Python爬虫学习——1.爬虫入门
HTTP和HTTPS
HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
HTTP的端口号为80,HTTPS的端口号为443
HTTP请求方式
- get请求:从服务器上获取指定页面信息
特点:比较便捷
缺点:不安全,参数的长度有限制
- post请求:向服务器提交数据并获取页面信息
特点:比较安全,数据整体没有限制,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等)
当发送网络请求时(需要带一定的数据给服务器,不带数据也可以),会看到请求头:request header和客户端返回数据的相应:response
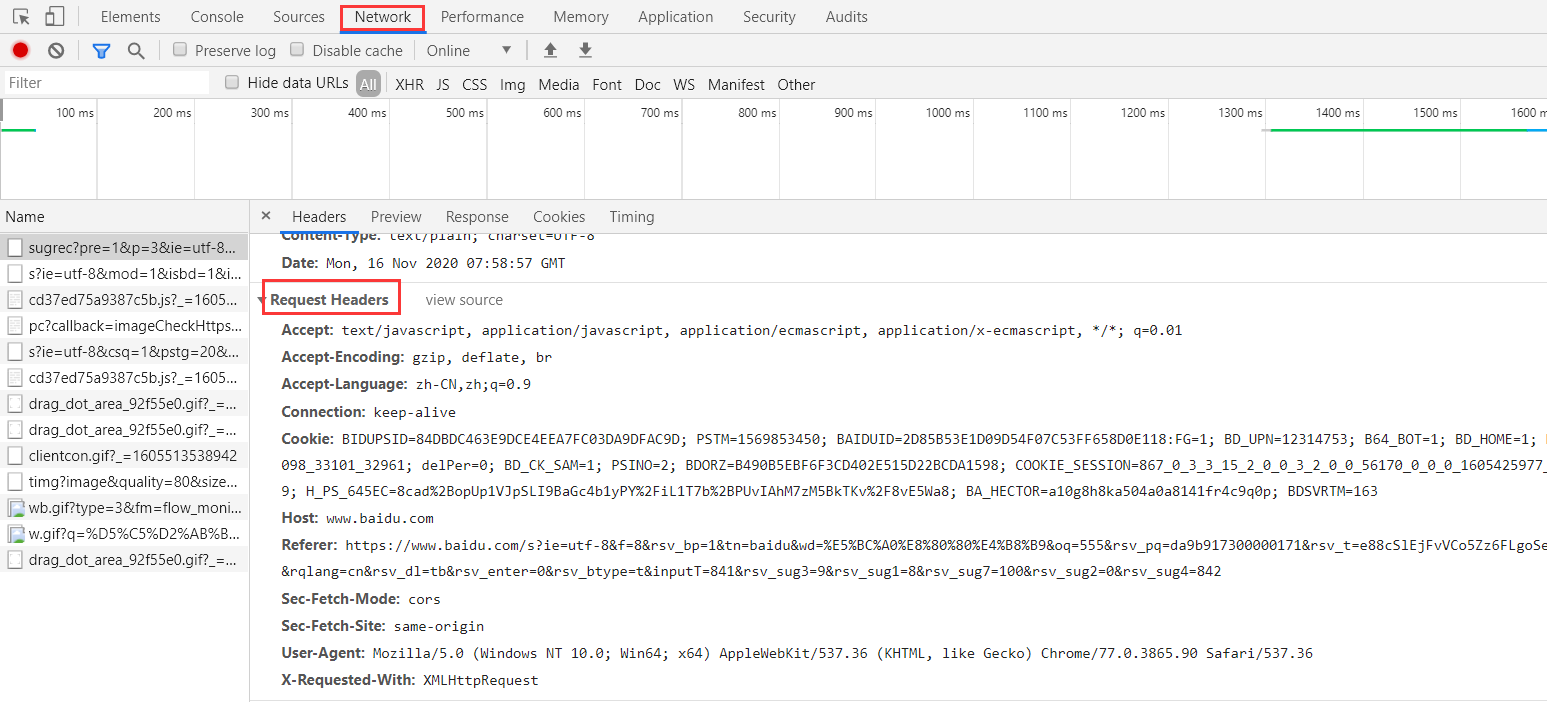
request headers包含信息:
- Accept:文本的格式
- Accept-Encoding:编码格式
- Connection:长链接/短链接
- Cookie:验证用的信息
- Host:域名
- Referer:标志从那个页面跳转过来的
- User-Agent:浏览器和用户的信息
爬虫入门
1. 什么是爬虫?
使用代码模拟用户,批量的发送网络请求,批量的获取数据。
2. 爬虫的价值?
买卖数据(高端的领域价格昂贵!!);数据分析;流量;......
3. 爬虫的合法性?
灰色产业(没有法律明确规定是否违法)。
4. 爬虫可以爬取所有东西吗?
不可以。爬虫只能怕去到用户所能访问到的信息。如腾讯视频vip用户可以爬取vip视频,普通用户只可爬取非vip的视频。
5. 爬虫的分类?
- 通用爬虫:使用搜索引擎
- 优势:开放性,速度快
- 劣势:目标不明确,返回内容大多用户不需要,不清楚用户的需求
- 聚焦爬虫!!!
- 优势:目标明确,能够精准捕捉用户需求,返回的内容固定
6. 爬虫的工作原理 ?
(1)确认你抓取目标的url是哪一个
(2)使用Python代码发送网络请求来获取数据
(3)解析获取到的数据(精确数据)
(4)数据持久化(将数据存储在本地)
学习课程:B站《廖雪峰爬虫》
Python爬虫学习——1.爬虫入门的更多相关文章
- Python 3 Anaconda 下爬虫学习与爬虫实践 (1)
环境python 3 anaconda pip 以及各种库 1.requests库的使用 主要是如何获得一个网页信息 重点是 r=requests.get("https://www.goog ...
- python库学习笔记——爬虫常用的BeautifulSoup的介绍
1. 开启Beautiful Soup 之旅 在这里先分享官方文档链接,不过内容是有些多,也不够条理,在此本文章做一下整理方便大家参考. 官方文档 2. 创建 Beautiful Soup 对象 首先 ...
- Python爬虫学习二------爬虫基本原理
爬虫是什么?爬虫其实就是获取网页的内容经过解析来获得有用数据并将数据存储到数据库中的程序. 基本步骤: 1.获取网页的内容,通过构造请求给服务器端,让服务器端认为是真正的浏览器在请求,于是返回响应.p ...
- Python 3 Anaconda 下爬虫学习与爬虫实践 (2)
下面研究如何让<html>内容更加“友好”的显示 之前略微接触的prettify能为显示增加换行符,提高可阅读性,用法如下: import requests from bs4 import ...
- Scrapy爬虫学习笔记 - 爬虫基础知识
一.正则表达式 二.深度和广度优先 三.爬虫去重策略
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- Python实战:Python爬虫学习教程,获取电影排行榜
Python应用现在如火如荼,应用范围很广.因其效率高开发迅速的优势,快速进入编程语言排行榜前几名.本系列文章致力于可以全面系统的介绍Python语言开发知识和相关知识总结.希望大家能够快速入门并学习 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
随机推荐
- .net core AES加密解密及RSA 签名验签
引用 using Org.BouncyCastle.Crypto.Parameters; using Org.BouncyCastle.Security; using System; using Sy ...
- 06 jumpserver登录操作
1.4.使用创建的 liuchang 用户登录jump server: 0.安全-MFA登陆验证说明: (1)简单的用户名密码就能登陆,太危险了,加一个MFA随机验证码这种黑科技限制一下. (2)Mu ...
- 关于VIM的迁移
将Gvim7.3从我笔记本拷到公司的电脑上面时, 这问题留了好久没有去解决.语法高亮无效不管我怎么设置 syntax enable,还是遇到这个问题. 后来在偶然的情况下,将我笔记本上面的文件在拷一份 ...
- 如何消除inline-block元素之间的间隙?
一.问题现象 在CSS布局中,如果我们想要将多个行内块元素并排,会发现同行显示的inline-block元素之间会出现一定的空隙,这就是换行符/空格导致的,叫做换行符/空格间隙. 1 <!DOC ...
- java:替换List集合中的某个任意值(对象)
定义replaceAll方法,将传入的新值替换集合中的老值(list,old,new) private static <E> void replaceAll(List<E> l ...
- 其他:压力测试Jmeter工具使用
下载路径: http://yd01.siweidaoxiang.com:8070/jmeter_52z.com.zip 配置汉化中文: 找到jmeter的安装目录:打开 \bin\jmeter.pro ...
- IDEA部署了项目,其他页面可以正常访问,但访问tomcat的localhost:8080却出现404
解决方案 点击Edit Configurations 点击右边的加号, 把目录放在你tomcat目录下的ROOT目录.之后就可以正常运行了
- Linux中grep和egrep命令详解
rep / egrep 语法: grep [-cinvABC] 'word' filename -c :打印符合要求的行数-i :忽略大小写-n :在输出符合要求的行的同时连同行号一起输出-v ...
- NAT444技术简介
嘛,最近老师布置了一道题目与NAT444技术相关,遂收集一波相关资料. 首先来一波名词解释: ICP:网络内容服务商(Internet Content Provider) BRAS:宽带远程接入服务( ...
- luogu P2710 数列
(这是个双倍经验呀! 题目描述 维护一个可以支持插入.删除.翻转.区间赋值.求和.求值和求最大子段和操作的序列.(真·简洁) solution 基本不用什么神奇操作,平衡树硬上就行.(我用的 Spla ...