【数据结构与算法Python版学习笔记】树——利用二叉堆实现优先级队列
概念
- 队列有一个重要的变体,叫作优先级队列。
- 和队列一样,优先级队列从头部移除元素,不过元素的逻辑顺序是由优先级决定的。
- 优先级最高的元素在最前,优先级最低的元素在最后。
- 实现优先级队列的经典方法是使用叫作
二叉堆(Binary Heap)的数据结构。- 二叉堆的入队操作和出队操作均可达到O(log n)。
- 其逻辑结构上像二叉树, 却是用非嵌套的列表来实现的
- 二叉堆有两个常见的变体:
- 最小堆(最小的元素一直在队首)
- 最大堆(最大的元素一直在队首)
二叉堆的操作
BinaryHeap()新建一个空的二叉堆。insert(k)往堆中加入一个新元素。findMin()返回最小的元素,元素留在堆中。delMin()返回最小的元素,并将该元素从堆中移除。isEmpty()在堆为空时返回True,否则返回False。size()返回堆中元素的个数。buildHeap(list)根据一个列表创建堆。
用非嵌套列表实现二叉堆
结构属性
- 为了使堆操作能保持在对数水平上, 就必须采用二叉树结构;
- 同样, 如果要使操作始终保持在对数数量级上, 就必须始终保持二叉树的“平衡”
- 树根左右子树拥有相同数量的节点
- 我们采用“
完全二叉树”的结构来近似实现“平衡”
完全二叉树,叶节点最多只出现在最底层和次底层,而且最底层的叶节点都连续集中在最左边,每个内部节点都有两个子节点, 最多可有1个节点例外- 下标为p
- 左子节点下标为2p
- 右子节点为2p+1
- 父节点下标为p//2
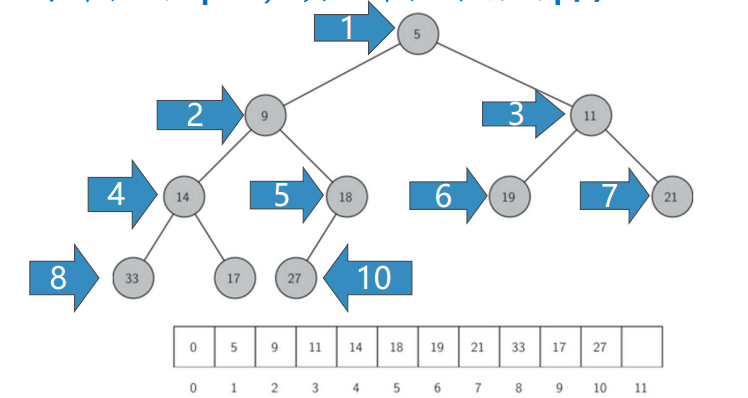
堆次序 Heap Order
- 任何一个节点x, 其父节点p中的key均小于x中的key
这样,符合“堆”性质的二叉树,其中任何一条路径,均是一个已排序数列, 根节点的key最小
二叉堆操作的实现
二叉堆初始化
- 采用一个列表来保存堆数据,其中表首下标为0的项无用,但为了后面代码可以用到简单的整数乘除法,仍保留它。
class BinHeap:
def __init__(self):
self.heapList=[0]
self.currentSize=0
insert(key)方法
- 新key加在列表末尾,显然无法保持“堆”次序虽然对其它路径的次序没有影响,但对于其到根的路径可能破坏次序
- 需要将新key沿着路径来“上浮”到其正确位置
- 注意:新key的“上浮”不会影响其它路径节点的“堆”次序
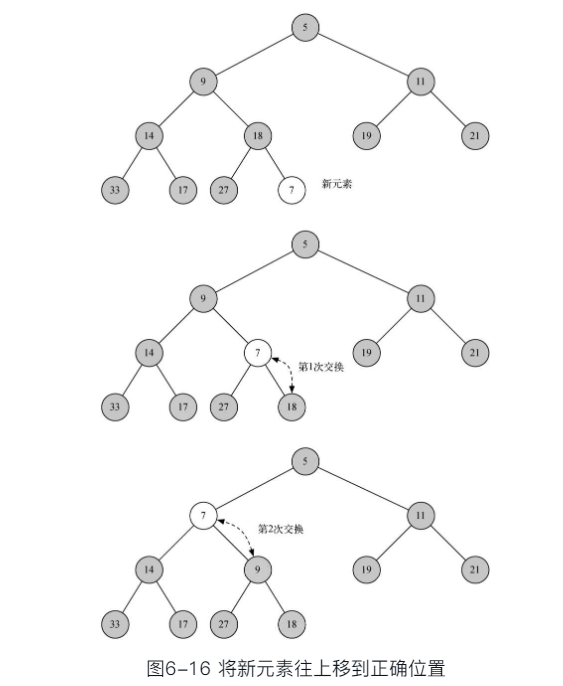
# 上浮
def percUp(self, i):
while i//2 > 0:
if self.heapList[i] < self.heapList[i//2]:
self.heapList[i], self.heapList[i //
2] = self.heapList[i//2], self.heapList[i]
i = i//2
def insert(self, k):
self.heapList.append(k)
self.currentSize += 1
self.percUp(self.currentSize)
delMin()方法
- 移走整个堆中最小的key:根节点heapList[1]
- 为了保持“完全二叉树”的性质,只用最后一个节点来代替根节点.
- 将新的根节点沿着一条路径“下沉”,直到比两个子节点都小
- “下沉”路径的选择:如果比子节点大,那么选择较小的子节点交换下沉
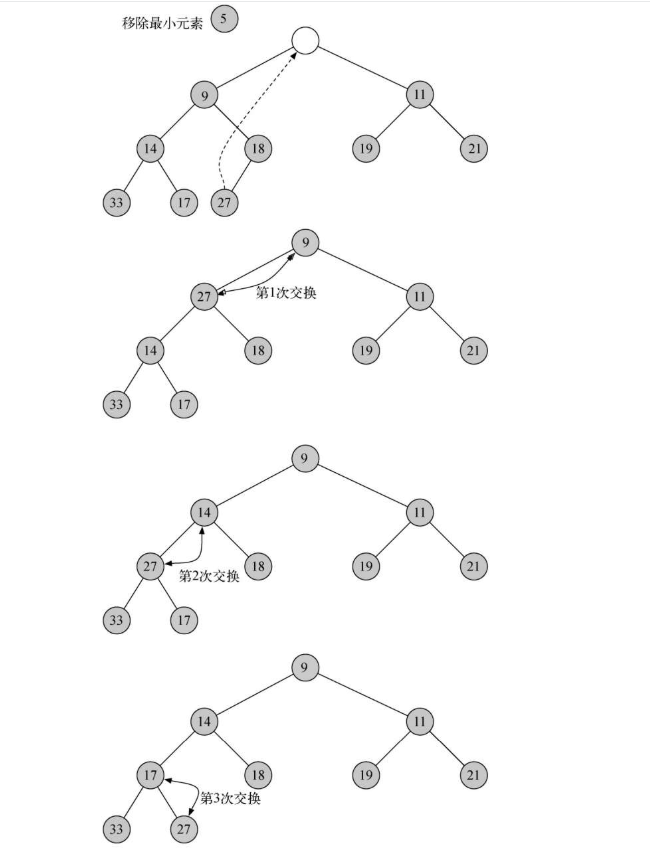
def percDown(self, i):
while(i*2) <= self.currentSize:
mc = self.minChild(i)
if self.heapList[i] > self.heapList(mc):
self.heapList[i], self.heapList[mc] = self.heapList[mc], self.heapList[i]
i = mc
def minChild(self, i):
if i*2+1 > self.currentSize:
return i*2
else:
if self.heapList[i*2] < self.heapList[i*2+1]:
return i*2
else:
return i*2+1
def delMin(self):
retval = self.heapList[1]
self.heapList[1] = self.heapList[self.currentSize]
self.currentSize -= 1
self.heapList.pop()
self.percDown(1)
return retval
buildHeap(lst)方法:从无序表生成“堆”
- 用insert(key)方法,将无序表中的数据项逐个insert到堆中,但这么做的总代价是O(nlog n)
- 其实,用“下沉”法,能够将总代价控制在O(n)
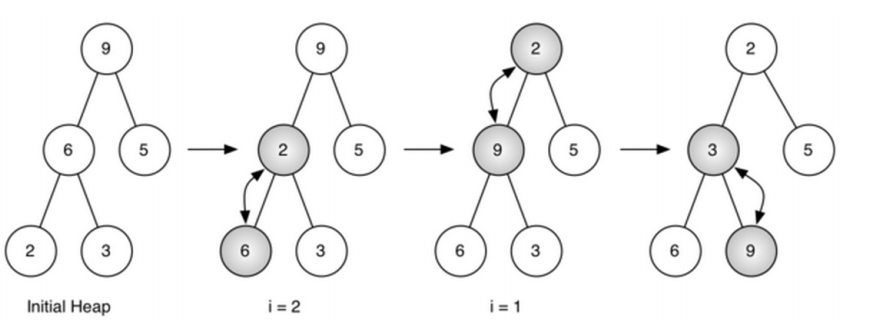
def buildHeap(self, alist):
i = len(alist)//2
self.currentSize = len(alist)
self.heapList = [0]+alist[:]
print(len(self.heapList), i)
while(i > 0):
print(self.heapList, i)
self.percDown(i)
i -= 1
print(self.heapList, i)
堆排序
- “堆排序”算法: O(nlog n)
二叉堆列表实现完整代码
class BinHeap:
def __init__(self):
self.heapList = [0]
self.currentSize = 0
# 上浮
def percUp(self, i):
while i//2 > 0:
if self.heapList[i] < self.heapList[i//2]:
self.heapList[i], self.heapList[i //
2] = self.heapList[i//2], self.heapList[i]
i = i//2
def insert(self, k):
self.heapList.append(k)
self.currentSize += 1
self.percUp(self.currentSize)
def percDown(self, i):
while(i*2) <= self.currentSize:
mc = self.minChild(i)
if self.heapList[i] > self.heapList(mc):
self.heapList[i], self.heapList[mc] = self.heapList[mc], self.heapList[i]
i = mc
def minChild(self, i):
if i*2+1 > self.currentSize:
return i*2
else:
if self.heapList[i*2] < self.heapList[i*2+1]:
return i*2
else:
return i*2+1
def delMin(self):
retval = self.heapList[1]
self.heapList[1] = self.heapList[self.currentSize]
self.currentSize -= 1
self.heapList.pop()
self.percDown(1)
return retval
def buildHeap(self, alist):
i = len(alist)//2
self.currentSize = len(alist)
self.heapList = [0]+alist[:]
print(len(self.heapList), i)
while(i > 0):
print(self.heapList, i)
self.percDown(i)
i -= 1
print(self.heapList, i)
【数据结构与算法Python版学习笔记】树——利用二叉堆实现优先级队列的更多相关文章
- 【数据结构与算法Python版学习笔记】目录索引
引言 算法分析 基本数据结构 概览 栈 stack 队列 Queue 双端队列 Deque 列表 List,链表实现 递归(Recursion) 定义及应用:分形树.谢尔宾斯基三角.汉诺塔.迷宫 优化 ...
- 【数据结构与算法Python版学习笔记】引言
学习来源 北京大学-数据结构与算法Python版 目标 了解计算机科学.程序设计和问题解决的基本概念 计算机科学是对问题本身.问题的解决.以及问题求解过程中得出的解决方案的研究.面对一 个特定问题,计 ...
- 【数据结构与算法Python版学习笔记】树——平衡二叉搜索树(AVL树)
定义 能够在key插入时一直保持平衡的二叉查找树: AVL树 利用AVL树实现ADT Map, 基本上与BST的实现相同,不同之处仅在于二叉树的生成与维护过程 平衡因子 AVL树的实现中, 需要对每个 ...
- 【数据结构与算法Python版学习笔记】树——二叉查找树 Binary Search Tree
二叉搜索树,它是映射的另一种实现 映射抽象数据类型前面两种实现,它们分别是列表二分搜索和散列表. 操作 Map()新建一个空的映射. put(key, val)往映射中加入一个新的键-值对.如果键已经 ...
- 【数据结构与算法Python版学习笔记】图——骑士周游问题 深度优先搜索
骑士周游问题 概念 在一个国际象棋棋盘上, 一个棋子"马"(骑士) , 按照"马走日"的规则, 从一个格子出发, 要走遍所有棋盘格恰好一次.把一个这样的走棋序列 ...
- 【数据结构与算法Python版学习笔记】递归(Recursion)——定义及应用:分形树、谢尔宾斯基三角、汉诺塔、迷宫
定义 递归是一种解决问题的方法,它把一个问题分解为越来越小的子问题,直到问题的规模小到可以被很简单直接解决. 通常为了达到分解问题的效果,递归过程中要引入一个调用自身的函数. 举例 数列求和 def ...
- 【数据结构与算法Python版学习笔记】树——相关术语、定义、实现方法
概念 一种基本的"非线性"数据结构--树 根 枝 叶 广泛应用于计算机科学的多个领域 操作系统 图形学 数据库 计算机网络 特征 第一个属性是层次性,即树是按层级构建的,越笼统就越 ...
- 【数据结构与算法Python版学习笔记】树——二叉树的应用:解析树
解析树(语法树) 将树用于表示语言中句子, 可以分析句子的各种语法成分, 对句子的各种成分进行处理 语法分析树 程序设计语言的编译 词法.语法检查 从语法树生成目标代码 自然语言处理 机器翻译 语义理 ...
- 【数据结构与算法Python版学习笔记】树——树的遍历 Tree Traversals
遍历方式 前序遍历 在前序遍历中,先访问根节点,然后递归地前序遍历左子树,最后递归地前序遍历右子树. 中序遍历 在中序遍历中,先递归地中序遍历左子树,然后访问根节点,最后递归地中序遍历右子树. 后序遍 ...
随机推荐
- Python之requests模块-response
response类故名思议,它包含了服务器对http请求的响应.每次调用requests去请求之后,均会返回一个response对象,通过调用该对象,可以查看具体的响应信息. 示例如下: import ...
- 史上最全git命令集
配置化命令 git config --global user.name "Your Name" git config --global user.email "email ...
- python 修改图像大小和分辨率
1 概念: 分辨率,指的是图像或者显示屏在长和宽上各拥有的像素个数.比如一张照片分辨率为1920x1080,意思是这张照片是由横向1920个像素点和纵向1080个像素点构成,一共包含了1920x108 ...
- three+pixi 将二维和三维结合
PIXI+THREE 使用 PIXI 和 THREE 将三维和二维渲染在同一个 canvas 下面 效果 思路 初始化 PIXI 的 Application, 作为 pixi 最重要的变量 const ...
- Python - pip-review 库
使用 pip-review 库(推荐) 安装库 pip install pip-review 检查是否有需要更新的包 > pip-review scikit-learn==0.23.2 is a ...
- python3 爬虫五大模块之三:网页下载器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
- Tensorflow保存神经网络参数有妙招:Saver和Restore
摘要:这篇文章将讲解TensorFlow如何保存变量和神经网络参数,通过Saver保存神经网络,再通过Restore调用训练好的神经网络. 本文分享自华为云社区<[Python人工智能] 十一. ...
- Python - poetry(2)命令介绍
poetry 语法格式 poetry [-h] [-q] [-v [<...>]] [-V] [--ansi] [--no-ansi] [-n] <command> [< ...
- tomcat服务字符编码改为UTF-8
-Dfile.encoding=UTF-8 --仅供参考
- 使用Java api对HBase 2.4.5进行增删改查
1.运行hbase 2.新建maven项目 2.将hbase-site.xml放在项目的resources文件夹下 3.修改pom.xml文件,引入hbase相关资源 <repositories ...