Python 3 Anaconda 下爬虫学习与爬虫实践 (2)
下面研究如何让<html>内容更加“友好”的显示
之前略微接触的prettify能为显示增加换行符,提高可阅读性,用法如下:
import requests
from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
print(soup.prettify())
同样,它也可以为其中的个别标签做专门的处理,比如对a标签进行处理
代码如下:
import requests
from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
print(soup.a.prettify())
其输出结果如下:
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">
新闻
</a>
可以发现a标签被清晰的打印了出来
关于bs4库的总结

下面进行信息标记的学习
信息标记的三种形式:
XML,YAML,JSON(JavaScript Object Notation)
XML是使用尖括号(最早通用标记语言,较为繁琐)
JSON(常用于接口处理,但其无法注释)
是有类型的键值对 key:value
比如 "name":"北京邮电大学"
"name"是键(key) “北京邮电大学”是值(value)
当值有多个的时候使用[,]组织,例如
"name":["北京邮电大学","清华大学"]
键值对之间可以嵌套使用,比如:
"name" : {
"newName":"北京理工大学",
"oldName":"延安自然科学院"
}
YAML(用于各类系统的配置文件,有注释易读)
无类型键值对(用缩进表达所属关系)
下面学习信息提取的一般方法
实例:
提取HTML中所有URL链接
思路:
1.搜索到所有<a>标签
2.解析<a>标签格式,提取href后的链接内容
下面是代码部分:
from bs4 import BeautifulSoup
import requests r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
效果为:
http://news.baidu.com
https://www.hao123.com
http://map.baidu.com
http://v.baidu.com
http://tieba.baidu.com
等等
成功爬取到所有链接。
这其中非常重要的查找函数为:
<>.find_all(name,attrs,recursive,string,**kwargs)
返回一个列表类型,存储查找的结果
name:对标签名称的检索字符串
attrs:对标签属性值的检索字符串,可标注属性检索
recursice:是否对子孙全部检索,默认True。
string: <>...</>中字符串区域的检索字符串
比如
print(soup.find_all(string=re.compile('Li')))
这里如果是soup.find_all('a')就可以找到所有a标签
soup.find_all(['a','b'])就可以找到所有的a标签和b标签
下面想找到b开头的所有式子,这时需要使用正则表达式,也就是re库,后面会详细学习,先用一下,代码如下:
from bs4 import BeautifulSoup
import requests
import re r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
for tag in soup.find_all(re.compile('b')):
print(tag.name)
下面是查找
soup.find_all('p','course')查找p标签下类名为course的
suop.find_all(id='link1')查找id为link1的
由于find_all非常常见,所以
<tag>(...)等价于<tag>.find_all(...)
soup(...)等价于soup.find_all(...)
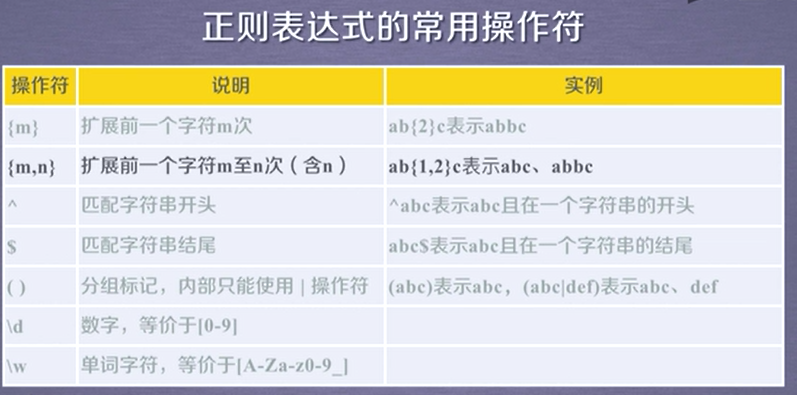
正则表达式:
regular expression RE
比如 'PY'开头,后续存在不多于10个字符,后续字符不能是'P'或者'Y'
正则表达式:PY[^PY]{0,10}
. 表示单个字符
[] 字符集,[abc]表示a,b,c


Python 3 Anaconda 下爬虫学习与爬虫实践 (2)的更多相关文章
- Python 3 Anaconda 下爬虫学习与爬虫实践 (1)
环境python 3 anaconda pip 以及各种库 1.requests库的使用 主要是如何获得一个网页信息 重点是 r=requests.get("https://www.goog ...
- Python爬虫学习——1.爬虫入门
HTTP和HTTPS HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法. HTTPS(Hypertext Transfer ...
- Python爬虫学习二------爬虫基本原理
爬虫是什么?爬虫其实就是获取网页的内容经过解析来获得有用数据并将数据存储到数据库中的程序. 基本步骤: 1.获取网页的内容,通过构造请求给服务器端,让服务器端认为是真正的浏览器在请求,于是返回响应.p ...
- Scrapy爬虫学习笔记 - 爬虫基础知识
一.正则表达式 二.深度和广度优先 三.爬虫去重策略
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- python 学习之爬虫练习
通过学习python,写两个简单的爬虫,没用线程,本地抓取速度还不错,有些瑕疵就是抓的图片有些显示不出来,代码做个笔记记录下: # -*- coding:utf-8 -*- import re imp ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
随机推荐
- 微信小程序-列表渲染多层嵌套循环
微信小程序-列表渲染多层嵌套循环 入门教程之列表渲染多层嵌套循环,目前官方的文档里,主要是一维数组列表渲染的案例,还是比较简单单一,给刚入门的童鞋还是无从入手的感觉. <view wx:for= ...
- RTK与差分测量的区别
差分GPS定位原理 它使用一台 GPS基准接收机(基准站)和一台用户接收机(移动站),利用实时或事后处理技术,就可以使用户测量时消去公共的误差源 —卫星轨道误差.卫星钟差.大气延时.多路径效应.特别提 ...
- 跟我一步一步写出MongoDB Web 可视化工具(二)
前言 上篇讲了一些基础,主要注重的是查,包括建立数据库链接.获取数据库.获取表.列出数据库.列出表.列出索引.获取数据等. 本篇依然是基础,注重增改删,废话不多说,咱们开始. 进阶 创建一个数据库和一 ...
- ASP.NET MVC Display Mode 移动端视图 配置对微信内置浏览器的识别
最近在捣鼓一个稍微有点low的商城网站,没有计划做app却要求有个wap版,而前端又没有做成响应式,时间WTF,直接利用了asp.net mvc的Display Mode Provider. 使用方式 ...
- 图书馆管理系统(C语言)
/* 实现的功能 * @ 1. 录入图书的信息 * @ 2. 给定图书的编号,显示该图书的详细信息 * @ 3. 给定作者的姓名,可以显示该作者所有的书 * @ 4. 给定出版社,可以显示该出版社出版 ...
- PCA算法数学原理及实现
数学原理参考:https://blog.csdn.net/aiaiai010101/article/details/72744713 实现过程参考:https://www.cnblogs.com/ec ...
- Gulp 之图片压缩合并
同事需要处理很多的图片,由于UI那边提供图片比较大,为了性能好一点,程序包小一点,因此希望我帮忙做成小程序来完成此工作. 其实之前做过一个grunt写的图片压缩合并工具,当时是为了处理270多个国家/ ...
- 解决Eclipse中.properties文件中文乱码问题
在.properties文件写注释时,发现中文乱码了,由于之前在idea中有见设置.properties文件的编码类型,便找了找乱码原因 在中文操作系统中,Eclipse中的Java类型文件的编码的默 ...
- 共识机制:AngelToken技术的根基
共识机制是区块链技术的一个核心问题,它决定了区块链中区块的生成法则,保证了各节点的诚实性.账本的容错性和系统的稳健性. 常用的共识机制主要有 PoW.PoS.DPoS.Paxos.PBFT等. 基于区 ...
- SQL通配符
通配符可用于替代字符串中的任何其他字符. 在 SQL 中,通配符与 SQL LIKE 操作符一起使用. SQL 通配符用于搜索表中的数据. 在 SQL 中,可使用以下通配符: 通配符 描述 % 替代 ...