Java并发编程原理与实战三十五:并发容器ConcurrentLinkedQueue原理与使用
一、简介
一个基于链接节点的无界线程安全队列。此队列按照 FIFO(先进先出)原则对元素进行排序。队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。
新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。此队列不允许使用 null 元素。
offer和poll
poll()
获取并移除此队列的头,如果此队列为空,则返回 null。

public static void main(String[] args) {
ConcurrentLinkedQueue queue = new ConcurrentLinkedQueue();
queue.offer("哈哈哈");
System.out.println("offer后,队列是否空?" + queue.isEmpty());
System.out.println("从队列中poll:" + queue.poll());
System.out.println("pool后,队列是否空?" + queue.isEmpty());
}
offer是往队列添加元素,poll是从队列取出元素并且删除该元素
执行结果
offer后,队列是否空?false
从队列中poll:哈哈哈
pool后,队列是否空?true
ConcurrentLinkedQueue中的add() 和 offer() 完全一样,都是往队列尾部添加元素
还有个取元素方法peek
peek()
获取但不移除此队列的头;如果此队列为空,则返回 null
public static void main(String[] args) {
ConcurrentLinkedQueue queue = new ConcurrentLinkedQueue();
queue.offer("哈哈哈");
System.out.println("offer后,队列是否空?" + queue.isEmpty());
System.out.println("从队列中peek:" + queue.peek());
System.out.println("从队列中peek:" + queue.peek());
System.out.println("从队列中peek:" + queue.peek());
System.out.println("pool后,队列是否空?" + queue.isEmpty());
}
执行结果:
offer后,队列是否空?false
从队列中peek:哈哈哈
从队列中peek:哈哈哈
从队列中peek:哈哈哈
pool后,队列是否空?false
remove
remove(Object o)
从队列中移除指定元素的单个实例(如果存在)
public static void main(String[] args) {
ConcurrentLinkedQueue queue = new ConcurrentLinkedQueue();
queue.offer("哈哈哈");
System.out.println("offer后,队列是否空?" + queue.isEmpty());
System.out.println("从队列中remove已存在元素 :" + queue.remove("哈哈哈"));
System.out.println("从队列中remove不存在元素:" + queue.remove("123"));
System.out.println("remove后,队列是否空?" + queue.isEmpty());
}
remove一个已存在元素,会返回true,remove不存在元素,返回false
执行结果:
offer后,队列是否空?false
从队列中remove已存在元素 :true
从队列中remove不存在元素:false
remove后,队列是否空?true
size or isEmpty
size()
返回此队列中的元素数量
注意:
如果此队列包含的元素数大于 Integer.MAX_VALUE,则返回 Integer.MAX_VALUE。
需要小心的是,与大多数 collection 不同,此方法不是 一个固定时间操作。由于这些队列的异步特性,确定当前的元素数需要进行一次花费 O(n) 时间的遍历。
所以在需要判断队列是否为空时,尽量不要用 queue.size()>0,而是用 !queue.isEmpty()
比较size()和isEmpty() 效率的示例:
场景:10000个人去饭店吃饭,10张桌子供饭,分别比较size() 和 isEmpty() 的耗时
public class Test01ConcurrentLinkedQueue {
public static void main(String[] args) throws InterruptedException {
int peopleNum = 10000;//吃饭人数
int tableNum = 10;//饭桌数量
ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<>();
CountDownLatch count = new CountDownLatch(tableNum);//计数器
//将吃饭人数放入队列(吃饭的人进行排队)
for(int i=1;i<=peopleNum;i++){
queue.offer("消费者_" + i);
}
//执行10个线程从队列取出元素(10个桌子开始供饭)
System.out.println("-----------------------------------开饭了-----------------------------------");
long start = System.currentTimeMillis();
ExecutorService executorService = Executors.newFixedThreadPool(tableNum);
for(int i=0;i<tableNum;i++) {
executorService.submit(new Dinner("00" + (i+1), queue, count));
}
//计数器等待,知道队列为空(所有人吃完)
count.await();
long time = System.currentTimeMillis() - start;
System.out.println("-----------------------------------所有人已经吃完-----------------------------------");
System.out.println("共耗时:" + time);
//停止线程池
executorService.shutdown();
}
private static class Dinner implements Runnable{
private String name;
private ConcurrentLinkedQueue<String> queue;
private CountDownLatch count;
public Dinner(String name, ConcurrentLinkedQueue<String> queue, CountDownLatch count) {
this.name = name;
this.queue = queue;
this.count = count;
}
@Override
public void run() {
//while (queue.size() > 0){
while (!queue.isEmpty()){
//从队列取出一个元素 排队的人少一个
System.out.println("【" +queue.poll() + "】----已吃完..., 饭桌编号:" + name);
}
count.countDown();//计数器-1
}
}
}
执行结果:
使用size耗时:757ms
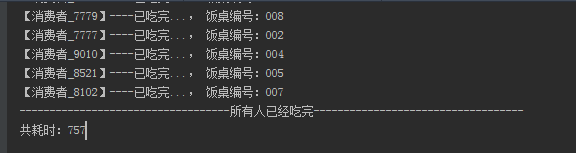
使用isEmpty耗时:210

当数据量越大,这种耗时差距越明显。所以这种判断用isEmpty 更加合理
contains
contains(Object o)
如果此队列包含指定元素,则返回 true
public static void main(String[] args) throws InterruptedException {
ConcurrentLinkedQueue queue = new ConcurrentLinkedQueue();
queue.offer("123");
System.out.println(queue.contains("123"));
System.out.println(queue.contains("234"));
}
执行结果:

toArray
toArray()
返回以恰当顺序包含此队列所有元素的数组
toArray(T[] a)
返回以恰当顺序包含此队列所有元素的数组;返回数组的运行时类型是指定数组的运行时类型
public static void main(String[] args) throws InterruptedException {
ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<String>();
queue.offer("123");
queue.offer("234");
Object[] objects = queue.toArray();
System.out.println(objects[0] + ", " + objects[1]);
//将数据存储到指定数组
String[] strs = new String[2];
queue.toArray(strs);
System.out.println(strs[0] + ", " + strs[1]);
}
执行结果:

iterator
iterator()
返回在此队列元素上以恰当顺序进行迭代的迭代器
public static void main(String[] args) throws InterruptedException {
ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<String>();
queue.offer("123");
queue.offer("234");
Iterator<String> iterator = queue.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
ConcurrentLinkedQueue文档说明:
| 构造方法摘要 | |
|---|---|
ConcurrentLinkedQueue() 创建一个最初为空的 ConcurrentLinkedQueue。 |
|
ConcurrentLinkedQueue(Collection<? extends E> c) 创建一个最初包含给定 collection 元素的 ConcurrentLinkedQueue,按照此 collection 迭代器的遍历顺序来添加元素。 |
|
| 方法摘要 | ||
|---|---|---|
boolean |
add(E e) 将指定元素插入此队列的尾部。 |
|
boolean |
contains(Object o) 如果此队列包含指定元素,则返回 true。 |
|
boolean |
isEmpty() 如果此队列不包含任何元素,则返回 true。 |
|
Iterator<E> |
iterator() 返回在此队列元素上以恰当顺序进行迭代的迭代器。 |
|
boolean |
offer(E e) 将指定元素插入此队列的尾部。 |
|
E |
peek() 获取但不移除此队列的头;如果此队列为空,则返回 null。 |
|
E |
poll() 获取并移除此队列的头,如果此队列为空,则返回 null。 |
|
boolean |
remove(Object o) 从队列中移除指定元素的单个实例(如果存在)。 |
|
int |
size() 返回此队列中的元素数量。 |
|
Object[] |
toArray() 返回以恰当顺序包含此队列所有元素的数组。 |
|
|
toArray(T[] a) 返回以恰当顺序包含此队列所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。 |
|
二、源代码解析
offer操作是在链表末尾添加一个元素,下面看看实现原理。
public boolean offer(E e) {
//e为null则抛出空指针异常
checkNotNull(e);
//构造Node节点构造函数内部调用unsafe.putObject,后面统一讲
final Node<E> newNode = new Node<E>(e);
//从尾节点插入
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
//如果q=null说明p是尾节点则插入
if (q == null) {
//cas插入(1)
if (p.casNext(null, newNode)) {
//cas成功说明新增节点已经被放入链表,然后设置当前尾节点(包含head,1,3,5.。。个节点为尾节点)
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q)//(2)
//多线程操作时候,由于poll时候会把老的head变为自引用,然后head的next变为新head,所以这里需要
//重新找新的head,因为新的head后面的节点才是激活的节点
p = (t != (t = tail)) ? t : head;
else
// 寻找尾节点(3)
p = (p != t && t != (t = tail)) ? t : q;
}
}
从构造函数知道一开始有个item为null的哨兵节点,并且head和tail都是指向这个节点,然后当一个线程调用offer时候首先

如图首先查找尾节点,q==null,p就是尾节点,所以执行p.casNext通过cas设置p的next为新增节点,这时候p==t所以不重新设置尾节点为当前新节点。由于多线程可以调用offer方法,所以可能两个线程同时执行到了(1)进行cas,那么只有一个会成功(假如线程1成功了),成功后的链表为:

失败的线程会循环一次这时候指针为:

这时候会执行(3)所以p=q,然后在循环后指针位置为:

所以没有其他线程干扰的情况下会执行(1)执行cas把新增节点插入到尾部,没有干扰的情况下线程2 cas会成功,然后去更新尾节点tail,由于p!=t所以更新。这时候链表和指针为:

假如线程2cas时候线程3也在执行,那么线程3会失败,循环一次后,线程3的节点状态为:

这时候p!=t ;并且t的原始值为told,t的新值为tnew ,所以told!=tnew,所以 p=tnew=tail;
然后在循环一下后节点状态:

q==null所以执行(1)。
现在就差p==q这个分支还没有走,这个要在执行poll操作后才会出现这个情况。poll后会存在下面的状态

这个时候添加元素时候指针分布为:

所以会执行(2)分支 结果 p=head
然后循环,循环后指针分布:

所以执行(1),然后p!=t所以设置tail节点。现在分布图:

自引用的节点会被垃圾回收掉。
本节引自:http://www.importnew.com/25668.html ,可以参考此文。
三、concurrentLinkedQueue的特性
1、应用场景
按照适用的并发强度从低到高排列如下:
LinkedList/ArrayList 非线程安全,不能用于并发场景(List的方法支持栈和队列的操作,因此可以用List封装成stack和queue)
Collections.synchronizedList 使用wrapper class封装,每个方法都用synchronized(mutex:Object)做了同步
LinkedBlockingQueue 采用了锁分离的设计,避免了读/写操作冲突,且自动负载均衡,可以有界。BlockingQueue在生产-消费模式下首选【Iterator安全,不保证数据一致性】
ConcurrentLinkedQueue 适用于高并发读写操作,理论上有最高的吞吐量,无界,不保证数据访问实时一致性,Iterator不抛出并发修改异常,采用CAS机制实现无锁访问。
综上:
在并发的场景下,如果并发强度较小,性能要求不苛刻,且锁可控的场景下,可使用Collections.synchronizedList,既保证了数据一致又保证了线程安全,性能够用;
在大部分高并发场景下,建议使用 LinkedBlockingQueue ,性能与 ConcurrentLinkedQueue 接近,且能保证数据一致性;
ConcurrentLinkedQueue 适用于超高并发的场景,但是需要针对数据不一致采取一些措施。
2、特点
2.1 访问操作采用了无锁设计
2.2 Iterator的弱一致性,即不保证Iteartor访问数据的实时一致性(与current组的成员与COW成员类似)
2.3 并发poll
2.4 并发add
2.5 poll/add并发
3、注意事项
3.1 size操作不是一个固定时长的操作(not a constant-time operation)
因为size需要遍历整个queue,如果此时queue正在被修改,size可能返回不准确的数值(仍然是无法保证数据一致性),就像concurrentHashMap一样,
要获取size,需要取得所有的bucket的锁,这是一个非常耗时的操作。因此如果需要保证数据一致性,频繁获取集合对象的size,最好不使用concurrent
族的成员。
3.2 批量操作(bulk operations like addAll,removeAll,equals)无法保证原子性,因为不保证实时性,且没有使用独占锁的设计。
例如,在执行addAll的同时,有另外一个线程通过Iterator在遍历,则遍历的线程可能只看到一部分新增的数据。
3.3 ConcurrentLinkedQueue 没有实现BlockingQueue接口
当队列为空时,take方法返回null,此时consumer会需要处理这个情况,consumer会循环调用take来保证及时获取数据,此为busy waiting,会持续消耗CPU资源。
4、与 LinkedBlockingQueue 的对比
LinkedBlockingQueue 采用了锁分离的设计,put、get锁分离,保证两种操作的并发,但同一种操作,然后是锁控制的。并且当队列为空/满时,某种操作
会被挂起。
4.1 并发性能
4.1.1 高并发put操作
可支持高并发场景下,多线程无锁put操作
4.1.2 高并发的put/poll操作
多线程场景,同时put,遍历,以及poll,均可无锁操作。但不保证遍历的实时一致性。
4.2 数据的实时一致性
两者的Iterator都不不保证数据一致性,Iterator遍历的是Iterator创建时已存在的节点,创建后的修改不保证能反应出来。
参考 LinkedBlockingQueue 的java doc关于Iterator的解释:
The returned iterator is a "weakly consistent" iterator that will never throw ConcurrentModificationException, and guarantees to traverse elements as they existed upon construction of the iterator, and may (but is not guaranteed to) reflect any modifications subsequent to construction.
4.3 遍历操作(Iterator的遍历操作的差异)
目前看来,没有差异
4.4 size操作
LinkedBlockingQueue 的size是在内部用一个AtomicInteger保存,执行size操作直接获取此原子量的当前值,时间复杂度O(1)。
ConcurrentLinkedQueue 的size操作需要遍历(traverse the queue),因此比较耗时,时间复杂度至少为O(n),建议使用isEmpty()。
The java doc says the size() method is typically not very useful in concurrent applications.
5.LinkedBlockingQueue和ConcurrentLinkedQueue适用场景
当许多线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。
如果CLQ,那么我需要收到处理sleep
阻塞队列:线程安全
按 FIFO(先进先出)排序元素。队列的头部 是在队列中时间最长的元素。队列的尾部 是在队列中时间最短的元素。新元素插入到队列的尾部,并且队列检索操作会获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可预知的性能要低。
注意:
1、必须要使用take()方法在获取的时候达成阻塞结果
2、使用poll()方法将产生非阻塞效果
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit; public class BlockingDeque {
//阻塞队列,FIFO
private static LinkedBlockingQueue<Integer> concurrentLinkedQueue = new LinkedBlockingQueue<Integer>(); public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(2); executorService.submit(new Producer("producer1"));
executorService.submit(new Producer("producer2"));
executorService.submit(new Producer("producer3"));
executorService.submit(new Consumer("consumer1"));
executorService.submit(new Consumer("consumer2"));
executorService.submit(new Consumer("consumer3")); } static class Producer implements Runnable {
private String name; public Producer(String name) {
this.name = name;
} public void run() {
for (int i = 1; i < 10; ++i) {
System.out.println(name+ " 生产: " + i);
//concurrentLinkedQueue.add(i);
try {
concurrentLinkedQueue.put(i);
Thread.sleep(200); //模拟慢速的生产,产生阻塞的效果
} catch (InterruptedException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} }
}
} static class Consumer implements Runnable {
private String name; public Consumer(String name) {
this.name = name;
}
public void run() {
for (int i = 1; i < 10; ++i) {
try {
//必须要使用take()方法在获取的时候阻塞
System.out.println(name+"消费: " + concurrentLinkedQueue.take());
//使用poll()方法 将产生非阻塞效果
//System.out.println(name+"消费: " + concurrentLinkedQueue.poll()); //还有一个超时的用法,队列空时,指定阻塞时间后返回,不会一直阻塞
//但有一个疑问,既然可以不阻塞,为啥还叫阻塞队列?
//System.out.println(name+" Consumer " + concurrentLinkedQueue.poll(300, TimeUnit.MILLISECONDS));
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} }
}
}
}
非阻塞队列
基于链接节点的、无界的、线程安全。此队列按照 FIFO(先进先出)原则对元素进行排序。队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。新的元素插入到队列的尾部,队列检索操作从队列头部获得元素。当许多线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。此队列不允许 null 元素。
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.TimeUnit; public class NoBlockQueue {
private static ConcurrentLinkedQueue<Integer> concurrentLinkedQueue = new ConcurrentLinkedQueue<Integer>(); public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(2); executorService.submit(new Producer("producer1"));
executorService.submit(new Producer("producer2"));
executorService.submit(new Producer("producer3"));
executorService.submit(new Consumer("consumer1"));
executorService.submit(new Consumer("consumer2"));
executorService.submit(new Consumer("consumer3")); } static class Producer implements Runnable {
private String name; public Producer(String name) {
this.name = name;
} public void run() {
for (int i = 1; i < 10; ++i) {
System.out.println(name+ " start producer " + i);
concurrentLinkedQueue.add(i);
try {
Thread.sleep(20);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//System.out.println(name+"end producer " + i);
}
}
} static class Consumer implements Runnable {
private String name; public Consumer(String name) {
this.name = name;
}
public void run() {
for (int i = 1; i < 10; ++i) {
try { System.out.println(name+" Consumer " + concurrentLinkedQueue.poll()); } catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// System.out.println();
// System.out.println(name+" end Consumer " + i);
}
}
}
}
在并发编程中,一般推荐使用阻塞队列,这样实现可以尽量地避免程序出现意外的错误。阻塞队列使用最经典的场景就是socket客户端数据的读取和解析,读取数据的线程不断将数据放入队列,然后解析线程不断从队列取数据解析。还有其他类似的场景,只要符合生产者-消费者模型的都可以使用阻塞队列。
使用非阻塞队列,虽然能即时返回结果(消费结果),但必须自行编码解决返回为空的情况处理(以及消费重试等问题)。
另外他们都是线程安全的,不用考虑线程同步问题。
Java并发编程原理与实战三十五:并发容器ConcurrentLinkedQueue原理与使用的更多相关文章
- Java并发编程原理与实战三十二:ForkJoin框架详解
1.Fork/Join框架有什么用呢? ------->Fork使用来切分任务,Join是用来汇总结果.举个简单的栗子:任务是1+2+3+...+100这个任务(当然这个任务的结果有好的算法去做 ...
- Java并发编程原理与实战二十五:ThreadLocal线程局部变量的使用和原理
1.什么是ThreadLocal ThreadLocal顾名思义是线程局部变量.这种变量和普通的变量不同,这种变量在每个线程中通过get和set方法访问, 每个线程有自己独立的变量副本.线程局部变量不 ...
- Java并发编程原理与实战三十六:阻塞队列&消息队列
一.阻塞队列 1.阻塞队列BlockingQueue ---->可以理解成生产者消费者的模式---->消费者要等待到生产者生产出来产品.---->而非阻塞队列ConcurrentLi ...
- Java并发编程原理与实战三十八:多线程调度器(ScheduledThreadPoolExecutor)
在前面介绍了java的多线程的基本原理信息:线程池的原理与使用 本文对这个java本身的线程池的调度器做一个简单扩展,如果还没读过上一篇文章,建议读一下,因为这是调度器的核心组件部分. 我们如果要用j ...
- Java并发编程原理与实战三十四:并发容器CopyOnWriteArrayList原理与使用
1.ArrayList的实现原理是怎样的呢? ------>例如:ArrayList本质是实现了一个可变长度的数组. 假如这个数组的长度为10,调用add方法的时候,下标会移动到下一位,当移动到 ...
- Java并发编程原理与实战三十:CountDownLatch与CyclicBarrier 区别
相信每个想深入了解多线程开发的Java开发者都会遇到CountDownLatch和CyclicBarrier,大家也在网上看到各种介绍原理,代码的,以及他们区别(应付面试)的,但是很少能讲清楚:他们到 ...
- Java并发编程原理与实战三十九:JDK8新增锁StampedLock详解
1.StampedLock是做什么的? ----->它是ReentrantReadWriteLock 的增强版,是为了解决ReentrantReadWriteLock的一些不足. 2.Ree ...
- Java并发编程原理与实战四十五:问题定位总结
背景 “线下没问题的”. “代码不可能有问题 是系统原因”.“能在线上远程debug么” 线上问题不同于开发期间的bug,与运行时环境.压力.并发情况.具体的业务相关.对于线上的问题利用线上 ...
- Java并发编程原理与实战三十七:线程池的原理与使用
一.简介 线程池在我们的高并发环境下,实际应用是非常多的!!适用频率非常高! 有过使用过Executors框架的朋友,可能不太知道底层的实现,这里就是讲Executors是由ThreadPoolExe ...
随机推荐
- [建树(非二叉树)] 1090. Highest Price in Supply Chain (25)
1090. Highest Price in Supply Chain (25) A supply chain is a network of retailers(零售商), distributors ...
- vue之Mutations 理解
commit:提交可以在组件中使用 this.$store.commit('xxx') 提交 mutation,或者使用 mapMutations 辅助函数将组件中的 methods 映射为 stor ...
- Spring 计划 7.0
Sprint回顾 让我们一次比一次做得更好. 1.回顾组织 主题:“我们怎样才能在下个sprint中做的更好?” 时间:设定为1小时. 参与者:整个团队. 场所:宿舍. 秘书:李新佳. 2. ...
- [转帖] IPsec相关知识 --未知来源
目 录 IPsec IPsec简介 IPsec的协议实现 IPsec基本概念 加密卡 IPsec虚拟隧道接口 使用IPsec保护IPv6路由协议 IKE IKE简介 IKE的安全机制 IKE的交换过 ...
- AJAX 跨域问题 php
原生ajax请求方式: var xhr = new XMLHttpRequest(); xhr.open("POST", "http://xxxx.com/demo/b/ ...
- getcontext makecontext setcontext swapcontext介绍
ucontext簇函数学习 https://github.com/zfengzhen/Blog/blob/master/article/ucontext%E7%B0%87%E5%87%BD%E6%95 ...
- 使用flex布局调换两个按钮的位置
组件用的时antd的Modal组件,里面的按钮需要调换一下位置 今天发现用flex布局非常方便,代码如下: display: flex; justify-content: center; flex-f ...
- 二分图最大匹配模板(pascal)
uoj#78. 二分图最大匹配 从前一个和谐的班级,有 nlnl 个是男生,有 nrnr 个是女生.编号分别为 1,…,nl1,…,nl 和 1,…,nr1,…,nr. 有若干个这样的条件:第 vv ...
- Java pdf转String 并修正格式
在尝试pdf转成String的时候,首先用python的pdfminer和pdfminer3k去尝试转换,然后资料看不太懂,就尝试用了java, 以下是java的pdfbox写的pdf转String函 ...
- 【刷题】BZOJ 2157 旅游
Description Ray 乐忠于旅游,这次他来到了T 城.T 城是一个水上城市,一共有 N 个景点,有些景点之间会用一座桥连接.为了方便游客到达每个景点但又为了节约成本,T 城的任意两个景点之间 ...