在fedora20下配置hadoop2.5.1的eclipse插件
(博客园-番茄酱原创)
在我的系统中,hadoop-2.5.1的安装路径是/opt/lib64/hadoop-2.5.1下面,然后hadoop-2.2.0的路径是/home/hadoop/下载/hadoop-2.2.0,我的eclipse的安装路径是/opt/programming/atd-bundle/eclipse。
因为老师需要我们写mapreduce程序,所以现在需要配置hadoop的eclipse插件。之前在windows下面安装hadoop一直会有莫名其妙的问题,所以索性直接在linux下面装了。Linux下面还更简单一些。
下面谈谈如何配置吧。
其实这次配置,并不是直接生成hadoop2.5.1的插件,而是生成hadoop2.2.0的插件,但是兼容hadoop-2.5.1。(这句话实际上指的是下面1步骤中的那个包是基于hadoop-2.2.0的开发的并且编译时候依赖hadoop-2.2.0,所以我们需要下载hadoop-2.2.0)。因此,我们需要下载的东西有3个,一个是hadoop插件源文件,一个是ant(fedora20在线安装),一个是额外的hadoop-2.2.0.tar.gz
。
- 下载hadoop2x-eclipse-plugin-master.zip,这是插件源文件,需要用ant编译。下载地址是:https://codeload.github.com/jaradgreen/hadoop2x-eclipse-plugin/zip/master
- 然后安装在线安装ant编译工具,在终端输入:yum install ant,一路选择yes或y安装。
- 将下载的hadoop2x-eclipse-plugin-master.zip解压,cd到下载的文件目录,终端输入:unzip hadoop2x-eclipse-plugin-master.zip,然后在当前目录下就会多出一个文件夹:hadoop2x-eclipse-plugin-master
- 然后cd hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugin进入解压的文件夹/hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugin目录下,修改build.xml。
- 修改编译配置文件build.xml.输入命令vi build.xml
- 在build.xml文件中project标签后面第三行,添加 <property name="eclipse.home" location="/opt/programming/adt-bundle/eclipse"/><!---这个是用来指出eclipse的安装目录->
- <property name="hadoop.home" location="/home/hadoop/下载/hadoop-2.2.0"/><!--此处需要hadoop2.2.0的发行包,编译依赖此路径(不是源包,也不是你安装的hadoop-2.5.1的路径,别弄混了)-->
- <property name="version" value="2.5.1"/> <!--(注意:自己根据自己的hadoop2.2.0和eclipse的路径情况,更改上述的安装位置)-->
- 然后进行ant编译, 运行ant命令, ant jar -D eclipse.home=/opt/programming/adt-bundle/eclipse -D hadoop.home=/home/hadoop/下载/hadoop-2.2.0 -D version=2.5.1
- 然后ant就会编译生成一个jar文件,在hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin 下面,名为hadoop-eclipse-plugin-2.5.1.jar 然后将其拷到eclipse安装路径下的plugin文件夹下面,我的是/opt/programming/adt-bundle/eclipse/plugins 这个命令是mv /home/hadoop/下载/hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin/hadoop-eclipse-plugin-2.5.1.jar /opt/programming/adt-bundle/eclipse/plugins/根据自己的情况进行更改啦
- 重启eclipse,一路点击windows->show view->other->mapreduce tools就可以选择hadoop视图了,然后就可以进行相应的编程了。
- 把刚刚的hadoop-2.2.0删掉,他已经光荣的完成使命啦
打开eclipse,然后进行一些配置
先选择hadoop的安装路径

然后点击ok
然后点击hadoop location,然后新建一个location
右击鼠标新建一个location
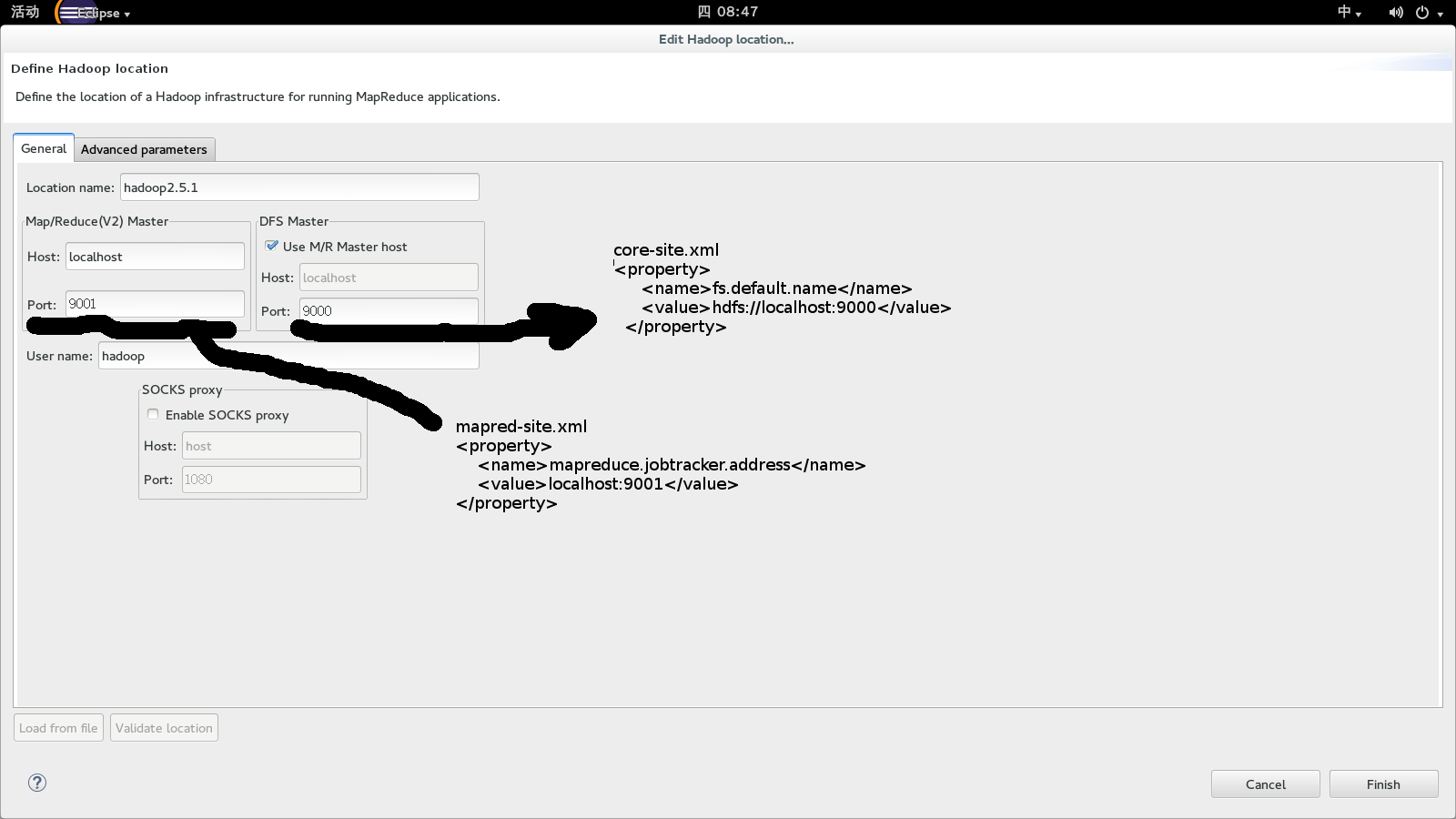
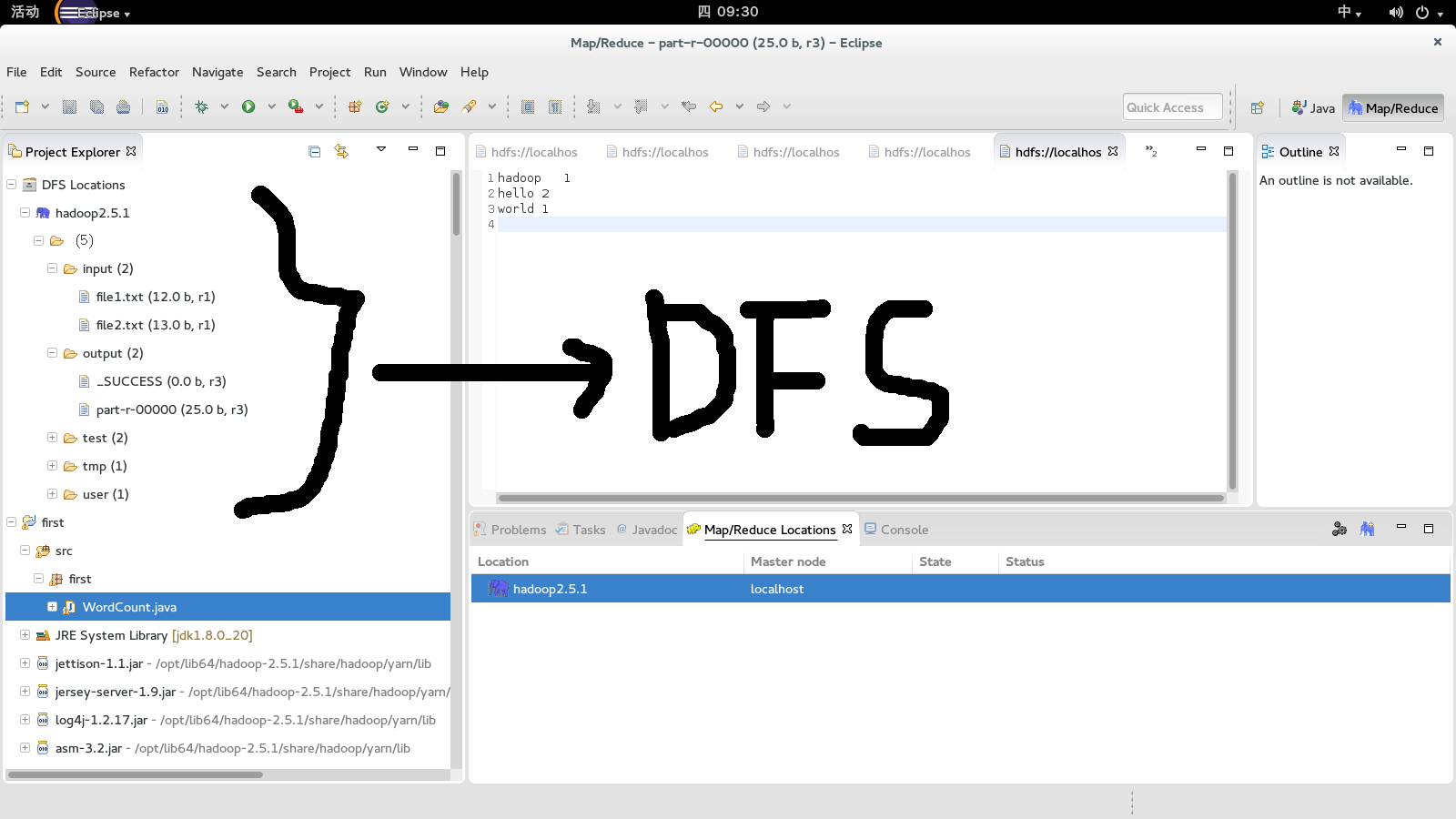
到这边,hadoop的eclipse就配置完毕了。如果你的hadoop的是开启的状态下,在eclipse中便可以直接操作dfs了
对了,如果你要跑wordcount程序,你需要在hadoop的src包中找到WordCount.java文件,
该目录下面有好多例子,目录是hadoop-2.5.1-src/hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples

附上其中除了命名空间的包名的代码
import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行之前,需要配置run的参数:hdfs://localhost:9000/input hdfs://localhost:9000/output。然后再run as-> run on hadoop(要先把hadoop开启)
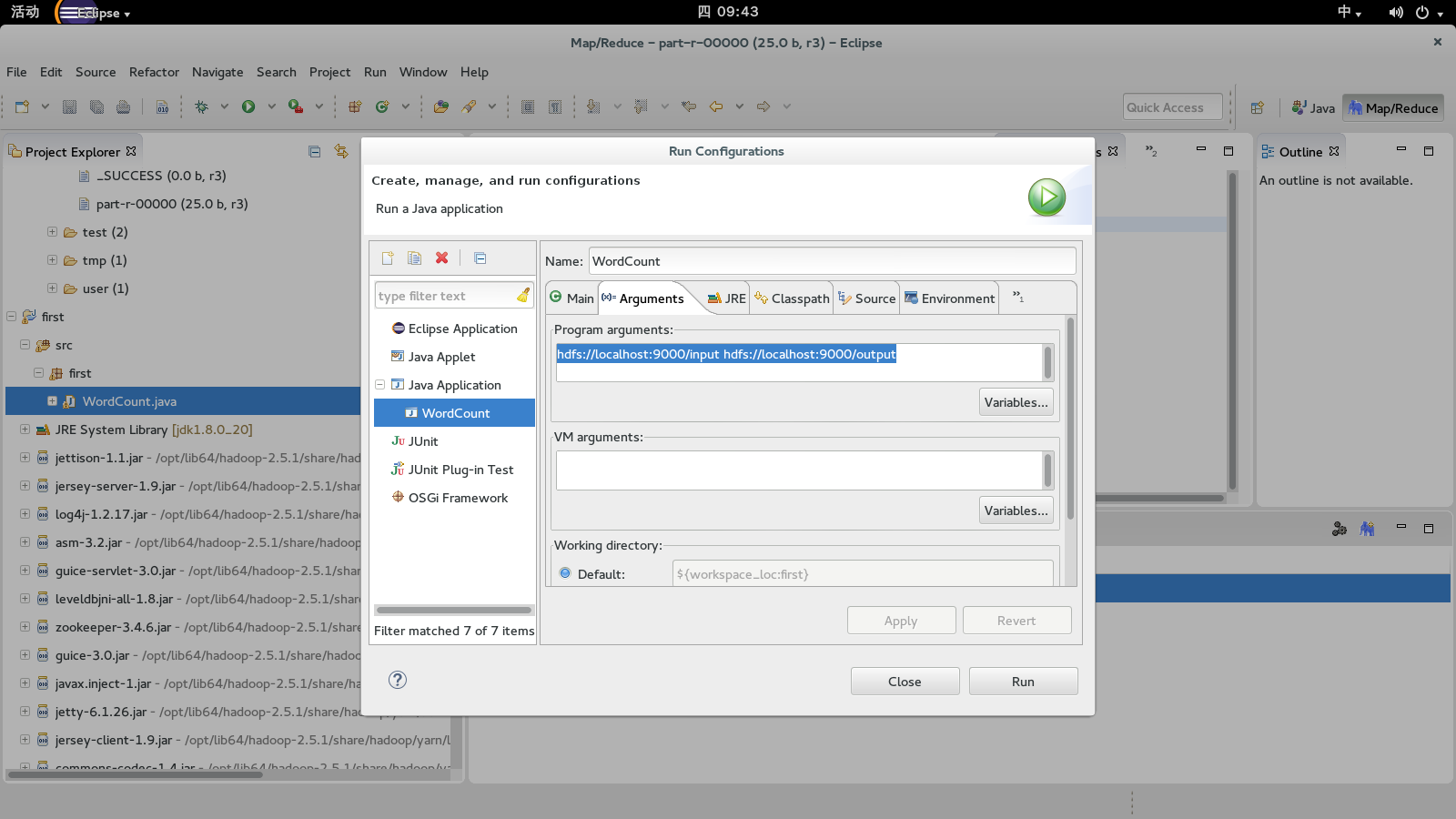
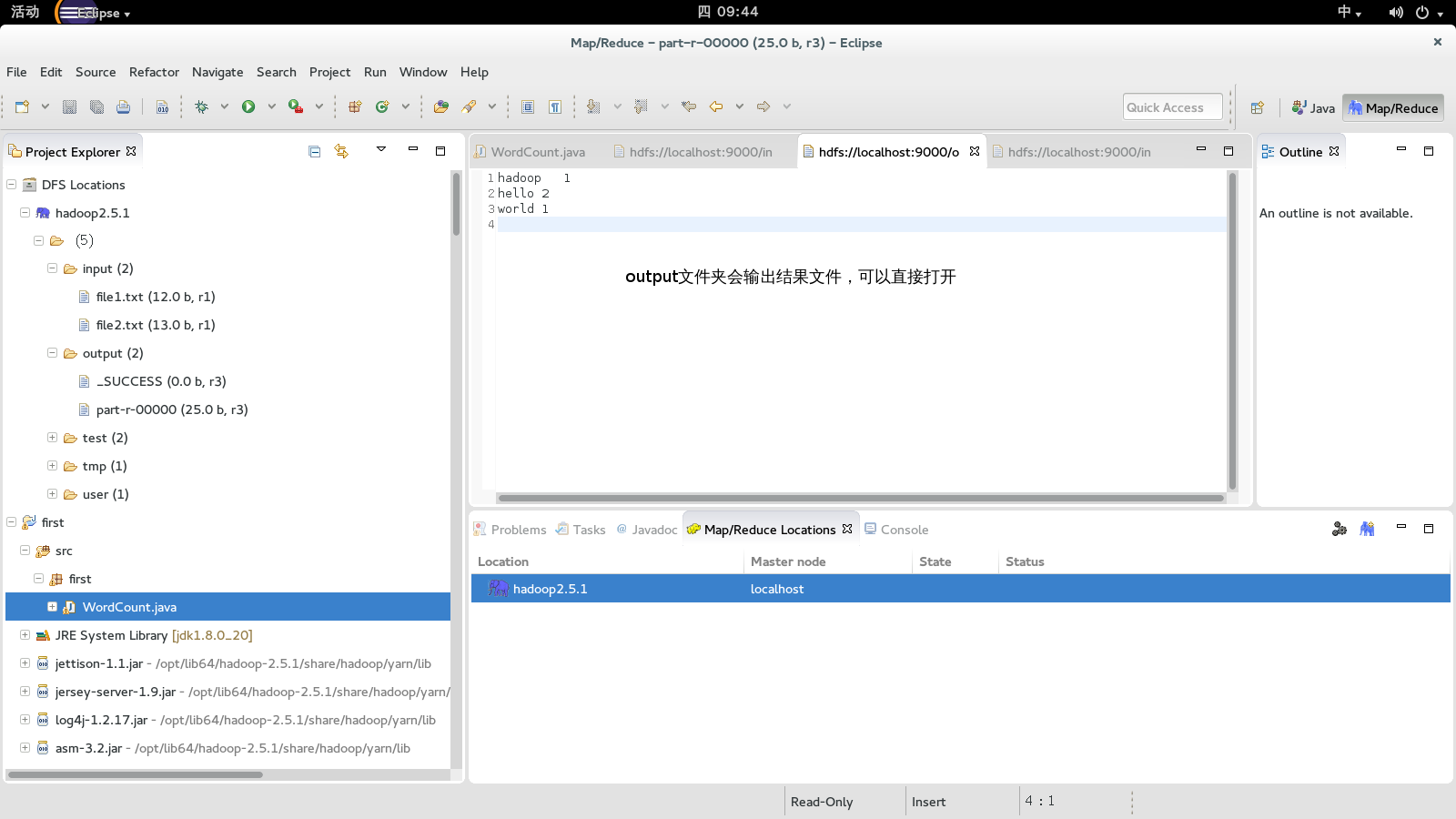
在input文件夹下面放置2个文件,比如file1.txt,file2.txt,然后运行过后程序会新建一个output文件夹,里面会包含结果
file1

file2.txt

output下面文件内容
在fedora20下配置hadoop2.5.1的eclipse插件的更多相关文章
- hadoop2.6.0的eclipse插件编译和设置
编译hadoop2.6.0的eclipse插件 下载源码: git clone https://github.com/winghc/hadoop2x-eclipse-plugin.git 编译源码: ...
- Hadoop-2.3.0的Eclipse插件编译
Hadoop-2.3.0的Eclipse插件编译 #cd /usr/local/src/hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugi ...
- Hadoop2.6.2的Eclipse插件的使用
欢迎转载,且请注明出处,在文章页面明显位置给出原文连接. 本文链接:http://www.cnblogs.com/zdfjf/p/5178197.html 首先给出eclipse插件的下载地址:htt ...
- Linux下配置C/C++开发环境-----Eclipse
先自己去官网下载jdk. 解压即安装. 然后在~/.bashrc文件里面配置下环境变量就行了.在文件最后添加以下路径,如下: JAVA_HOME=/home/username/jdk/jdk1.8.0 ...
- hadoop2.6.0的eclipse插件安装
1.安装插件 下载插件hadoop-eclipse-plugin-2.6.0.jar并将其放到eclips安装目录->plugins(插件)文件夹下.然后启动eclipse. 配置 hadoop ...
- Ubuntu14.04下安装Hadoop2.5.1 (单机模式)
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-standalone-mode.html,转载请注明源地址. 欢迎关注我的个人博客:www.wuyudo ...
- 二、Ubuntu14.04下安装Hadoop2.4.0 (伪分布模式)
在Ubuntu14.04下安装Hadoop2.4.0 (单机模式)基础上配置 一.配置core-site.xml /usr/local/hadoop/etc/hadoop/core-site.xml ...
- 在eclipse下编译hadoop2.0源码
Hadoop是一个分布式系统基础架构,由apache基金会维护并更新.官网地址: http://hadoop.apache.org/ Hadoop项目主要包括以下4个模块: Hadoop Common ...
- 【甘道夫】Win7x64环境下编译Apache Hadoop2.2.0的Eclipse小工具
目标: 编译Apache Hadoop2.2.0在win7x64环境下的Eclipse插件 环境: win7x64家庭普通版 eclipse-jee-kepler-SR1-win32-x86_64.z ...
随机推荐
- vim编辑器配置
原文链接:https://github.com/ma6174/vim http://my.oschina.net/swuly302/blog/156784?fromerr=itaFZFMb https ...
- Java 基础-反射
反射-Reflect 测试用到的代码 1.接口 Person.java public interface Person { Boolean isMale = true; void say(); voi ...
- Post的请求案例
1.简单的post请求案例 $.post(rootPath+"/jasframework/loginLog/getStatisticsInfoByUserId.do",functi ...
- bzoj4627: [BeiJing2016]回转寿司
权值线段树. 要求 L<=(s[i]-s[j])<=R (i<j). 的i和j的数量. 所以把前缀和s加入一棵权值线段树,每次询问满足条件的范围中的权值的个数. 权值线段树不能像普 ...
- highCharts图表应用-实现多种图表的显示
在数据统计和分析业务中,有时需要在一个图表中将柱状图.饼状图.曲线图的都体现出来,即可以从柱状图中看出具体数据.又能从曲线图中看出变化趋势,还能从饼状图中看出各部分数据比重.highCharts可以轻 ...
- Codeforces 435 B Pasha Maximizes【贪心】
题意:给出一串数字,给出k次交换,每次交换只能交换相邻的两个数,问最多经过k次交换,能够得到的最大的一串数字 从第一个数字往后找k个位置,找出最大的,往前面交换 有思路,可是没有写出代码来---sad ...
- Linux 查找文件方法
1) find -name httpd.conf 2) find /etc -name "*repo" 详情查找命令-> http://www.yesky.com/210/1 ...
- css去掉a标签点击后的虚线框
outline是css3的一个属性,用的很少. 声明,这是个不能兼容的css属性,在ie6.ie7.遨游浏览器都不兼容. outline控制的到底是什么呢? 当聚焦a标签的时候,在a标签的区域周围会有 ...
- 【C#学习笔记】文本复制到粘贴板
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- 每天一个Linux命令(1): find
1 find 命令是用来查找制定目录下符合条件的文件执行相应的动作(print exec等) find [path...] [expression] path:find命令所查找的目录路径.例如用.来 ...