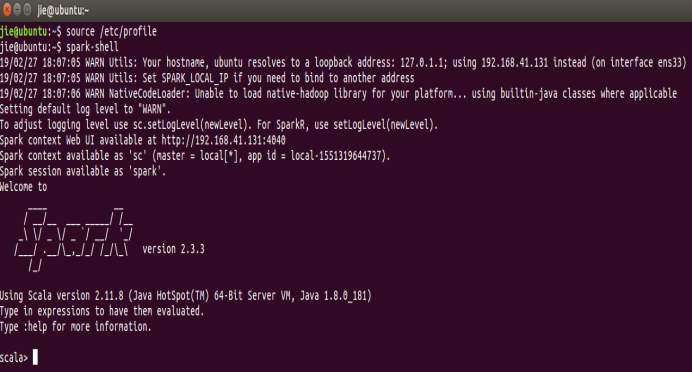
8、Spark集群启动完成后打开浏览器输入地址:localhost:8080,即可查看集群的UI界面,没有出现UI界面,就返回去检查一下之前环境配置是否有问题,spark是否start-all。
9、可以在命令行直接启动pyspark,命令为 pyspark,启动成功后的画面如图:
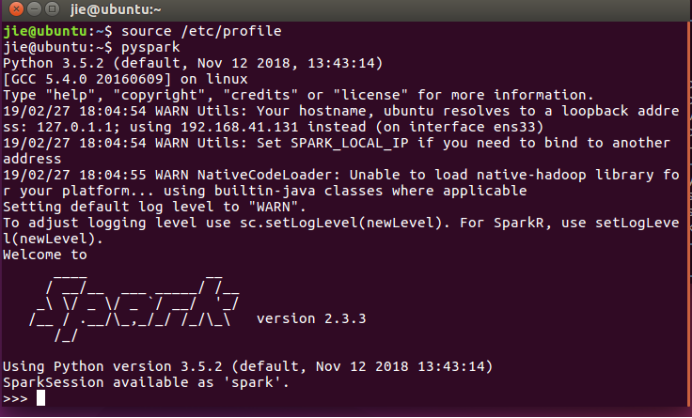
以上搭建的环境只能让你在命令行模式编写spark,等我过段时间有空了再教大家在pycharm里搭建spark。
在Ubuntu里搭建spark环境的更多相关文章
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- 在ubuntu上搭建开发环境3---解决Y470一键系统重装之后恢复ubuntu引导启动的方法
2015/08/18 将知识.常用的操作整理出来一定要完整,注意细节. 就像下面是再2015.04.27时候整理的,当时确实实验成功了,但是可能忘记记下具体的细节,尤其是3.4.5.6步骤中的关于盘符 ...
- deepin/ubuntu下搭建Jekyll环境
title: deepin/ubuntu下搭建Jekyll环境 最近用github搭建了个博客,正好也学习一下markdown语法,由于markdown写完后不是立即可见,所以每次写完文章都要经过在线 ...
- Spark在Ubuntu中搭建开发环境
一.在Windows7中安装Ubuntu双系统 工具/原料 windows7 64位 ubuntu 16.04 32位 UltraISO最新版(用来将镜像文件烤到U盘中) 空U盘(若有文件,请先备 ...
- 在Ubuntu下搭建Spark群集
在前一篇文章中,我们已经搭建好了Hadoop的群集,接下来,我们就是需要基于这个Hadoop群集,搭建Spark的群集.由于前面已经做了大量的工作,所以接下来搭建Spark会简单很多. 首先打开三个虚 ...
- 在ubuntu上搭建开发环境4---ubuntu简单的搭建LAMP环境和配置
最近重新安装了Ubuntu,但是之前的LAMP环境自然也就没有了,实在是不想再去编译搭建LAMP环境(这种方法实在是太费时间,而且太容易遇到各种不知道为什么的错误),所以,就去查查有没有什么简单的搭建 ...
- Linux之旅-ubuntu下搭建nodejs环境
.NET Core也开源了,并且可移植到Linux下,而ubuntu作为linux发行版的翘楚,极大的方便了初学者的入门,搭建完ASP.NET Core运行环境后,作为半前半后的开发人员,就继续着搭建 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- 在ubuntu上搭建交叉编译环境---arm-none-eabi-gcc
最近要开始搞新项目,基于arm的高通方案的项目. 那么,如何在ubuntu上搭建这个编译环境呢? 1.找到相关的安装包:http://download.csdn.net/download/storea ...
随机推荐
- 从运行时的工作空间获取EMF文件(IFILE)
//EMFFILE_URI为EMF文件的URI String uriString = EMFFILE_URI.trimFragment().toPlatformString(true); if (ur ...
- Java8-Lambda-No.01
import java.util.Arrays; import java.util.Collections; import java.util.Comparator; import java.util ...
- 19、属性赋值-@PropertySource加载外部配置文件
19.属性赋值-@PropertySource加载外部配置文件 加载外部配置文件的注解 19.1 [xml] 在原先的xml 中需要 导入context:property-placeholder 声明 ...
- MNIST 数据集介绍
在学习机器学习的时候,首要的任务的就是准备一份通用的数据集,方便与其他的算法进行比较. MNIST数据集是一个手写数字数据集,每一张图片都是0到9中的单个数字,比如下面几个: MNIST数据库 ...
- Codeforces Round #426 (Div. 2) B题【差分数组搞一搞】
B. The Festive Evening It's the end of July – the time when a festive evening is held at Jelly Castl ...
- [51Nod] 配对
https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1737 求出树的重心,跑spfa #include <iostre ...
- 第2组 Alpha冲刺(3/4)
17-材料-黄智(252342126) 22:10:46 队名:十一个憨批 组长博客 作业博客 组长黄智 过去两天完成的任务:写博客,复习C语言 GitHub签入记录 接下来的计划:构思游戏实现 还剩 ...
- JavaScript中BOM的重要内容总结
一.BOM介绍 BOM(Browser Object Model),浏览器对象模型: 用来操作浏览器部分功能的API: BOM由一系列的对象构成,由于主要用于管理窗口和窗口之间的通讯,所以核心对象是w ...
- 数据结构实验之二叉树七:叶子问题(SDUT 3346)
#include <bits/stdc++.h> using namespace std; struct node { char data; struct node *lc, *rc; } ...
- python 获取远程设备ip地址
python2.7 #!/usr/bin/env python # Python Network Programming Cookbook -- Chapter - # This program is ...