[目标检测] 从 R-CNN 到 Faster R-CNN
R-CNN
创新点
- 经典的目标检测算法使用滑动窗法依次判断所有可能的区域,提取人工设定的特征(HOG,SIFT)。本文则预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上用深度网络提取特征,进行判断。
- 采用大样本下有监督预训练+小样本微调的方式解决小样本难以训练甚至过拟合等问题。
测试过程
- 输入一张多目标图像,采用selective search算法提取约2000个建议框;
- 先在每个建议框周围加上16个像素值为建议框像素平均值的边框,再直接变形为227×227的大小;
- 先将所有建议框像素减去该建议框像素平均值后【预处理操作】,再依次将每个227×227的建议框输入AlexNet CNN网络(fc7层的输出)获取4096维的特征【比以前的人工经验特征低两个数量级】,2000个建议框的CNN特征组合成2000×4096维矩阵;
- 将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘【20种分类,SVM是二分类器,则有20个SVM】,获得2000×20维矩阵表示每个建议框是某个物体类别的得分;
- 分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框;
- 分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
存在问题
- 很明显,最大的缺点是对一张图片的处理速度慢,这是由于一张图片中由selective search算法得出的约2k个建议框都需要经过变形处理后由CNN前向网络计算一次特征,这其中涵盖了对一张图片中多个重复区域的重复计算,很累赘;
- 知乎上有人说R-CNN网络需要两次CNN前向计算,第一次得到建议框特征给SVM分类识别,第二次对非极大值抑制后的建议框再次进行CNN前向计算获得Pool5特征,以便对建议框进行回归得到更精确的bounding-box,这里文中并没有说是怎么做的,博主认为也可能在计算2k个建议框的CNN特征时,在硬盘上保留了2k个建议框的Pool5特征,虽然这样做只需要一次CNN前向网络运算,但是耗费大量磁盘空间;
- 训练时间长,虽然文中没有明确指出具体训练时间,但由于采用RoI-centric sampling【从所有图片的所有建议框中均匀取样】进行训练,那么每次都需要计算不同图片中不同建议框CNN特征,无法共享同一张图的CNN特征,训练速度很慢;
- 整个测试过程很复杂,要先提取建议框,之后提取每个建议框CNN特征,再用SVM分类,做非极大值抑制,最后做bounding-box回归才能得到图片中物体的种类以及位置信息;同样训练过程也很复杂,ILSVRC 2012上预训练CNN,PASCAL VOC 2007上微调CNN,做20类SVM分类器的训练和20类bounding-box回归器的训练;这些不连续过程必然涉及到特征存储、浪费磁盘空间等问题。
SPP Net
1. 结合空间金字塔方法实现CNNs的对尺度输入
一般CNN后接全连接层或者分类器,他们都需要固定的输入尺寸,因此不得不对输入数据进行crop或者warp,这些预处理会造成数据的丢失或几何的失真。SPP Net的第一个贡献就是将金字塔思想加入到CNN,实现了数据的多尺度输入。
如下图所示,在卷积层和全连接层之间加入了SPP layer。此时网络的输入可以是任意尺度的,在SPP layer中每一个pooling的filter会根据输入调整大小,而SPP的输出尺度始终是固定的。
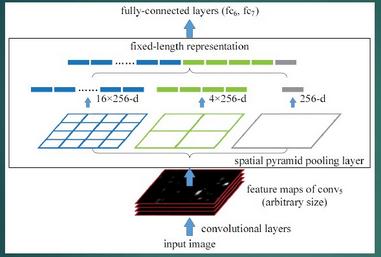
假设原图输入是224x224,对于conv5出来后的输出是13x13x256的,可以理解成有256个这样的filter,每个filter对应一张13x13的reponse map。如果像上图那样将reponse map分成1x1(金字塔底座),2x2(金字塔中间),4x4(金字塔顶座)三张子图,分别做max pooling后,出来的特征就是(16+4+1)x256 维度。如果原图的输入不是224x224,出来的特征依然是(16+4+1)x256维度。这样就实现了不管图像尺寸如何池化层的输出永远是(16+4+1)x256 维度。
实际运用中只需要根据全连接层的输入维度要求设计好空间金字塔即可。
2. 只对原图提取一次卷积特征
在R-CNN中,每个候选框先resize到统一大小,然后分别作为CNN的输入,这样是很低效的。
所以SPP Net根据这个缺点做了优化:只对原图进行一次卷积得到整张图的feature map,然后找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层。节省了大量的计算时间,比R-CNN有一百倍左右的提速。
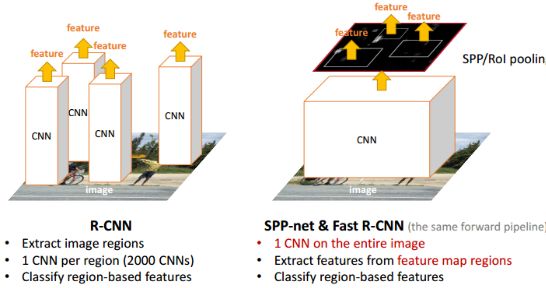
将conv5的pool层改为SPP之后就不必把每一个都ROI抠出来送给CNN做繁琐的卷积了,整张图像做卷积一次提取所有特征再交给SPP即可。
两个难点:
- 原始图像的ROI如何映射到特征图(一系列卷积层的最后输出)——参考这里
- ROI的在特征图上的对应的特征区域的维度不满足全连接层的输入要求怎么办(又不可能像在原始ROI图像上那样进行截取和缩放)——空间金字塔池化
Fast R-CNN
在RCNN的基础上采纳了SPP Net方法,对RCNN作了改进,使得性能进一步提高。
R-CNN的主要缺点为速度瓶颈,即使使用了selective search等预处理步骤来提取潜在的bounding box作为输入,但是计算机对所有region进行特征提取时会有重复计算;其次,RCNN中独立的分类器和回归器需要大量特征作为训练样本,Fast RCNN 把类别判断和位置精调统一用深度网络实现,不需要额外存储。
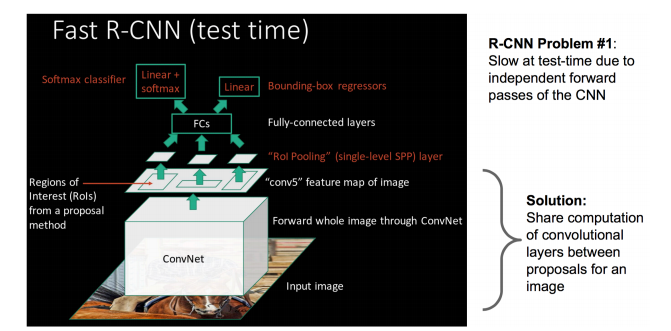
通过共享卷积层,现在不是每一个候选框都当做输入进入CNN了,而是输入一张完整的图片,在第五个卷积层再得到每个候选框的特征。
大牛提出了一个可以看做单层sppnet(减少计算量)的网络层,叫做ROI Pooling,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量,而我们知道,conv、pooling、relu等操作都不需要固定size的输入,因此,在原始图片上执行这些操作后,虽然输入图片size不同导致得到的feature map尺寸也不同,不能直接接到一个全连接层进行分类,但是可以加入这个神奇的ROI Pooling层,对每个region都提取一个固定维度的特征表示,再通过正常的softmax进行类型识别(SVM分类其实差别不大,softmax也是个不错的选择)。
另外,之前RCNN的处理流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression,而在Fast-RCNN中,作者巧妙的把bbox regression放进了神经网络内部,与region分类和并成为了一个multi-task模型(不用非极大值抑制来过滤?),实际实验也证明,这两个任务能够共享卷积特征,并相互促进。Fast-RCNN很重要的一个贡献是成功的让人们看到了Region Proposal+CNN这一框架实时检测的希望,原来多类检测真的可以在保证准确率的同时提升处理速度,也为后来的Faster-RCNN做下了铺垫。
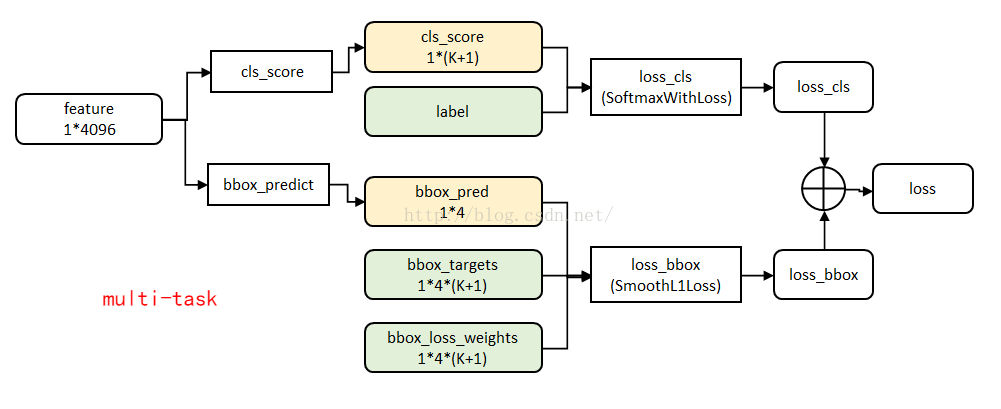
代价函数 :
loss_cls层评估分类代价。由真实分类 \(u\) 对应的概率决定:\[L_{cls}=−logP_u\]
loss_bbox评估检测框定位代价。比较真实分类对应的预测参数 \(t^u\) 和真实平移缩放参数为 \(v\) 的差别:\[L_{loc}=\sum ^4 _{i=1} g(t^u _i-v_i)\]
g 为 Smooth L1误差,对outlier不敏感:\[g(x)=\begin{cases} 0.5x^2, & |x|<1 \\|x|-0.5, & otherwise \end{cases}\]
总代价为两者加权和,如果分类为背景则不考虑定位代价:\[L=\begin{cases} L_{cls}+\lambda L_{loc} , & u为前景 \\L_{cls}, & u为背景 \end{cases}\]
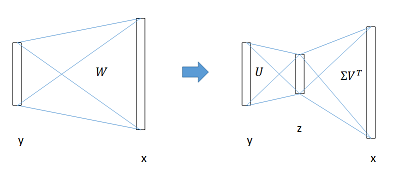
全连接层提速
分类和位置调整都是通过全连接层(fc)实现的,设前一级数据为 \(x\) 后一级为 \(y\),全连接层参数为 \(W\),尺寸\(u×v\)。一次前向传播(forward)即为:\(y=Wx\)
计算复杂度为 \(u\times v\)
将 \(W\) 进行 \(SVD\) 分解,并用前 \(t\) 个特征值近似:\[W=U\Sigma V^T\approx U(:,1:t)\cdot \Sigma (1:t,1:t)\cdot V(:,1:t)^T\]
原来的前向传播分解成两步:\[y = Wx = U\cdot (\Sigma \cdot V^T)\cdot x = U\cdot z\]
计算复杂度变为 \(u\times t + v\times t\)
在实现时,相当于把一个全连接层拆分成两个,中间以一个低维数据相连。
测试过程
- 在图像中确定约1000-2000个候选框 (使用选择性搜索)
- 对整张图片输进CNN,得到feature map
- 找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
- 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
- 对于属于某一特征的候选框,用回归器进一步调整其位置
Faster R-CNN
通过选择性搜索找出候选框的过程其实也非常耗时,为了更加高效的求出这些候选框,加入了一个提取边缘的神经网络,也就是说找候选框的工作也交给神经网络来做了。做这个任务的神经网络叫做Region Proposal Network(RPN)。将RPN放在最后一个卷积层的后面,直接训练得到候选区域。技术上将RPN网络和Fast R-CNN网络结合到了一起,将RPN获取到的proposal直接连到ROI pooling层。
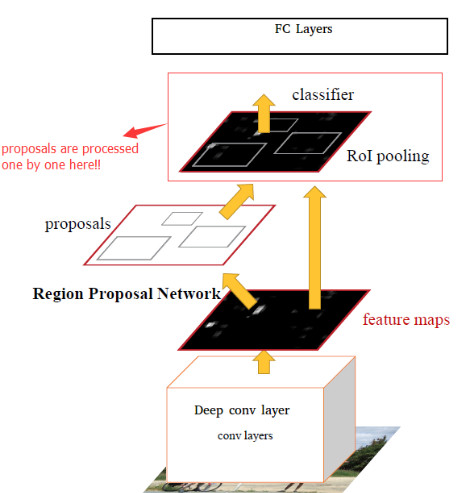
如何训练出一个网络来替代selective search相类似的功能呢?论文借鉴SPP和ROI中的思想,在feature map中提取proposal。 把每个特征点映射回映射回原图的感受野的中心点当成一个基准点,然后围绕这个基准点选取k个不同scale、aspect ratio的anchor。根据该窗口与ground truth的IOU给它正负标签,让它学习里面是否有object,这样就训练一个网络(Region Proposal Network)。
我们来看看RPN的结构:
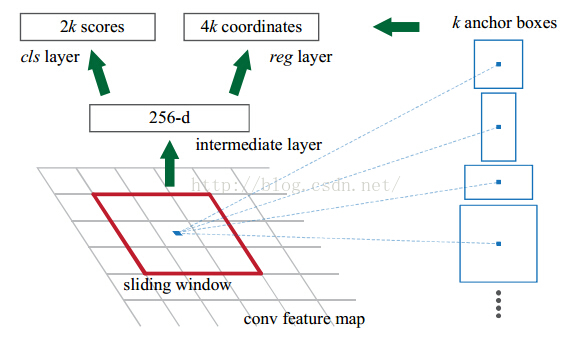
然后cls layer 和reg layer后面都会接到自己的损失函数上,给出损失函数的值,同时会根据求导的结果,给出反向传播的数据。对于每个anchor,首先在后面接上一个二分类softmax,有2个score 输出用以表示其是一个物体的概率与不是一个物体的概率 \(p_i\) ,然后再接上一个bounding box的regressor 输出代表这个anchor的4个坐标位置 \((x,y,w,h)\)。cls:正样本,与真实区域重叠大于0.7,负样本,与真实区域重叠小于0.3。reg:返回区域位置。RPN的总体Loss函数可以定义为:
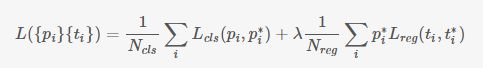
其中:

训练过程
- 使用在ImageNet上预训练的模型初始化RPN网络参数,微调RPN网络;
- 使用(1)中RPN网络提取region proposal训练Fast R-CNN网络,也用ImageNet上预训练的模型初始化该网络参数;(这时候两个网络还没有共享卷积层)
- 使用(2)的Fast R-CNN网络重新初始化RPN, 固定卷积层进行微调,微调RPN网络;
- 固定(2)中Fast R-CNN的卷积层,使用(3)中RPN提取的region proposal对Fast R-CNN网络进行微调。
测试过程
对整张图片输进CNN,得到feature map
卷积特征输入到RPN,得到候选框的特征信息
对候选框中提取出的特征,使用分类器判别是否属于一个特定类
对于属于某一特征的候选框,用回归器进一步调整其位置
实际代码中,将m*n*k个候选位置根据得分排序,选择最高的一部分,再经过Non-Maximum Suppression获得2000个候选结果。之后才送入分类器和回归器。
所以Faster-RCNN和RCNN, Fast-RCNN一样,属于2-stage的检测算法。
Reference:
- R-CNN论文详解
- selective search
- Efficient Graph-Based Image Segmentation
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 知乎-如何评价rcnn、fast-rcnn和faster-rcnn这一系列方法?-晓雷
- RCNN学习笔记(3)-SPPNet
- faster-rcnn 之 RPN网络的结构解析
- Faster R-CNN论文笔记
- 目标检测|YOLO原理与实现
[目标检测] 从 R-CNN 到 Faster R-CNN的更多相关文章
- [转]CNN目标检测(一):Faster RCNN详解
https://blog.csdn.net/a8039974/article/details/77592389 Faster RCNN github : https://github.com/rbgi ...
- 目标检测之R-CNN系列
Object Detection,在给定的图像中,找到目标图像的位置,并标注出来. 或者是,图像中有那些目标,目标的位置在那.这个目标,是限定在数据集中包含的目标种类,比如数据集中有两种目标:狗,猫. ...
- 目标检测(3)-SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 文章地址:https://arxiv.org ...
- TensorFlow目标检测(object_detection)api使用
https://github.com/tensorflow/models/tree/master/research/object_detection 深度学习目标检测模型全面综述:Faster R-C ...
- Faster R-CNN:详解目标检测的实现过程
本文详细解释了 Faster R-CNN 的网络架构和工作流,一步步带领读者理解目标检测的工作原理,作者本人也提供了 Luminoth 实现,供大家参考. Luminoth 实现:https:// ...
- 【目标检测】Faster RCNN算法详解
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal network ...
- 目标检测-Faster R-CNN
[目标检测]Faster RCNN算法详解 Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with r ...
- 论文笔记:目标检测算法(R-CNN,Fast R-CNN,Faster R-CNN,FPN,YOLOv1-v3)
R-CNN(Region-based CNN) motivation:之前的视觉任务大多数考虑使用SIFT和HOG特征,而近年来CNN和ImageNet的出现使得图像分类问题取得重大突破,那么这方面的 ...
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
不多说,直接上干货! 本文一系列目标检测算法:RCNN, Fast RCNN, Faster RCNN代表当下目标检测的前沿水平,在github都给出了基于Caffe的源码. • RCNN RCN ...
- 目标检测(四)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun SPPnet.Fast R-CNN等目标检测算法已经大幅降低了目标检测网络的运行时间. ...
随机推荐
- 1、Mat类的属性、方法
Mat类分有两个部分:矩阵头和指向矩阵数据部分的指针 Mat类的属性: rows 矩阵的行数 cols 矩阵的列数 dims 矩阵的维度,例如5*6矩阵是二维矩阵,则dims=2,三维矩阵di ...
- Microsoft.Practices.Unity使用配置文件总是报错The type name or alias could not be resolved.
Type name could not be resolved. Please check config file http://stackoverflow.com/questions/1493564 ...
- boost 函数与回调
result_of 含义:result_of可以帮助程序员确定一个调用表达式的返回类型,主要用于泛型编程和其他boost库组件,它已经被纳入TR1 头文件:<boost/utility/resu ...
- UVALive 7308 Tom and Jerry 猫抓老鼠 物理题
题目链接: 就是一个老鼠在环上一速度v开始绕环走,一只猫从圆心出发,任意时刻圆心,猫,老鼠三者在一条直线上,且速度也是v,求多久后猫抓到老鼠. #include <cstdio> #inc ...
- 【强化学习】1-1-2 “探索”(Exploration)还是“ 利用”(Exploitation)都要“面向目标”(Goal-Direct)
title: [强化学习]1-1-2 "探索"(Exploration)还是" 利用"(Exploitation)都要"面向目标"(Goal ...
- Rapid Object Detection using a Boosted Cascade of Simple Features 部分翻译
Rapid ObjectDetection using a Boosted Cascade of Simple Features 使用简单特征级联分类器的快速目标检测 注:部分翻译不准处以红色字体给出 ...
- 数据结构实验之链表二:逆序建立链表(SDUT 2117)
题目链接 #include <bits/stdc++.h> using namespace std; struct node { int data; struct node *next; ...
- MySQL-UDF和MOF提权
MOF提权 MOF文件是mysql数据库的扩展文件(在c:/windows/system32/wbem/mof/nullevt.mof) 叫做”托管对象格式”,其作用是每隔五秒就会去监控进程创建和死亡 ...
- linux环境下使用jmeter进行压力测试
linux环境下使用jmeter进行压力测试 linux环境下使用就meter进行压力测试: linux环境部署: 在Linux服务器先安装jdk: 2.以jdk-8u172-linux-x64.ta ...
- 对 Python 迭代的深入研究
在程序设计中,通常会有 loop.iterate.traversal 和 recursion 等概念,他们各自的含义如下: 循环(loop),指的是在满足条件的情况下,重复执行同一段代码.比如 Pyt ...