【并行计算-CUDA开发】CUDA线程、线程块、线程束、流多处理器、流处理器、网格概念的深入理解
GPU的硬件结构,也不是具体的硬件结构,就是与CUDA相关的几个概念:thread,block,grid,warp,sp,sm。
sp: 最基本的处理单元,streaming processor 最后具体的指令和任务都是在sp上处理的。GPU进行并行计算,也就是很多个sp同时做处理
sm:多个sp加上其他的一些资源组成一个sm, streaming multiprocessor. 其他资源也就是存储资源,共享内存,寄储器等。
warp:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令。
grid、block、thread:在利用cuda进行编程时,一个grid分为多个block,而一个block分为多个thread.其中任务划分到是否影响最后的执行效果。划分的依据是任务特性和
GPU本身的硬件特性。
下面几张硬件结构简图 便于理解(图片来源于网上)
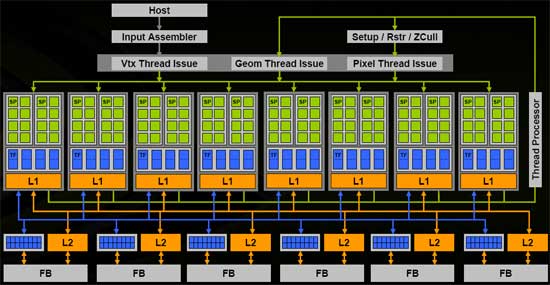

以上两图可以清晰地表示出sm与sp的关系。
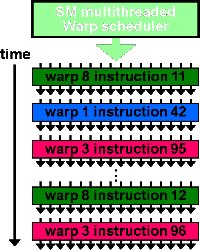
此图反应了warp作为调度单位的作用,每次GPU调度一个warp里的32个线程执行同一条指令,其中各个线程对应的数据资源不同。

上图是一个warp排程的例子。
一个sm只会执行一个block里的warp,当该block里warp执行完才会执行其他block里的warp。
进行划分时,最好保证每个block里的warp比较合理,那样可以一个sm可以交替执行里面的warp,从而提高效率,此外,在分配block时,要根据GPU的sm个数,分配出合理的
block数,让GPU的sm都利用起来,提利用率。分配时,也要考虑到同一个线程block的资源问题,不要出现对应的资源不够。
GPU线程以网格(grid)的方式组织,而每个网格中又包含若干个线程块,在G80/GT200系列中,每一个线程块最多可包含512个线程,Fermi架构中每个线程块支持高达1536个线程。同一线程块中的众多线程拥有相同的指令地址,不仅能够并行执行,而且能够通过共享存储器(Shared memory)和栅栏(barrier)实现块内通信。这样,同一网格内的不同块之间存在不需要通信的粗粒度并行,而一个块内的线程之间又形成了允许通信的细粒度并行。这些就是CUDA的关键特性:线程按照粗粒度的线程块和细粒度的线程两个层次进行组织、在细粒度并行的层次通过共享存储器和栅栏同步实现通信,这就是CUDA的双层线程模型。
在执行时,GPU的任务分配单元(global block scheduler)将网格分配到GPU芯片上。启动CUDA 内核时,需要将网格信息从CPU传输到GPU。任务分配单元根据这些信息将块分配到SM上。任务分配单元使用的是轮询策略:轮询查看SM是否还有足够的资源来执行新的块,如果有则给SM分配一个新的块,如果没有则查看下一个SM。决定能否分配的因素有:每个块使用的共享存储器数量,每个块使用的寄存器数量,以及其它的一些限制条件。任务分配单元在SM的任务分配中保持平衡,但是程序员可以通过更改块内线程数,每个线程使用的寄存器数和共享存储器数来隐式的控制,从而保证SM之间的任务均衡。任务以这种方式划分能够使程序获得了可扩展性:由于每个子问题都能在任意一个SM上运行,CUDA程序在核心数量不同的处理器上都能正常运行,这样就隐藏了硬件差异。
对于程序员来说,他们需要将任务划分为互不相干的粗粒度子问题(最好是易并行计算),再将每个子问题划分为能够使用线程处理的问题。同一线程块中的线程开始于相同的指令地址,理论上能够以不同的分支执行。但实际上,在块内的分支因为SM构架的原因被大大限制了。内核函数实质上是以块为单位执行的。同一线程块中的线程需要SM中的共享存储器共享数据,因此它们必须在同一个SM中发射。线程块中的每一个线程被发射到一个SP上。任务分配单元可以为每个SM分配最多8个块。而SM中的线程调度单元又将分配到的块进行细分,将其中的线程组织成更小的结构,称为线程束(warp)。在CUDA中,warp对程序员来说是透明的,它的大小可能会随着硬件的发展发生变化,在当前版本的CUDA中,每个warp是由32个线程组成的。SM中一条指令的延迟最小为4个指令周期。8个SP采用了发射一次指令,执行4次的流水线结构。所以由32个线程组成的Warp是CUDA程序执行的最小单位,并且同一个warp是严格串行的,因此在warp内是无须同步的。在一个SM中可能同时有来自不同块的warp。当一个块中的warp在进行访存或者同步等高延迟操作时,另一个块可以占用SM中的计算资源。这样,在SM内就实现了简单的乱序执行。不同块之间的执行没有顺序,完全并行。无论是在一次只能处理一个线程块的GPU上,还是在一次能处理数十乃至上百个线程块的GPU上,这一模型都能很好的适用。
目前,某一时刻只能有一个内核函数正在执行,但是在Fermi架构中,这一限制已被解除。如果在一个内核访问数据时,另一个内核能够进行计算,则可以有效的提高设备的利用率。
每一个块内线程数应该首先是32的倍数,因为这样的话可以适应每一个warp包含32个线程的要求,每一个warp中串行执行,这就要求每一个线程中不可以有过多的循环或者需要的资源过多。但是每一个块中如果线程数过多,可能由于线程中参数过多带来存储器要求过大,从而使SM处理的效率更低。所以,在函数不是很复杂的情况下,可以适当的增加线程数目,线程中不要加入循环。在函数比较复杂的情况下,每一个块中分配32或是64个线程比较合适。每一个SM同时处理一个块,只有在粗粒度层面上以及细粒度层面上均达到平衡,才能使得GPU的利用到达最大。我用的显卡为GeForce
GTX560 Ti,每一个网格中允许的最大块数位65535个,而每个块中的线程数为1024个,所以说粗粒度平衡对于我来说影响比较小,就细粒度来说,每一个块中的线程数以及每一个线程中的循环就变得至关重要了。
【并行计算-CUDA开发】CUDA线程、线程块、线程束、流多处理器、流处理器、网格概念的深入理解的更多相关文章
- CUDA开发 - CUDA 版本
"CUDA runtime is insufficient with CUDA driver"CUDA 9.2: 396.xx CUDA 9.1: 387.xx CUDA 9.0: ...
- CUDA线程、线程块、线程束、流多处理器、流处理器、网格概念的深入理解
一.与CUDA相关的几个概念:thread,block,grid,warp,sp,sm. sp: 最基本的处理单元,streaming processor 最后具体的指令和任务都是在sp上处理的.G ...
- 【并行计算-CUDA开发】有关CUDA当中global memory如何实现合并访问跟内存对齐相关的问题
ps:这是英伟达二面面的一道相关CUDA的题目.<NVIDIA CUDA编程指南>第57页开始 在合并访问这里,不要跟shared memory的bank conflic ...
- 【并行计算-CUDA开发】OpenACC与OpenHMPP
在西雅图超级计算大会(SC11)上发布了新的基于指令的加速器并行编程标准,既OpenACC.这个开发标准的目的是让更多的编程人员可以用到GPU计算,同时计算结果可以跨加速器使用,甚至能用在多核CPU上 ...
- 【并行计算-CUDA开发】__syncthreads的理解
__syncthreads()是cuda的内建函数,用于块内线程通信. __syncthreads() is you garden variety thread barrier. Any thread ...
- 【并行计算-CUDA开发】CUDA并行存储模型
CUDA并行存储模型 CUDA将CPU作为主机(Host),GPU作为设备(Device).一个系统中可以有一个主机和多个设备.CPU负责逻辑性强的事务处理和串行计算,GPU专注于执行高度线程化的并行 ...
- Java开发笔记(一百)线程同步synchronized
多个线程一起办事固然能够加快处理速度,但是也带来一个问题:两个线程同时争抢某个资源时该怎么办?看来资源共享的另一面便是资源冲突,正所谓鱼与熊掌不可兼得,系统岂能让多线程这项技术专占好处?果然是有利必有 ...
- 【Qt开发】事件循环与线程 二
事件循环与线程 二 Qt 线程类 Qt对线程的支持已经有很多年了(发布于2000年九月22日的Qt2.2引入了QThread类),Qt 4.0版本的release则对其所有所支持平台默认地是对多线程支 ...
- java开发两年,这些线程知识你都不知道,你怎么涨薪?
前言 什么是线程:程序中负责执行的哪个东东就叫做线程(执行路线,进程内部的执行序列),或者说是进程的子任务. Java中实现多线程有几种方法 继承Thread类: 实现Runnable接口: 实现Ca ...
随机推荐
- Educational Codeforces Round 34 (Rated for Div. 2) B题【打怪模拟】
B. The Modcrab Vova is again playing some computer game, now an RPG. In the game Vova's character re ...
- 路由器配置——基于区域的OSPF简单认证
一.实验目的:掌握区域的OSPF简单认证 二.拓扑图: 三.具体步骤配置: (1)R1路由器配置 Router>enable Router#configure terminal Enter co ...
- Makefile规则介绍
Makefile 一个规则 三要素:目标,依赖,命令 目标:依赖 命令 1.第一条规则是用来生成终极目标的规则 如果规则中的依赖不存在,向下寻找其他的规则 更新机制:比较的是目标文件和 ...
- Contos 安装Tomcat
# 下载安装包 wget http://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-8/v8.5.40/bin/apache-tomcat-8. ...
- 使用vim编辑python智能提示
一.vim python自动补全插件:pydiction 可以实现下面python代码的自动补全: 1.简单python关键词补全 2.python 函数补全带括号 3.python 模块补全 4.p ...
- 20.包含min函数的栈 Java
题目描述 定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的min函数(时间复杂度应为O(1)). 思路 借助辅助栈实现: 压栈时:若辅助栈为空,则将节点压入辅助栈.否则,当当前节点小于 ...
- Leetcode题目238.除自身以外数组的乘积(中等)
题目描述: 给定长度为 n 的整数数组 nums,其中 n > 1,返回输出数组 output ,其中 output[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积. 示例: ...
- 爬虫实践——数据存储到Excel中
在进行爬虫实践时,我已经爬取到了我需要的信息,那么最后一个问题就是如何把我所爬到的数据存储到Excel中去,这是我没有学习过的知识. 如何解决这个问题,我选择先百度查找如何解决这个问题. 百度查到的方 ...
- CentOS7 上搭建 CDH(6.3.0)
这里以四台节点搭建 IP HostName OS 192.168.8.5 h5(主) CentOS 7.5 192.168.8.6 h6(从) CentOS 7.5 192.168.8.7 h7(从) ...
- Web服务器磁盘满深入解析及解决
########################################################## 硬盘显示被写满但是用du -sh /*查看时占用硬盘空间之和还远#小于硬盘大小问的 ...