mapred和mapreduce
总体上看,Hadoop MapReduce分为两部分:一部分是org.apache.hadoop.mapred.*,这里面主要包含旧的API接口以及MapReduce各个服务(JobTracker以及TaskTracker)的实现;另一部分是org.apache.hadoop.mapreduce.*,主要内容涉及新版本的API接口以及一些新特性(比如MapReduce安全)。hadoop版本1.x的包一般是mapreduce * hadoop版本0.x的包一般是mapred。
虽然hadoop 1.2.1源码的src文件夹下只有mapred文件夹而没有mapreduce,其实mapred文件夹是同时包含了mapred的旧API和mapreduce的新API的。如图所示:
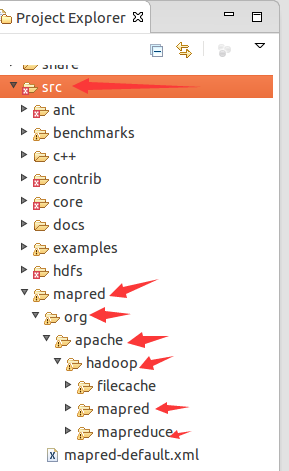
可以在这里阅读源码。
1. 首先第一条,也是小菜今天碰到这些问题的原因,新旧API不兼容。所以,以前用旧API写的hadoop程序,如果旧API不可用之后需要重写,也就是上面我的程序需要重写,如果旧API不能用的话,如果真不能用,这个有点儿小遗憾!
2. 新的API倾向于使用抽象类,而不是接口,使用抽象类更容易扩展。例如,我们可以向一个抽象类中添加一个方法(用默认的实现)而不用修改类之前的实现方法。因此,在新的API中,Mapper和Reducer是抽象类。
3. 新的API广泛使用context object(上下文对象),并允许用户代码与MapReduce系统进行通信。例如,在新的API中,MapContext基本上充当着JobConf的OutputCollector和Reporter的角色。
4. 新的API同时支持"推"和"拉"式的迭代。在这两个新老API中,键/值记录对被推mapper中,但除此之外,新的API允许把记录从map()方法中拉出,这也适用于reducer。分批处理记录是应用"拉"式的一个例子。
5. 新的API统一了配置。旧的API有一个特殊的JobConf对象用于作业配置,这是一个对于Hadoop通常的Configuration对象的扩展。在新的API中,这种区别没有了,所以作业配置通过Configuration来完成。作业控制的执行由Job类来负责,而不是JobClient,并且JobConf和JobClient在新的API中已经荡然无存。这就是上面提到的,为什么只有在mapred中才有Jobconf的原因。
6. 输出文件的命名也略有不同,map的输出命名为part-m-nnnnn,而reduce的输出命名为part-r-nnnnn,这里nnnnn指的是从0开始的部分编号。
这样了解了二者的区别就可以通过程序的引用包来判别新旧API编写的程序了。小菜建议最好用新的API编写hadoop程序,以防旧的API被抛弃!!!

新版API仍然会使用org.apache.hadoop.mapred中的一些类(可以这样理解,与org.apache.hadoop.mapred中的类相比,如果org.apache.hadoop.mapreduce中没有实现相关类,就说明新版API仍然使用这些类,如果实现了的,就会覆盖掉org.apache.hadoop.mapred中的相关类)。
以MapTask说明:
MapTask负责调度执行map操作,其中有个方法run(),在这个方法的内部,有段代码如下:
boolean useNewApi = job.getUseNewMapper();//是否使用新版API,true表示使用了新版API
initialize(job, getJobID(), reporter, useNewApi); // check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
} if (useNewApi) {
//使用了新版API就调用新方法
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {
runOldMapper(job, splitMetaInfo, umbilical, reporter);
}
参考:
http://blog.csdn.net/sun_168/article/details/7577346
mapred和mapreduce的更多相关文章
- hadoop mapred和mapreduce包
mapred包是老的1.0的map reduce api mapreduce包是新的2.0的map reduce api
- MapReduce实例浅析
在文章<MapReduce原理与设计思想>中,详细剖析了MapReduce的原理,这篇文章则通过实例重点剖析MapReduce 本文地址:http://www.cnblogs.com/ar ...
- Hadoop阅读笔记(三)——深入MapReduce排序和单表连接
继上篇了解了使用MapReduce计算平均数以及去重后,我们再来一探MapReduce在排序以及单表关联上的处理方法.在MapReduce系列的第一篇就有说过,MapReduce不仅是一种分布式的计算 ...
- Hadoop阅读笔记(二)——利用MapReduce求平均数和去重
前言:圣诞节来了,我怎么能虚度光阴呢?!依稀记得,那一年,大家互赠贺卡,短短几行字,字字融化在心里:那一年,大家在水果市场,寻找那些最能代表自己心意的苹果香蕉梨,摸着冰冷的水果外皮,内心早已滚烫.这一 ...
- MapReduce应用案例--简单排序
1. 设计思路 在MapReduce过程中自带有排序,可以使用这个默认的排序达到我们的目的. MapReduce 是按照key值进行排序的,我们在Map过程中将读入的数据转化成IntWritable类 ...
- MapReduce编程系列 — 6:多表关联
1.项目名称: 2.程序代码: 版本一(详细版): package com.mtjoin; import java.io.IOException; import java.util.Iterator; ...
- MapReduce编程系列 — 5:单表关联
1.项目名称: 2.项目数据: chile parentTom LucyTom JackJone LucyJone JackLucy MaryLucy Ben ...
- MapReduce编程系列 — 4:排序
1.项目名称: 2.程序代码: package com.sort; import java.io.IOException; import org.apache.hadoop.conf.Configur ...
- MapReduce编程系列 — 3:数据去重
1.项目名称: 2.程序代码: package com.dedup; import java.io.IOException; import org.apache.hadoop.conf.Configu ...
随机推荐
- python的egg包的安装和制作]
Defining Python Source Code Encodings Python egg 的安装 egg文件制作与安装 2011-06-10 14:22:50| 分类: python | ...
- 【转】C#中Invoke的用法
在多线程编程中,我们经常要在工作线程中去更新界面显示,而在多线程中直接调用界面控件的方法是错误的做法,Invoke 和 BeginInvoke 就是为了解决这个问题而出现的,使你在多线程中安全的更新界 ...
- 动态切换采用 CSplitterWnd 静态划分的视图布局(MFC)
标题读起来有些拗口,具体是什么情况,我们来看: 一.问题的提出 一个采用MFC开发的软件,其窗体视图采用CSplitterWnd三分,效果如下图所示: 图1 软件的默认视图布局 该MFC开发的软件功能 ...
- SQL 集合(笔记)
——SQL是关于集合的 oracle是关系型数据,其中的数据表都是有一定规律的数据的一个个集合,所以在使用SQL时,如果能按照集合的思路来进行时会节省很多效率,也鞥让语句更加的清晰明了. 1.四个集合 ...
- Nginx源码结构
上一章对Nginx的架构有了一个初步的了解.这章,为了对源码仔细的剖析,先要对Nginx的源码结构有一个了解.从宏观上把握源码模块的结构. 一.nginx源码的3个目录结构 在安装的nginx的目录下 ...
- Convert Geometry data into a Geography data in MS SQL Server
DECLARE @geog GEOGRAPHY; DECLARE @geom GEOMETRY; ); SET @geom = @geom.MakeValid() --Force to valid g ...
- JVM学习总结三——垃圾回收器
整两天再看调优分析的部分,发现实际运行环境下,还是要考虑配置垃圾回收器,所以这里就加一小章介绍一下. 首先来看一下HotSpot所支持回收期的关系图: 图中可以看到一共有7中垃圾回收器,以中间绿线为界 ...
- 用Swift重写公司OC项目(Day2)--创建OC与Swift的桥接文件,进而调用OC类库
昨天把项目中的图标以及启动转场图片弄好了,那么今天,我们可以开始慢慢进入到程序的编写当中了. 由于swift较新,所以类库还不够完善,但是不用担心,苹果早就出了解决方案,那就是使用桥接文件,通过桥接文 ...
- asf与vga视频为何无法同步播放?我来给你解释!
因为你的笔记本可以,所以你的台式机不可以,当然跟深刻的原因是,你的笔记本有什么特别硬件
- maven属性
Maven内置了三大特性:属性.Profile和资源过滤来支持构建的灵活性. 内置属性:主要有两个常用内置属性 ${basedir}表示项目根目录,即包含pom.xml文件的目录 ${version} ...