A Deep Neural Network’s Loss Surface Contains Every Low-dimensional Pattern
A Deep Neural Network’s Loss Surface Contains Every Low-dimensional Pattern
概
作者关于Loss Surface的情况做了一个理论分析, 即证明足够大的神经网络能够逼近所有的低维损失patterns.
相关工作
文中多处用到了universal approximators.
主要内容
引理1

\(\mathcal{F}\)定义了universal approximators, 即同一定义域内的任意函数\(f\)都能用\(\mathcal{F}\)中的元素来逼近. \(\sigma(f_\theta)\)则是将值域进行了扩展, 而这并不影响其universal approximator的性质.
定理1

证明:
假设神经网络的第一层的权重矩阵为\(\theta_W \in \mathbb{R}^{d \times k}\), 偏置向量为\(\theta_b\), 神经网络剩余的参数为\(\theta'\), 记\(\theta = \{\theta_W, \theta_b, \theta'\}\). 则网络的输出为:
f_{\theta}(x) = f_{\{\theta_W, \theta_b, \theta' \}}(x) = g_{\theta'}(\langle x, \theta_W \rangle + \theta_b),
\]
\(N\)个样本点的损失就是
L(\theta) = \frac{1}{N} \sum_i \ell (f_{\theta}(x_i), y_i).
\]
现在假设目标\(z\)维loss pattern为(应当为连续函数)
\mathcal{T}(h_1,h_2,\ldots, h_z):[0,1]^z \rightarrow [0, 1].
\]
我们现在, 希望将网络中的某些参数视作变量\(h_1,\ldots,h_z\), 得以逼近\(\mathcal{T}\).
令\(\theta_W=0\) (这样网络的输出与\(x\)无关), \(\theta_b=[h_1,\ldots, h_z,0,\ldots,0]\)(这隐含了\(k \ge z\)的假设).
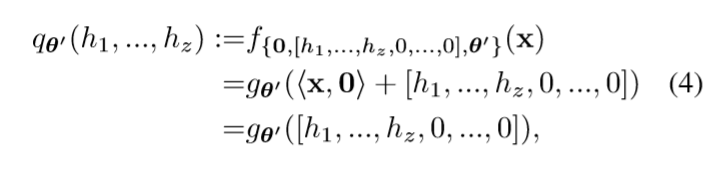
根据universal approximation theorem我们可以使得\(q_{\theta'}\)成为approximator. 相对应的
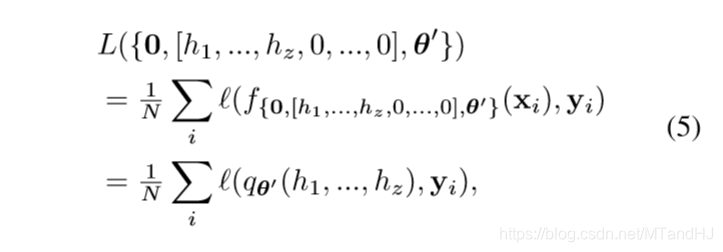
定义\(\sigma(p):=\frac{1}{N}\sum_i \ell(q_{\theta'}(h_1,\ldots, h_z),y_i)\), 只需要\(\sigma\)满足引理1中的条件, 就存在\(\theta_{\epsilon}(\mathcal{T})\), 使得\(L(h_1,h_2,\ldots, h_z, \theta_{\epsilon}(\mathcal{T}))\)逼近\(\mathcal{T}\).
定理2

说实话, 这个定理没怎么看懂, 看证明, 这个global minimum似乎指的是\(\mathcal{T}(h)\)的最小值.
证明:
\(\theta_b\)不变, \(\theta_W\)只令前\(z\)列为0, 则第一层(未经激活)的输出为\((h_1,\ldots,h_z,\phi(x))\), 于是
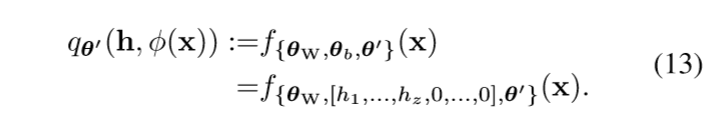
令\(h^* := \arg \min_{h \in [0,1]^z \mathcal{T}(h)}\), 并假设\(L^*=\mathcal{T}(h^*)\)(?). 假设损失\(\ell_i(p) = \ell (p, y_i)\), 可逆且逆函数光滑(这个性质对于损失函数来讲很普遍).
在这个假设下, 我们有
q_{\theta'}(h, \phi(x_i)) \approx \ell_i^{-1}(\mathcal{T}(h)),
\]
文中说这个也是因为逼近定理, 固定\(i\)的时候, 这个自然是成立的, 如何能保证对于所有的\(i=1,\ldots,n\)成立, 我有一个思路.
假设二者的距离(\(+\infty\)范数)为\(\epsilon_i^h \in \mathbb{R}\), 则
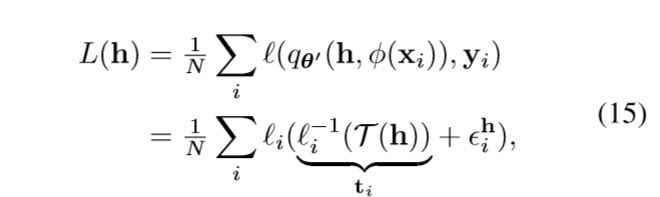
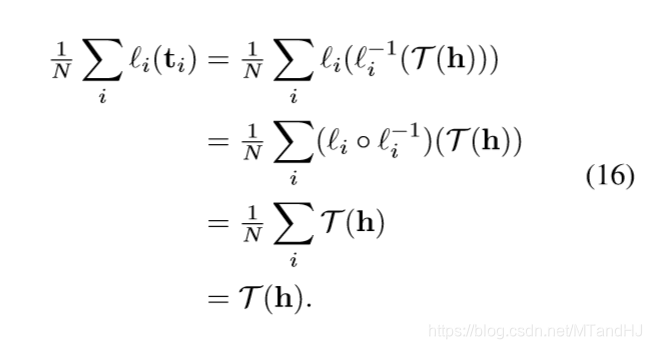
所以
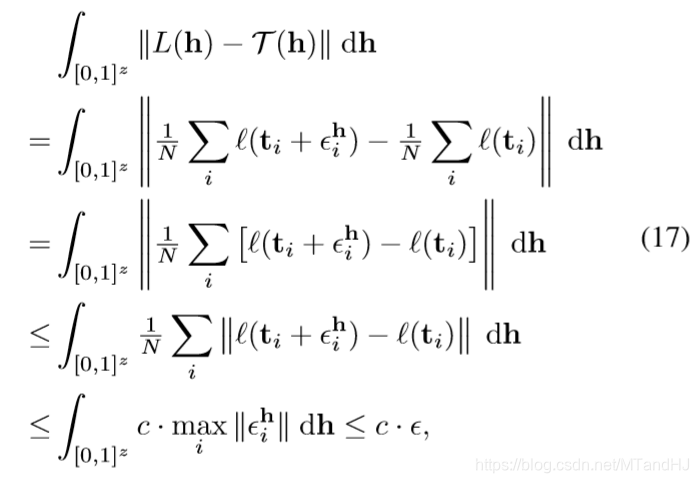
且此时\(|L(h^*)-\mathcal{T}(h^*)|<\epsilon\).
我比较关心的问题是, 能否选择合适的loss patterns (相当于选择合适的空间) 使得网络在某些性能上比较好(比方防过拟合, 最优性).
A Deep Neural Network’s Loss Surface Contains Every Low-dimensional Pattern的更多相关文章
- 深度神经网络如何看待你,论自拍What a Deep Neural Network thinks about your #selfie
Convolutional Neural Networks are great: they recognize things, places and people in your personal p ...
- XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network
XiangBai--[AAAI2017]TextBoxes:A Fast Text Detector with a Single Deep Neural Network 目录 作者和相关链接 方法概括 ...
- 论文阅读(XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network)
XiangBai——[AAAI2017]TextBoxes:A Fast Text Detector with a Single Deep Neural Network 目录 作者和相关链接 方法概括 ...
- Neural Networks and Deep Learning(week4)Deep Neural Network - Application(图像分类)
Deep Neural Network for Image Classification: Application 预先实现的代码,保存在本地 dnn_app_utils_v3.py import n ...
- Neural Networks and Deep Learning(week4)Building your Deep Neural Network: Step by Step
Building your Deep Neural Network: Step by Step 你将使用下面函数来构建一个深层神经网络来实现图像分类. 使用像relu这的非线性单元来改进你的模型 构建 ...
- 课程一(Neural Networks and Deep Learning),第四周(Deep Neural Networks)——2.Programming Assignments: Building your Deep Neural Network: Step by Step
Building your Deep Neural Network: Step by Step Welcome to your third programming exercise of the de ...
- What are the advantages of ReLU over sigmoid function in deep neural network?
The state of the art of non-linearity is to use ReLU instead of sigmoid function in deep neural netw ...
- 论文笔记之:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation xx
- Deep Learning: Assuming a deep neural network is properly regulated, can adding more layers actually make the performance degrade?
Deep Learning: Assuming a deep neural network is properly regulated, can adding more layers actually ...
随机推荐
- 云原生时代,为什么基础设施即代码(IaC)是开发者体验的核心?
作者 | 林俊(万念) 来源 |尔达 Erda 公众号 从一个小故事开始 你是一个高级开发工程师. 某天,你自信地写好了自动煮咖啡功能的代码,并在本地调试通过.代码合并入主干分支后,你准备把服务发布到 ...
- 大数据学习day17------第三阶段-----scala05------1.Akka RPC通信案例改造和部署在多台机器上 2. 柯里化方法 3. 隐式转换 4 scala的泛型
1.Akka RPC通信案例改造和部署在多台机器上 1.1 Akka RPC通信案例的改造(主要是把一些参数不写是) Master package com._51doit.akka.rpc impo ...
- 【leetcode】122.Best Time to Buy and Sell Stock II(股票问题)
You are given an integer array prices where prices[i] is the price of a given stock on the ith day. ...
- 【leetcode】1293 .Shortest Path in a Grid with Obstacles
You are given an m x n integer matrix grid where each cell is either 0 (empty) or 1 (obstacle). You ...
- Linux—禁止用户SSH登录方法总结
Linux-禁止用户SSH登录方法总结 一.禁止用户登录 1.修改用户配置文件/etc/shadow 将第二栏设置为"*",如下.那么该用户就无法登录.但是使用这种方式 ...
- fastjson过滤多余字段
/** * Description:过滤实体中的字段 * @param src 需要过滤的对象,如 list,entity * @param clazz 实体的class ...
- Java资源下载
tomcat http://mirror.bit.edu.cn/apache/tomcat/tomcat-8/v8.5.49/bin/apache-tomcat-8.5.49.tar.gz s ...
- Vue重要知识
Event Bus 总线 Vue中的EventBus是一种发布订阅模式的实践,适用于跨组件简单通信. Vuex也可以用来组件中进行通信,更适用于多组件高频率通信. 使用方式: 1.把Bus注入到Vue ...
- 13.Vue.js 组件
组件(Component)是 Vue.js 最强大的功能之一. 组件可以扩展 HTML 元素,封装可重用的代码. 组件系统让我们可以用独立可复用的小组件来构建大型应用,几乎任意类型的应用的界面都可以抽 ...
- logstash 正则表达式
正则表达式 3. 使用给定好的符号去表示某个含义 4. 例如.代表任意字符 5. 正则符号当普通符号使用需要加反斜杠 正则的发展 6. 普通正则表达式 7. 扩展正则表达式 普通正则表达式 . 任意一 ...