BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
概
数据的长短尾效应是当前比较棘手的问题, 本文提出用分支网络来应对这一问题, 并取得了不错的结果.
主要内容
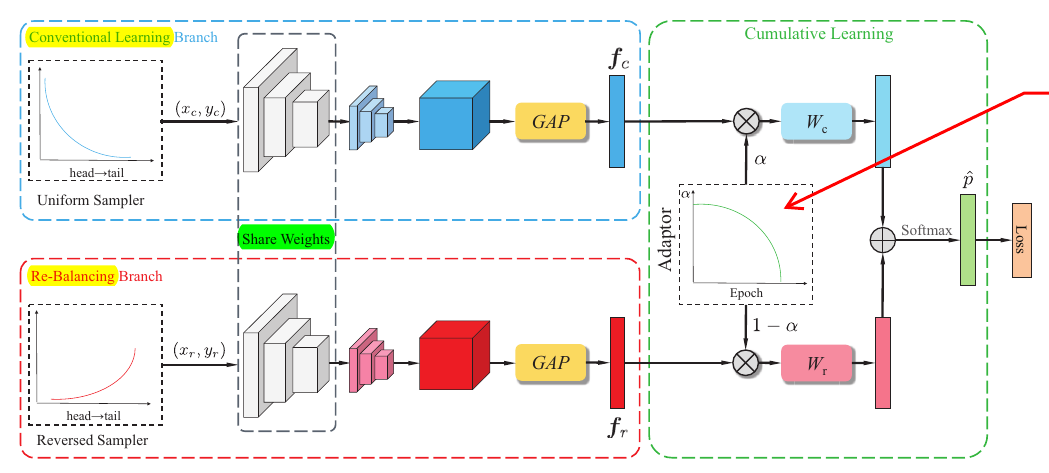
这篇文章的创新点是用两个分支来适应数据的不平衡.
如图所示, 上面的分支用于标准的训练, 而下面的分支则采用适合不平衡数据的训练方式: 即一般的训练是均匀的采样分布, 而非标准训练采用的是一个非均匀的依赖于样本分布的.
通过均匀采样得到\((x_c, y_c)\), 通过非均匀采样得到\((x_r, y_r)\), 分别喂入上下分支得到特征表示\(f_c\)和\(f_r\).
注意到, 上下两个分支是共享部分参数的, 作者实际选择的是残差网络, 设定为除了最后一个residual block外均是共享的.
根据\(f_c\)和\(f_r\)进一步得到
\]
即\([z_1, z_2,\cdots, z_C]^T\).
得到相应的概率向量
\]
最后通过下列损失函数进行训练
\]
实际上, \(\alpha\)就是一个调整标准训练和处理不平衡数据的权重.
采样方式
对于非均匀分布, 作者采取了如下方式构造采样分布, 假设每个类的样本数目为\(N_i, i=1,2,\ldots,C\). 则采样比例为
\]
其中\(w_i=\frac{1}{N_i}\).
权重\(\alpha\)
作者采用的是这样的一种方案
\]
其中\(T\)为当前的epoch, \(T_{max}\)为总的训练epochs.
在实际测试中, 作者也尝试了一些别的方案, 不过别的方案不如此方案理想.
直观上的解释就是, 训练过程会有普通的训练渐渐偏向re-balance的训练.
Inference phase
在推断过程中, 设定\(\alpha=0.5\).
代码
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition的更多相关文章
- 《Neural Network and Deep Learning》_chapter4
<Neural Network and Deep Learning>_chapter4: A visual proof that neural nets can compute any f ...
- neural network and deep learning笔记(1)
neural network and deep learning 这本书看了陆陆续续看了好几遍了,但每次都会有不一样的收获. DL领域的paper日新月异.每天都会有非常多新的idea出来,我想.深入 ...
- 树卷积神经网络Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
树卷积神经网络Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning 2018-04-17 08:32:39 看_这是一 ...
- 论文笔记:Learning Attribute-Specific Representations for Visual Tracking
Learning Attribute-Specific Representations for Visual Tracking AAAI-2019 Paper:http://faculty.ucmer ...
- [论文阅读] A Discriminative Feature Learning Approach for Deep Face Recognition (Center Loss)
原文: A Discriminative Feature Learning Approach for Deep Face Recognition 用于人脸识别的center loss. 1)同时学习每 ...
- Neural Network Programming - Deep Learning with PyTorch with deeplizard.
PyTorch Prerequisites - Syllabus for Neural Network Programming Series PyTorch先决条件 - 神经网络编程系列教学大纲 每个 ...
- Learning to Compare: Relation Network for Few-Shot Learning 论文笔记
主要原理: 和Siamese Neural Networks一样,将分类问题转换成两个输入的相似性问题. 和Siamese Neural Networks不同的是: Relation Network中 ...
- 【转载】论文笔记系列-Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
一. 引出主题¶ 深度学习领域一直存在一个比较严重的问题——“灾难性遗忘”,即一旦使用新的数据集去训练已有的模型,该模型将会失去对原数据集识别的能力.为解决这一问题,本文提出了树卷积神经网络,通过先将 ...
- Neural Network Programming - Deep Learning with PyTorch - YouTube
百度云链接: 链接:https://pan.baidu.com/s/1xU-CxXGCvV6o5Sksryj3fA 提取码:gawn
随机推荐
- 12. Fedora 中文乱码问题
1. Rhythmbox(音乐播放器乱码) yum install python-mutagen mid3iconv -e GBK *.mp3 2. totem电影播放机播放列表乱码解决1).修改to ...
- oracle 存储过程及REF CURSOR的使用
基本使用方法及示例 1.基本结构: CREATE OR REPLACE PROCEDURE 存储过程名字 (参数1 IN NUMBER,参数2 IN NUMBER) AS 变量1 INTEGER := ...
- Linux:sqlldr命令
第一步:写一个 ctl格式的控制文件 CTL 控制文件的内容 : load data --1. 控制文件标识 infile 'xxx.txt' --2. 要导入的数据文件名 insert into t ...
- nodejs代码初探之nodejs启动
nodejs启动 入口在node_main.cc,解析参数后进入node.cc 中的node::Start() V8::Initialize() //初始化v8SetupProcessObject() ...
- lambda表达式快速创建
Java 8十个lambda表达式案例 1. 实现Runnable线程案例 使用() -> {} 替代匿名类: //Before Java 8: new Thread(new Runnable( ...
- freeswitch APR库线程读写锁
概述 freeswitch的核心源代码是基于apr库开发的,在不同的系统上有很好的移植性. 线程读写锁在多线程服务中有重要的作用.对于读数据比写数据频繁的服务,用读写锁代替互斥锁可以提高效率. 由于A ...
- C++11 关键字 const 到底怎么用?
Const 的作用及历史 const (computer programming) - Wikipedia 一.历史 按理来说,要想了解一件事物提出的原因,最好的办法就是去寻找当时的历史背景,以及围绕 ...
- <转>git,github在windows上的搭建
http://www.cnblogs.com/yixiaoyang/archive/2012/01/06/2314190.html Git在源码管理领域目前占很大的比重了,而且开源的项目很多都转到Gi ...
- IO多路复用技术总结
来源:微信公众号「编程学习基地」 IO 多路复用概述 I/O 多路复用技术是为了解决进程或线程阻塞到某个 I/O 系统调用而出现的技术,使进程不阻塞于某个特定的 I/O 系统调用. 在IO多路复用技术 ...
- 【论文笔记】Recommendations as Treatments: Debiasing Learning and Evaluation
Recommendations as Treatments: Debiasing Learning and Evaluation Authors: Tobias Schnabel, Adith Swa ...