docker 部署 zookeeper+kafka 集群
主机三台
172.16.100.61
172.16.100.62
172.16.100.63
Docker 版本 当前最新版
# 部署zk有2种方法
## 注意 \后不要跟空格
一 . 端口映射
172.16.100.61 执行
docker run -tid --name=zk- \
--restart=always \
--privileged=true \
-p : \
-p : \
-p : \
-e ZOO_MY_ID= \
-e ZOO_SERVERS=server.="0.0.0.0:2888:3888 server.2=172.16.100.62:2888:3888 server.3=172.16.100.63:2888:3888" \
-v /data/kafka_cluster/zookeeper/data:/data \
zookeeper:latest
172.16.100.62 执行
docker run -tid --name=zk- \
--restart=always \
--privileged=true \
-p : \
-p : \
-p : \
-e ZOO_MY_ID= \
-e ZOO_SERVERS=server.="172.16.100.61:2888:3888 server.2=0.0.0.0:2888:3888 server.3=172.16.100.63:2888:3888" \
-v /data/kafka_cluster/zookeeper/data:/data \
zookeeper:latest
172.16.100.63 执行
docker run -tid --name=zk- \
--restart=always \
--privileged=true \
-p : \
-p : \
-p : \
-e ZOO_MY_ID= \
-e ZOO_SERVERS=server.="172.16.100.61:2888:3888 server.2=172.16.100.62:2888:3888 server.3=0.0.0.0:2888:3888" \
-v /data/kafka_cluster/zookeeper/data:/data \
zookeeper:latest
#查看集群状态
docker exec -it zk- bash ./bin/zkServer.sh status
二.直接走宿主机IP
每台机器都执行一次,只需要修改 ZOO_MY_ID 即可 只要ZOO_SERVERS 和你的ID一致即可
docker run -tid --name=zk- \
--restart=always \
--privileged=true \
--net=host \
-e ZOO_MY_ID= \
-e ZOO_SERVERS=server.="172.16.100.61:2888:3888 server.2=172.16.100.62:2888:3888 server.3=172.16.100.63:2888:3888" \
-v /data/kafka_cluster/zookeeper/data:/data \
zookeeper:latest
### 上述zk检查过后没有问题就可以进行下一步了 ###
解析主机名
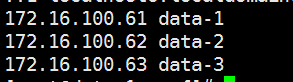
注意: kafka-logs-data-1 是主机的名字 如果你的主机是xxx 那这里应该改为kafka-logs-xxx
同时我映射了本地的hosts到容器里,所有容器获取到的主机名就是宿主机的名字
在61执行
docker run -itd --name=kafka \
--restart=always \
--net=host \
--privileged=true \
-v /etc/hosts:/etc/hosts \
-v /data/kafka_cluster/kafka/data:/kafka/kafka-logs-data- \
-v /data/kafka_cluster/kafka/logs:/opt/kafka/logs \
-e KAFKA_ADVERTISED_HOST_NAME=172.16.100.61 \
-e HOST_IP=172.16.100.61 \
-e KAFKA_ADVERTISED_PORT= \
-e KAFKA_ZOOKEEPER_CONNECT=172.16.100.61:,172.16.100.62:,172.16.100.63: \
-e KAFKA_BROKER_ID= \
-e KAFKA_HEAP_OPTS="-Xmx8196M -Xms8196M" \
wurstmeister/kafka:0.10.1.1
在62执行
docker run -itd --name=kafka \
--restart=always \
--net=host \
--privileged=true \
-v /etc/hosts:/etc/hosts \
-v /data/kafka_cluster/kafka/data:/kafka/kafka-logs-data- \
-v /data/kafka_cluster/kafka/logs:/opt/kafka/logs \
-e KAFKA_ADVERTISED_HOST_NAME=172.16.100.62 \
-e HOST_IP=172.16.100.62 \
-e KAFKA_ADVERTISED_PORT= \
-e KAFKA_ZOOKEEPER_CONNECT=172.16.100.61:,172.16.100.62:,172.16.100.63: \
-e KAFKA_BROKER_ID= \
-e KAFKA_HEAP_OPTS="-Xmx8196M -Xms8196M" \
wurstmeister/kafka:0.10.1.1
在63执行
docker run -itd --name=kafka \
--restart=always \
--net=host \
--privileged=true \
-v /etc/hosts:/etc/hosts \
-v /data/kafka_cluster/kafka/data:/kafka/kafka-logs-data- \
-v /data/kafka_cluster/kafka/logs:/opt/kafka/logs \
-e KAFKA_ADVERTISED_HOST_NAME=172.16.100.63 \
-e HOST_IP=172.16.100.63 \
-e KAFKA_ADVERTISED_PORT= \
-e KAFKA_ZOOKEEPER_CONNECT=172.16.100.61:,172.16.100.62:,172.16.100.63: \
-e KAFKA_BROKER_ID= \
-e KAFKA_HEAP_OPTS="-Xmx8196M -Xms8196M" \
wurstmeister/kafka:0.10.1.1
##创建topic test
#订阅
docker exec -it kafka bash /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server 172.16.100.61:9092,172.16.100.62:9092,172.16.100.63:9092 --topic test --from-beginning
#发送消息
docker exec -it kafka bash /opt/kafka/bin/kafka-console-producer.sh --broker-list 172.16.100.61:9092,172.16.100.62:9092,172.16.100.63:9092 --topic test
docker 部署 zookeeper+kafka 集群的更多相关文章
- Docker搭建Zookeeper&Kafka集群
最近在学习Kafka,准备测试集群状态的时候感觉无论是开三台虚拟机或者在一台虚拟机开辟三个不同的端口号都太麻烦了(嗯..主要是懒). 环境准备 一台可以上网且有CentOS7虚拟机的电脑 为什么使用虚 ...
- 在kubernetes上部署zookeeper,kafka集群
本文采用网上镜像:mirrorgooglecontainers/kubernetes-zookeeper:1.0-3.4.10 准备共享存储:nfs,glusterfs,seaweed或其他,并在no ...
- Linux Centos7 环境搭建Docker部署Zookeeper分布式集群服务实战
Zookeeper完全分布式集群服务 准备好3台服务器: [x]A-> centos-helios:192.168.19.1 [x]B-> centos-hestia:192.168.19 ...
- Zookeeper+Kafka集群部署(转)
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- Zookeeper+Kafka集群部署
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- zookeeper+kafka集群安装之二
zookeeper+kafka集群安装之二 此为上一篇文章的续篇, kafka安装需要依赖zookeeper, 本文与上一篇文章都是真正分布式安装配置, 可以直接用于生产环境. zookeeper安装 ...
- 搭建zookeeper+kafka集群
搭建zookeeper+kafka集群 一.环境及准备 集群环境: 软件版本: 部署前操作: 关闭防火墙,关闭selinux(生产环境按需关闭或打开) 同步服务器时间,选择公网ntpd服务器或 ...
- Docker 部署 RocketMQ Dledger 集群模式( 版本v4.7.0)
文章转载自:http://www.mydlq.club/article/97/ 系统环境: 系统版本:CentOS 7.8 RocketMQ 版本:4.7.0 Docker 版本:19.03.13 一 ...
- zookeeper+kafka集群安装之一
zookeeper+kafka集群安装之一 准备3台虚拟机, 系统是RHEL64服务版. 1) 每台机器配置如下: $ cat /etc/hosts ... # zookeeper hostnames ...
随机推荐
- golang第三方库goconfig的使用
参考地址:http://studygolang.com/articles/818 详细的解析可以看上面链接,这里只做一点简单介绍 先安装好包,然后导入 import ( "githu ...
- arcgis api for javascript本地部署加载地图
最近开始学习arcgis api for javascript,发现一头雾水,决定记录下自己的学习过程. 一.下载arcgis api for js 4.2的library和jdk,具体安装包可以去官 ...
- [BJWC2011]最小三角形
嘟嘟嘟 这一看就是平面分治的题,所以就想办法往这上面去靠. 关键就是到\(mid\)点的限制距离是什么.就是对于当前区间,所有小于这个距离的点都选出来,参与更新最优解. 假设从左右区间中得到的最优解是 ...
- no.random.randn
numpy中有一些常用的用来产生随机数的函数,randn就是其中一个,randn函数位于numpy.random中,函数原型如下: numpy.random.randn(d0, d1, ..., dn ...
- 关于C#的静态类和静态构造函数
静态构造函数是C#的一个新特性,其实好像很少用到.不过当我们想初始化一些静态变量的时候就需要用到它了.这个构造函数是属于类的,而不是属于哪里实例的,就是说这个构造函数只会被执行一次.也就是在创建第一个 ...
- java crm 进销存 springmvc SSM 项目 源码 系统
系统介绍: 1.系统采用主流的 SSM 框架 jsp JSTL bootstrap html5 (PC浏览器使用) 2.springmvc +spring4.3.7+ mybaits3.3 SSM ...
- OpenID Connect Core 1.0(九)声明(Claims)
5 声明(Claims) 这一节说明客户端如何获取关于终端用户声明和验证事件.它还定义了一组标准的基本声明配置.预定义一组可请求的声明,使用特定的scope值或能用于请求参数中的个人声明.声明可以直接 ...
- where语句中不能直接使用聚合函数
1.问题描述 select deptno ,avg(sal) from emp where count(*)>3 group by deptno; 在where 句中使用聚合函数count(*) ...
- Windows 的 Oracle Data Access Components (ODAC)
下载 x64bit https://www.oracle.com/technetwork/cn/database/windows/downloads/index.html 适用于 Windows 的 ...
- springboot快速入门(二)——项目属性配置(日志详解)
一.概述 application.properties就是springboot的属性配置文件 在使用spring boot过程中,可以发现项目中只需要极少的配置就能完成相应的功能,这归功于spring ...