hive 存储格式对比
Parquet是一个面向列的二进制文件格式。Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列的查询,Parquet特别有用。Parquet桌子使用压缩Snappy,gzip;目前Snappy默认。
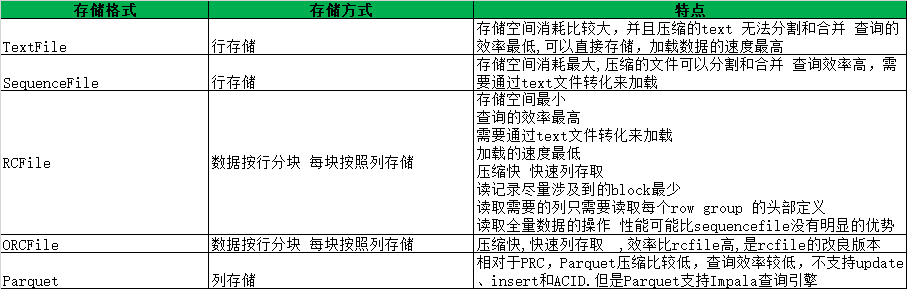
存储格式对比
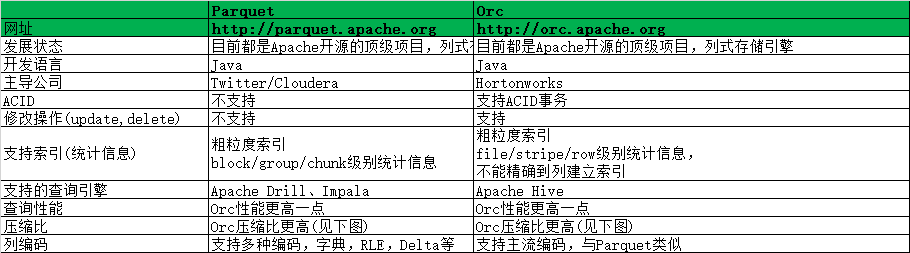
Parquet与ORC对比
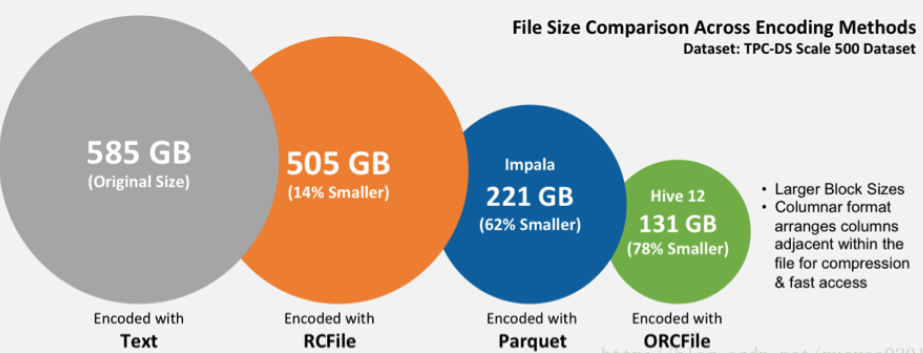
总结:如果仅仅是在HIve中存储和查询,建议使用ORC格式,如果在Hive中存储,而使用Impala查询,建议使用Parquet
hive 存储格式对比的更多相关文章
- Hive存储格式之RCFile详解,RCFile的过去现在和未来
我在整理Hive的存储格式和压缩格式,本来打算一篇发出来,结果其中一小节就有很多内容,于是打算写成Hive存储格式和压缩格式系列. 本节主要讲一下Hive存储格式最早的典型的列式存储格式RCFile. ...
- Hive存储格式之ORC File详解,什么是ORC File
目录 概述 文件存储结构 Stripe Index Data Row Data Stripe Footer 两个补充名词 Row Group Stream File Footer 条纹信息 列统计 元 ...
- hive中数据存储格式对比:textfile,parquent,orc,thrift,avro,protubuf
这篇文章我会从业务中关注的: 1. 存储大小 2.查询效率 3.是否支持表结构变更既数据版本变迁 5.能否避免分隔符问题 6.优势和劣势总结 几方面完整的介绍下hive中数据以下几种数据格式:text ...
- 【HBase】快速搞定HBase与Hive的对比、整合
目录 对比 整合 需求一 步骤 一.将HBase的五个jar包拷贝到Hive的lib目录下 二.修改hive的配置文件 三.在Hive中建表 四.创建hive管理表与HBase映射 五.在HBase中 ...
- Mongodb和Hive详细对比
本文主要用于分析在大数据场景下Mongodb和Hive的优缺点: 支持的数据类型 支持的查询 支持的数据量 性能优化手段
- hive 存储格式
hive有textFile,SequenceFile,RCFile三种文件格式. textfile为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理. Seq ...
- Pig和Hive的对比
Pig Pig是一种编程语言,它简化了Hadoop常见的工作任务.Pig可加载数据.表达转换数据以及存储最终结果.Pig内置的操作使得半结构化数据变得有意义(如日志文件).同时Pig可扩展使用Java ...
- hive 存储格式及压缩
-- 设置参数 set hivevar:target_db_name=db_dw; use ${hivevar:target_db_name}; -- 创建textfile表 create table ...
- hive的数据存储格式
hive的数据存储格式 Hive支持的存储数的格式主要有:TEXTFILE(行式存储) .SEQUENCEFILE(行式存储).ORC(列式存储).PARQUET(列式存储). 1 列式存储和行式存储 ...
随机推荐
- 123457123456---熊猫猜谜语02(儿童猜谜语大全)--com.threeObj03.CaiMiYu02
熊猫猜谜语02(儿童猜谜语大全)--com.threeObj03.CaiMiYu02
- laravel5.2总结
转自:http://www.cnblogs.com/redirect/p/6178001.html
- 【Leetcode_easy】788. Rotated Digits
problem 788. Rotated Digits solution1: class Solution { public: int rotatedDigits(int N) { ; ; i< ...
- maven项目创建.m2文件夹
创建为.m2.,m2前后都要有点,然后去掉后面的点 settings.xml文件如下: <?xml version="1.0" encoding="UTF-8&qu ...
- Redis源码解析
一.src/server.c 中的redisCommandTable列出的所有redis支持的命令,其中字符串命令包括从get到mget:列表命令从rpush到rpoplpush:集合命令包括从sad ...
- EM算法之不同的推导方法和自己的理解
EM算法之不同的推导方法和自己的理解 一.前言 EM算法主要针对概率生成模型解决具有隐变量的混合模型的参数估计问题. 对于简单的模型,根据极大似然估计的方法可以直接得到解析解:可以在具有隐变量的复杂模 ...
- 【谷歌浏览器】修改和添加Cookie
一.使用谷歌浏览器 1.1.修改ookie 方法一:直接用开发者工具修改: 操作如图: 参考: 检查和删除 Cookie · Chrome 开发者工具中文文档 http://www.css88.c ...
- Node中导入模块require和import??
转自:https://blog.csdn.net/wxl1555/article/details/80852326 S6标准发布后,module成为标准,标准的使用是以export指令导出接口,以im ...
- [转帖]java的编译器,解释器和即时编译器概念
java的编译器,解释器和即时编译器概念 置顶 2019-04-20 13:18:55 菠萝科技 阅读数 268更多 分类专栏: java jvm虚拟机 操作系统/linux 版权声明:本文为博主 ...
- Hadoop的eclipse的插件是怎么安装的?
[学习笔记] 1)网上下载hadoop-eclipse-plugin-2.7.4.jar,将该jar包拷贝到Eclipse安装目录下的dropins文件夹下,我的目录是C:\Users\test\ec ...