A Deep Neural Network’s Loss Surface Contains Every Low-dimensional Pattern
A Deep Neural Network’s Loss Surface Contains Every Low-dimensional Pattern
概
作者关于Loss Surface的情况做了一个理论分析, 即证明足够大的神经网络能够逼近所有的低维损失patterns.
相关工作
文中多处用到了universal approximators.
主要内容
引理1

\(\mathcal{F}\)定义了universal approximators, 即同一定义域内的任意函数\(f\)都能用\(\mathcal{F}\)中的元素来逼近. \(\sigma(f_\theta)\)则是将值域进行了扩展, 而这并不影响其universal approximator的性质.
定理1

证明:
假设神经网络的第一层的权重矩阵为\(\theta_W \in \mathbb{R}^{d \times k}\), 偏置向量为\(\theta_b\), 神经网络剩余的参数为\(\theta'\), 记\(\theta = \{\theta_W, \theta_b, \theta'\}\). 则网络的输出为:
f_{\theta}(x) = f_{\{\theta_W, \theta_b, \theta' \}}(x) = g_{\theta'}(\langle x, \theta_W \rangle + \theta_b),
\]
\(N\)个样本点的损失就是
L(\theta) = \frac{1}{N} \sum_i \ell (f_{\theta}(x_i), y_i).
\]
现在假设目标\(z\)维loss pattern为(应当为连续函数)
\mathcal{T}(h_1,h_2,\ldots, h_z):[0,1]^z \rightarrow [0, 1].
\]
我们现在, 希望将网络中的某些参数视作变量\(h_1,\ldots,h_z\), 得以逼近\(\mathcal{T}\).
令\(\theta_W=0\) (这样网络的输出与\(x\)无关), \(\theta_b=[h_1,\ldots, h_z,0,\ldots,0]\)(这隐含了\(k \ge z\)的假设).
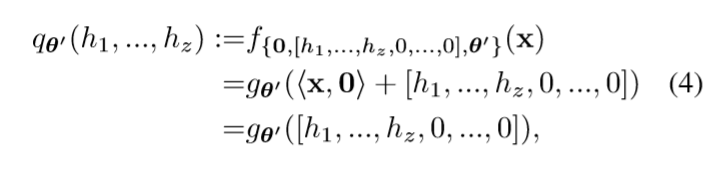
根据universal approximation theorem我们可以使得\(q_{\theta'}\)成为approximator. 相对应的
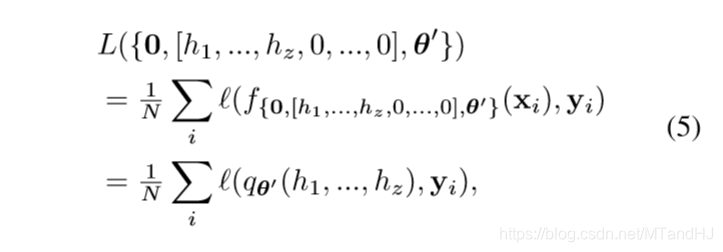
定义\(\sigma(p):=\frac{1}{N}\sum_i \ell(q_{\theta'}(h_1,\ldots, h_z),y_i)\), 只需要\(\sigma\)满足引理1中的条件, 就存在\(\theta_{\epsilon}(\mathcal{T})\), 使得\(L(h_1,h_2,\ldots, h_z, \theta_{\epsilon}(\mathcal{T}))\)逼近\(\mathcal{T}\).
定理2

说实话, 这个定理没怎么看懂, 看证明, 这个global minimum似乎指的是\(\mathcal{T}(h)\)的最小值.
证明:
\(\theta_b\)不变, \(\theta_W\)只令前\(z\)列为0, 则第一层(未经激活)的输出为\((h_1,\ldots,h_z,\phi(x))\), 于是
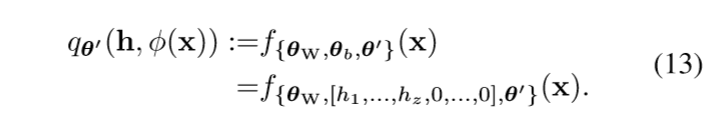
令\(h^* := \arg \min_{h \in [0,1]^z \mathcal{T}(h)}\), 并假设\(L^*=\mathcal{T}(h^*)\)(?). 假设损失\(\ell_i(p) = \ell (p, y_i)\), 可逆且逆函数光滑(这个性质对于损失函数来讲很普遍).
在这个假设下, 我们有
q_{\theta'}(h, \phi(x_i)) \approx \ell_i^{-1}(\mathcal{T}(h)),
\]
文中说这个也是因为逼近定理, 固定\(i\)的时候, 这个自然是成立的, 如何能保证对于所有的\(i=1,\ldots,n\)成立, 我有一个思路.
假设二者的距离(\(+\infty\)范数)为\(\epsilon_i^h \in \mathbb{R}\), 则
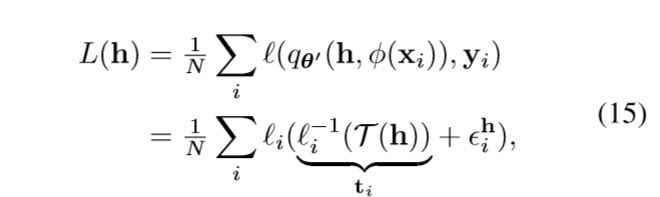
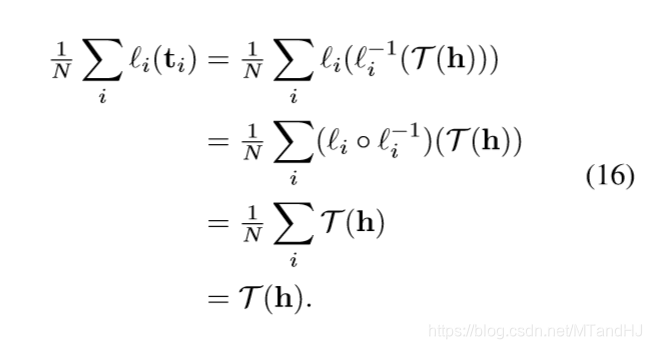
所以
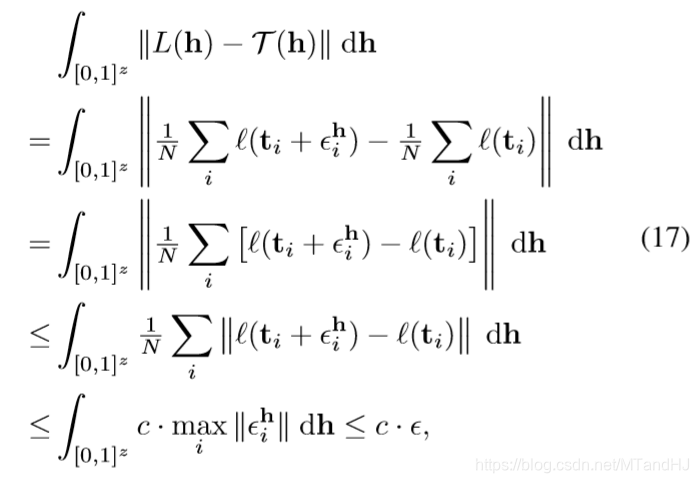
且此时\(|L(h^*)-\mathcal{T}(h^*)|<\epsilon\).
我比较关心的问题是, 能否选择合适的loss patterns (相当于选择合适的空间) 使得网络在某些性能上比较好(比方防过拟合, 最优性).
A Deep Neural Network’s Loss Surface Contains Every Low-dimensional Pattern的更多相关文章
- 深度神经网络如何看待你,论自拍What a Deep Neural Network thinks about your #selfie
Convolutional Neural Networks are great: they recognize things, places and people in your personal p ...
- XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network
XiangBai--[AAAI2017]TextBoxes:A Fast Text Detector with a Single Deep Neural Network 目录 作者和相关链接 方法概括 ...
- 论文阅读(XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network)
XiangBai——[AAAI2017]TextBoxes:A Fast Text Detector with a Single Deep Neural Network 目录 作者和相关链接 方法概括 ...
- Neural Networks and Deep Learning(week4)Deep Neural Network - Application(图像分类)
Deep Neural Network for Image Classification: Application 预先实现的代码,保存在本地 dnn_app_utils_v3.py import n ...
- Neural Networks and Deep Learning(week4)Building your Deep Neural Network: Step by Step
Building your Deep Neural Network: Step by Step 你将使用下面函数来构建一个深层神经网络来实现图像分类. 使用像relu这的非线性单元来改进你的模型 构建 ...
- 课程一(Neural Networks and Deep Learning),第四周(Deep Neural Networks)——2.Programming Assignments: Building your Deep Neural Network: Step by Step
Building your Deep Neural Network: Step by Step Welcome to your third programming exercise of the de ...
- What are the advantages of ReLU over sigmoid function in deep neural network?
The state of the art of non-linearity is to use ReLU instead of sigmoid function in deep neural netw ...
- 论文笔记之:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation xx
- Deep Learning: Assuming a deep neural network is properly regulated, can adding more layers actually make the performance degrade?
Deep Learning: Assuming a deep neural network is properly regulated, can adding more layers actually ...
随机推荐
- CRLF漏洞浅析
部分情况下,由于与客户端存在交互,会形成下面的情况 也就是重定向且Location字段可控 如果这个时候,可以向Location字段传点qqgg的东西 形成固定会话 但服务端应该不会存储,因为后端貌似 ...
- CSS基础语法(一)
目录 CSS基础语法(一) 一.CSS简介 1.CSS语法规范 2.CSS代码风格 二.CSS基础选择器 1.标签选择器 2.类选择器 3.id选择器 4.通配符选择器 5.总结 三.CSS字体属性 ...
- DP-Burst Balloons
leetcode312: https://leetcode.com/problems/burst-balloons/#/description Given n balloons, indexed fr ...
- Spring Batch : 在不同steps间传递数据
参考文档: How can we share data between the different steps of a Job in Spring Batch? Job Scoped Beans i ...
- Shell脚本定期清空大于1G的日志文件
一个关于如何在指定文件大于1GB后,自动删除的问题. 批处理代码如下: #!/bin/bash # 当/var/log/syslog大于1GB时 # 自动将其备份,并清空 # 注意这里awk的使用 i ...
- 【C/C++】散列/算法笔记4.2
先说一下我自己的理解. 我先给你N组数据,这个N组里可能有重复的! 然后我们先统计好了N组里面的独立的每个对应的出现了几次(相当于map,然后每项属性有出现了多少次的),用的是数组下标对应 现在我们给 ...
- Tableau如何绘制堆叠柱状图
一.将类别,子类别拖拽至列上 二.将度量值拖拽至行上 三.将度量名称拖拽至筛选器上,右键度量名称,编辑筛选器,选择销售额 四.将事先准备的目标销售额拖拽至度量值 五.将度量名称拖拽至标记,分别以颜色和 ...
- GDAL重投影重采样像元配准对齐
研究通常会涉及到多源数据,需要进行基于像元的运算,在此之前需要对数据进行地理配准.空间配准.重采样等操作.那么当不同来源,不同分辨率的数据重采样为同一空间分辨率之后,各个像元不一一对应,有偏移该怎么办 ...
- CF1428A Box is Pull 题解
Content 有一个兔子拖着一个盒子在走,每秒钟可以带着盒子走一个单位,也可以不带着盒子走一个单位.当且仅当兔子和盒子的距离不超过 \(1\) 时可以带着盒子走一个单位.现给出 \(t\) 次询问, ...
- dump Java 程序和服务器相关信息
#!/bin/bash jps -lm read -p "enter java pid: " pid port=$(netstat -ntlp | grep $pid | awk ...