不会一致性hash算法,劝你简历别写搞过负载均衡
大家好,我是小富~
个人公众号:程序员内点事,欢迎学习交流
这两天看到技术群里,有小伙伴在讨论一致性hash算法的问题,正愁没啥写的题目就来了,那就简单介绍下它的原理。下边我们以分布式缓存中经典场景举例,面试中也是经常提及的一些话题,看看什么是一致性hash算法以及它有那些过人之处。
构建场景
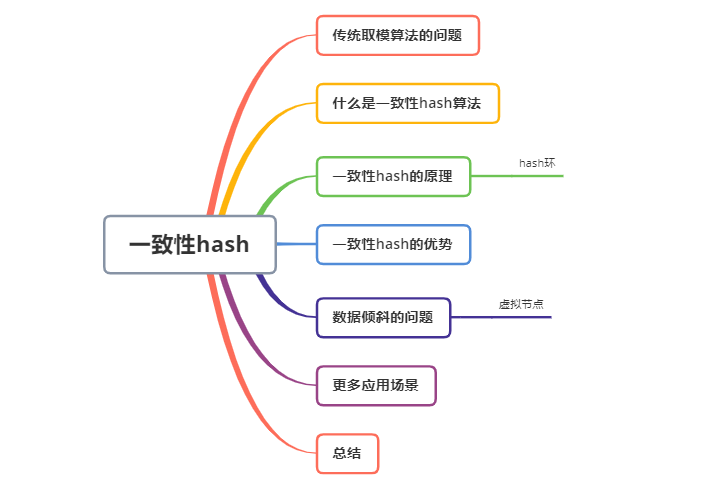
假如我们有三台缓存服务器编号node0、node1、node2,现在有3000万个key,希望可以将这些个key均匀的缓存到三台机器上,你会想到什么方案呢?
我们可能首先想到的方案,是取模算法hash(key)% N,对key进行hash运算后取模,N是机器的数量。key进行hash后的结果对3取模,得到的结果一定是0、1或者2,正好对应服务器node0、node1、node2,存取数据直接找对应的服务器即可,简单粗暴,完全可以解决上述的问题。
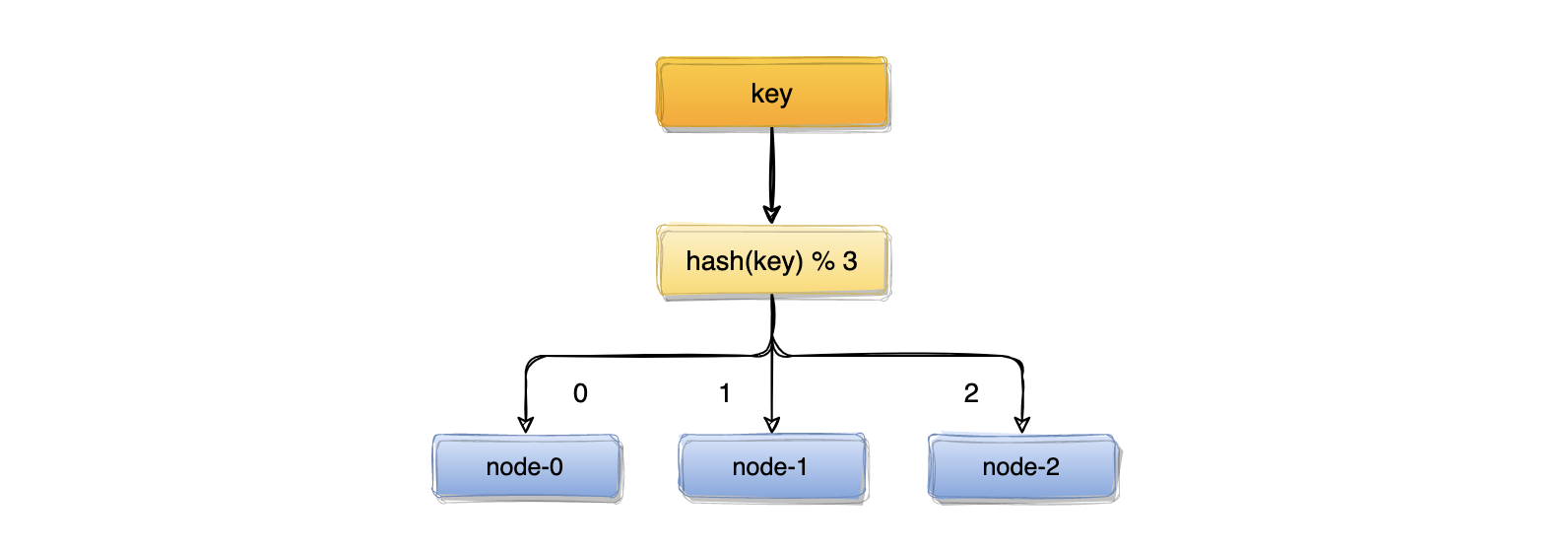
hash的问题
取模算法虽然使用简单,但对机器数量取模,在集群扩容和收缩时却有一定的局限性,因为在生产环境中根据业务量的大小,调整服务器数量是常有的事;而服务器数量N发生变化后hash(key)% N计算的结果也会随之变化。
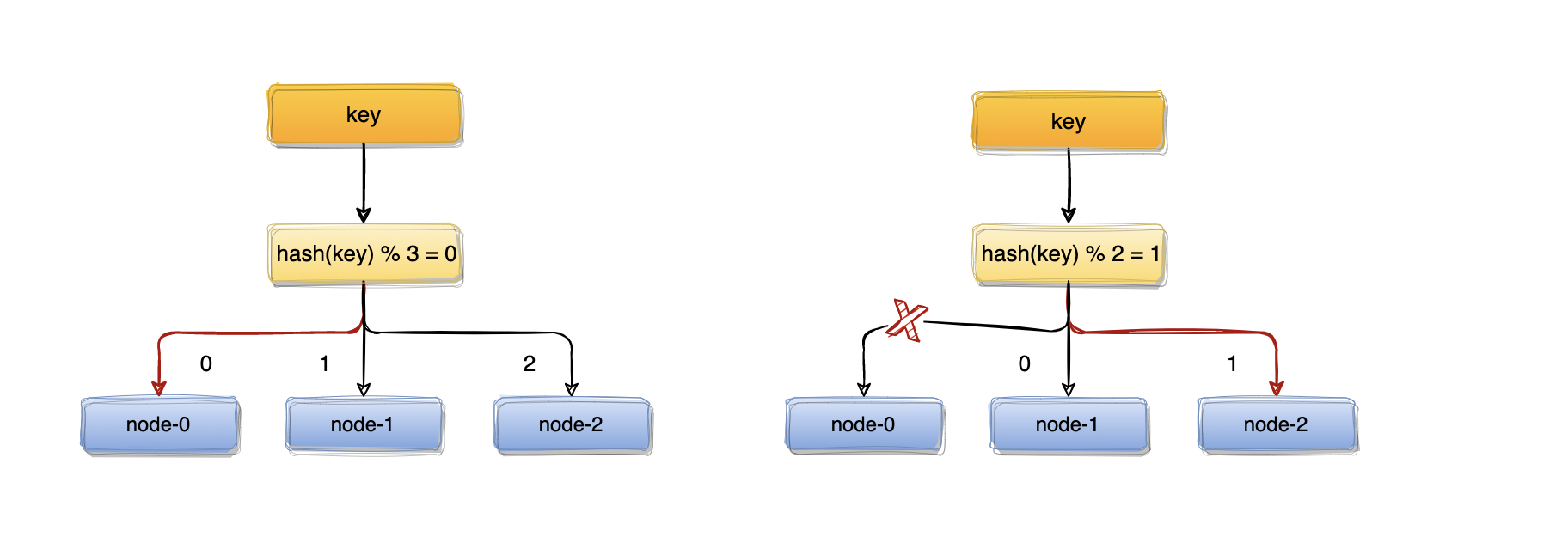
比如:一个服务器节点挂了,计算公式从hash(key)% 3变成了hash(key)% 2,结果会发生变化,此时想要访问一个key,这个key的缓存位置大概率会发生改变,那么之前缓存key的数据也会失去作用与意义。
大量缓存在同一时间失效,造成缓存的雪崩,进而导致整个缓存系统的不可用,这基本上是不能接受的,为了解决优化上述情况,一致性hash算法应运而生~
那么,一致性哈希算法又是如何解决上述问题的?
一致性hash
一致性hash算法本质上也是一种取模算法,不过,不同于上边按服务器数量取模,一致性hash是对固定值2^32取模。
IPv4的地址是4组8位2进制数组成,所以用2^32可以保证每个IP地址会有唯一的映射
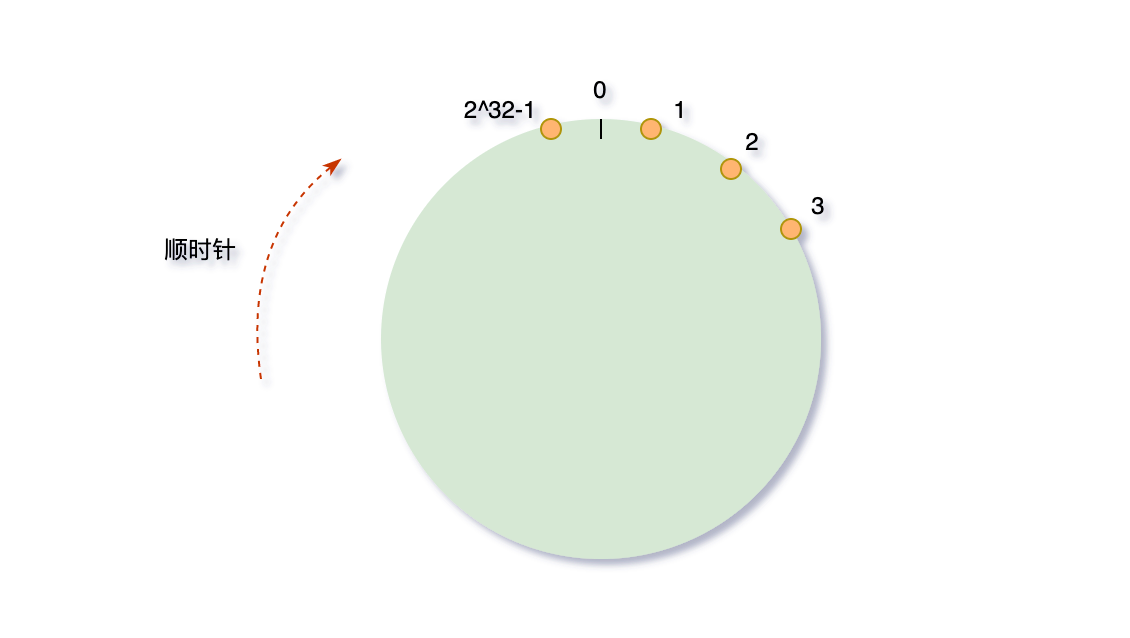
hash环
我们可以将这232个值抽象成一个圆环️(**不得意圆的,自己想个形状,好理解就行**),圆环的正上方的点代表0,顺时针排列,以此类推,1、2、3、4、5、6……直到232-1,而这个由2的32次方个点组成的圆环统称为hash环。
那么这个hash环和一致性hash算法又有什么关系嘞?我们还是以上边的场景为例,三台缓存服务器编号node0、node1、node2,3000万个key。
服务器映射到hash环
这个时候计算公式就从hash(key)% N 变成了**hash(服务器ip)% 232**,使用服务器IP地址进行hash计算,用哈希后的结果对232取模,结果一定是一个0到2^32-1之间的整数,而这个整数映射在hash环上的位置代表了一个服务器,依次将node0、node1、node2三个缓存服务器映射到hash环上。
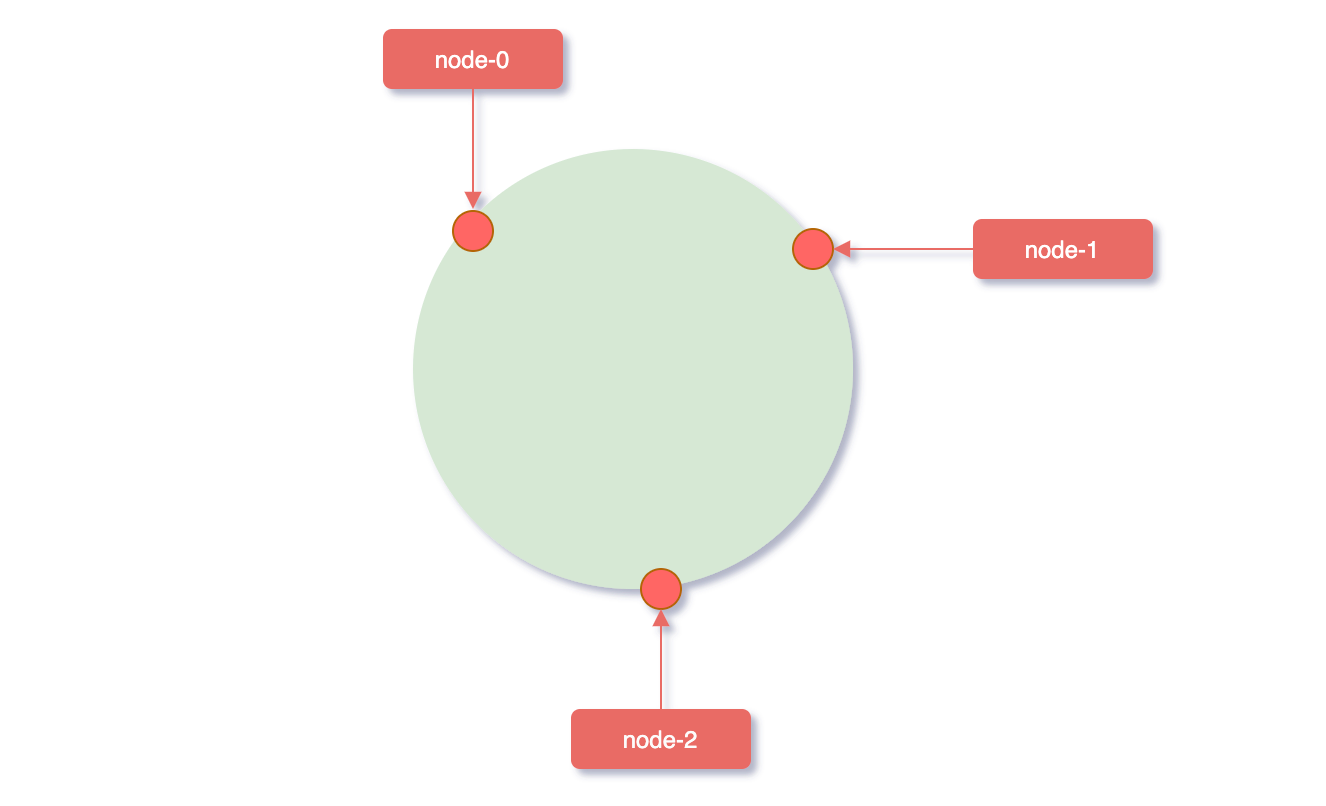
对象key映射到hash环
接着在将需要缓存的key对象也映射到hash环上,hash(key)% 2^32,服务器节点和要缓存的key对象都映射到了hash环,那对象key具体应该缓存到哪个服务器上呢?
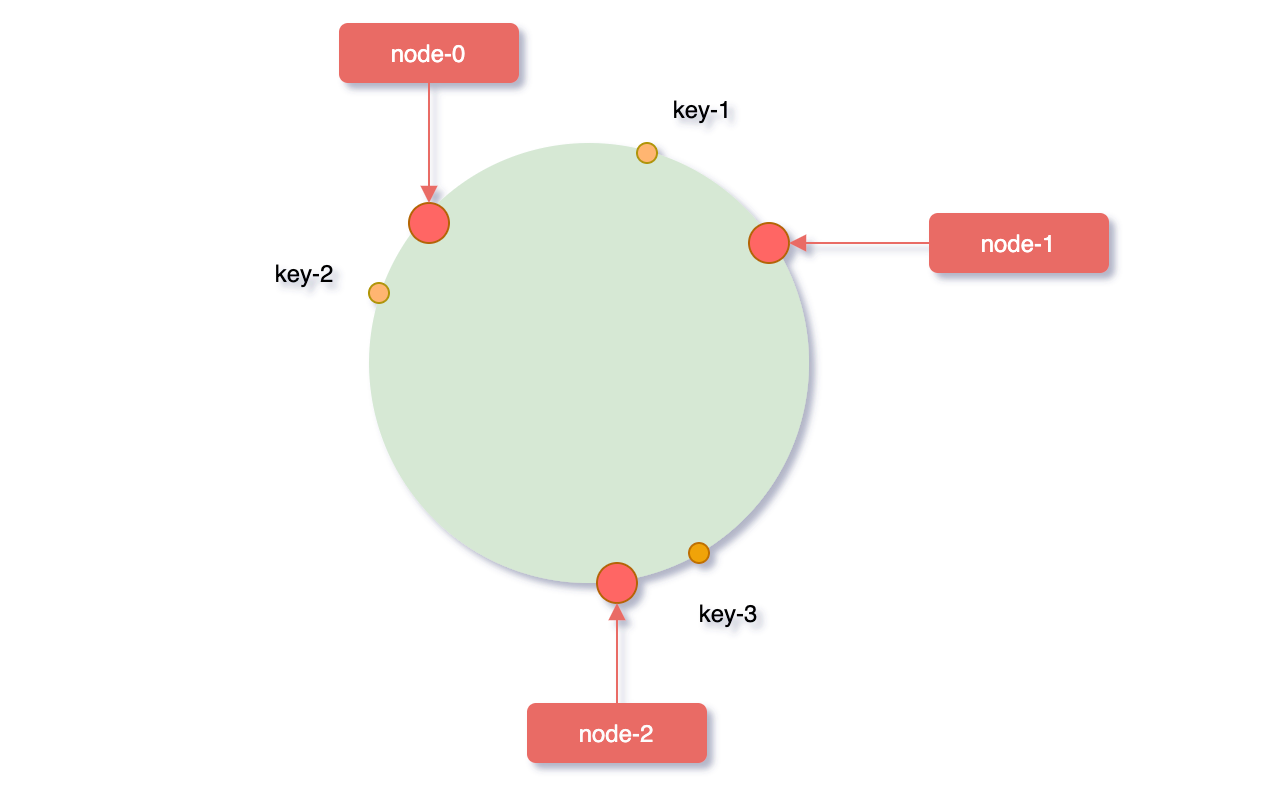
对象key映射到服务器
从缓存对象key的位置开始,沿顺时针方向遇到的第一个服务器,便是当前对象将要缓存到的服务器。
因为被缓存对象与服务器hash后的值是固定的,所以,在服务器不变的条件下,对象key必定会被缓存到固定的服务器上。根据上边的规则,下图中的映射关系:
key-1 -> node-1key-3 -> node-2key-4 -> node-2key-5 -> node-2key-2 -> node-0

如果想要访问某个key,只要使用相同的计算方式,即可得知这个key被缓存在哪个服务器上了。
一致性hash的优势
我们简单了解了一致性hash的原理,那它又是如何优化集群中添加节点和缩减节点,普通取模算法导致的缓存服务,大面积不可用的问题呢?
先来看看扩容的场景,假如业务量激增,系统需要进行扩容增加一台服务器node-4,刚好node-4被映射到node-1和node-2之间,沿顺时针方向对象映射节点,发现原本缓存在node-2上的对象key-4、key-5被重新映射到了node-4上,而整个扩容过程中受影响的只有node-4和node-1节点之间的一小部分数据。
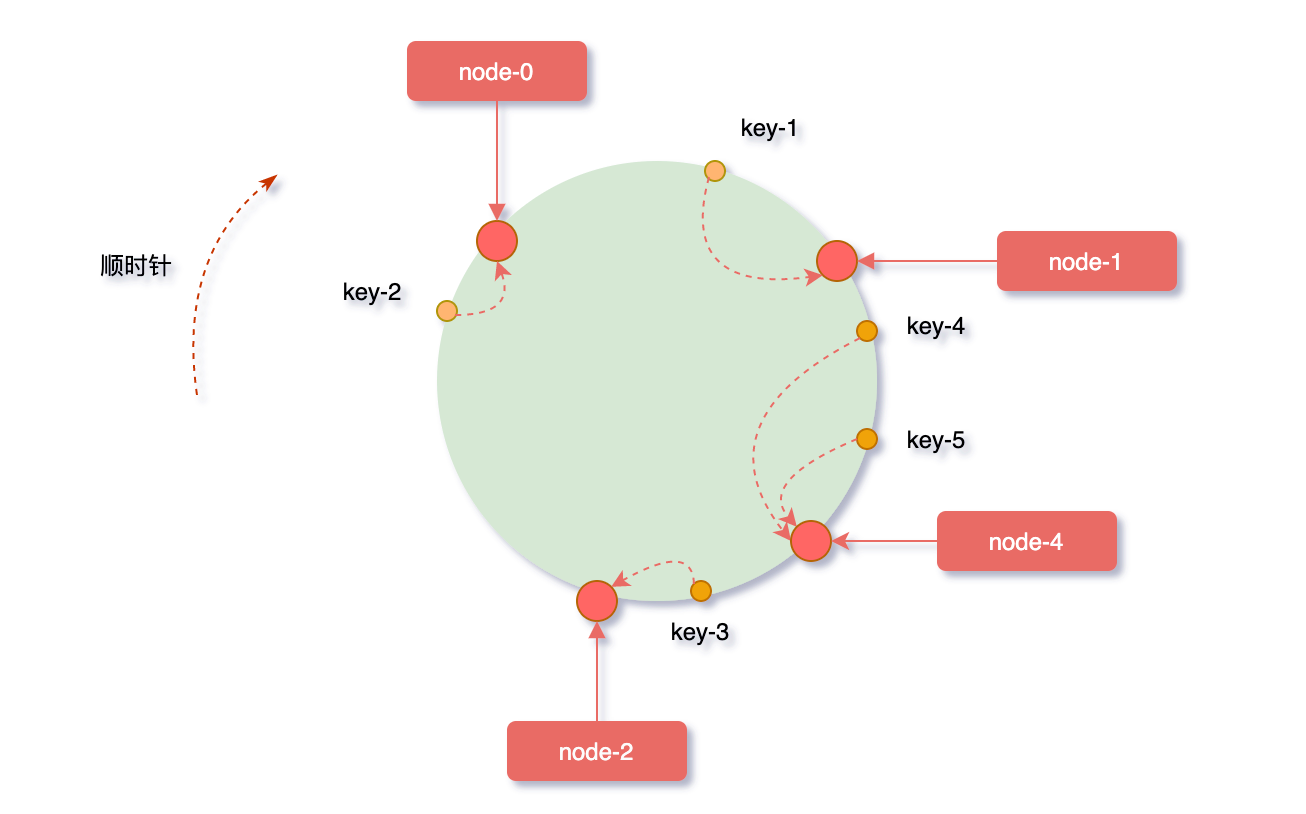
反之,假如node-1节点宕机,沿顺时针方向对象映射节点,缓存在node-1上的对象key-1被重新映射到了node-4上,此时受影响的数据只有node-0和node-1之间的一小部分数据。
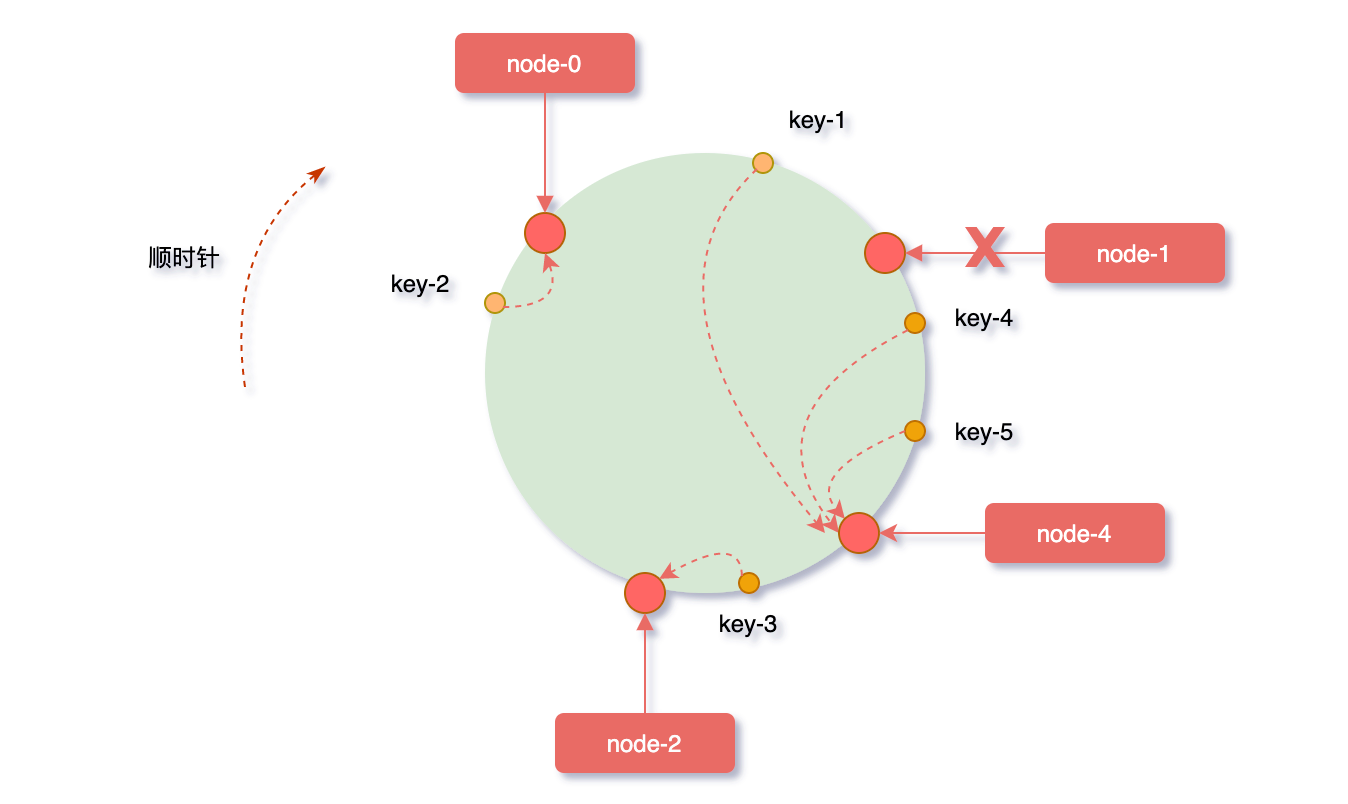
从上边的两种情况发现,当集群中服务器的数量发生改变时,一致性hash算只会影响少部分的数据,保证了缓存系统整体还可以对外提供服务的。
数据偏斜问题
前边为了便于理解原理,画图中的node节点都很理想化的相对均匀分布,但理想和实际的场景往往差别很大,就比如办了个健身年卡的我,只去过健身房两次,还只是洗了个澡。

在服务器节点数量太少的情况下,很容易因为节点分布不均匀而造成数据倾斜问题,如下图被缓存的对象大部分缓存在node-4服务器上,导致其他节点资源浪费,系统压力大部分集中在node-4节点上,这样的集群是非常不健康的。

解决数据倾斜的办法也简单,我们就要想办法让节点映射到hash环上时,相对分布均匀一点。
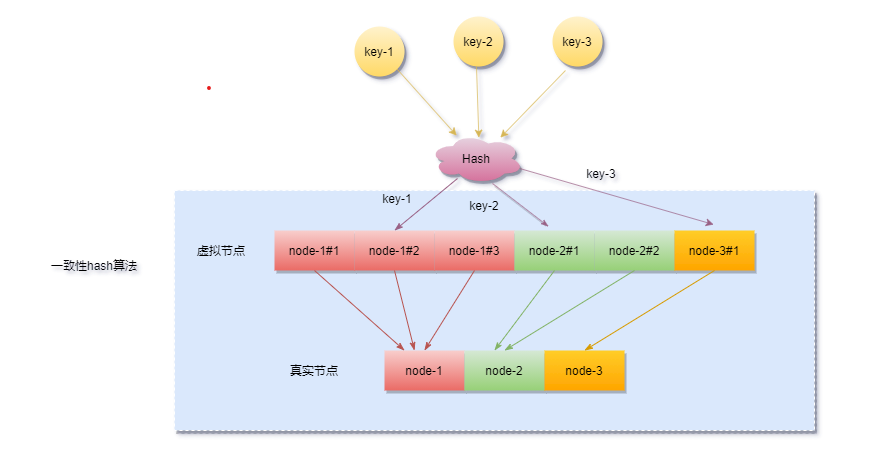
一致性Hash算法引入了一个虚拟节点机制,即对每个服务器节点计算出多个hash值,它们都会映射到hash环上,映射到这些虚拟节点的对象key,最终会缓存在真实的节点上。
虚拟节点的hash计算通常可以采用,对应节点的IP地址加数字编号后缀 hash(10.24.23.227#1) 的方式,举个例子,node-1节点IP为10.24.23.227,正常计算node-1的hash值。
hash(10.24.23.227#1)% 2^32
假设我们给node-1设置三个虚拟节点,node-1#1、node-1#2、node-1#3,对它们进行hash后取模。
hash(10.24.23.227#1)% 2^32hash(10.24.23.227#2)% 2^32hash(10.24.23.227#3)% 2^32
下图加入虚拟节点后,原有节点在hash环上分布的就相对均匀了,其余节点压力得到了分摊。

但需要注意一点,分配的虚拟节点个数越多,映射在hash环上才会越趋于均匀,节点太少的话很难看出效果
引入虚拟节点的同时也增加了新的问题,要做虚拟节点和真实节点间的映射,对象key->虚拟节点->实际节点之间的转换。
一致性hash的应用场景
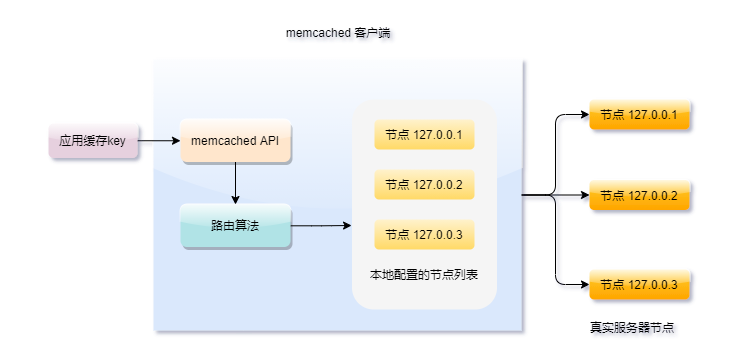
一致性hash在分布式系统中应该是实现负载均衡的首选算法,它的实现比较灵活,既可以在客户端实现,也可以在中间件上实现,比如日常使用较多的缓存中间件memcached和redis集群都有用到它。
memcached的集群比较特殊,严格来说它只能算是伪集群,因为它的服务器之间不能通信,请求的分发路由完全靠客户端来的计算出缓存对象应该落在哪个服务器上,而它的路由算法用的就是一致性hash。
还有redis集群中hash槽的概念,虽然实现不尽相同,但思想万变不离其宗,看完本篇的一致性hash,你再去理解redis槽位就轻松多了。
其它的应用场景还有很多:
RPC框架Dubbo用来选择服务提供者- 分布式关系数据库分库分表:数据与节点的映射关系
LVS负载均衡调度器- .....................
总结
简单的阐述了下一致性hash,如果有不对的地方大家可以留言指正,任何技术都不会十全十美,一致性Hash算法也是有一些潜在隐患的,如果Hash环上的节点数量非常庞大或者更新频繁时,检索性能会比较低下,而且整个分布式缓存需要一个路由服务来做负载均衡,一旦路由服务挂了,整个缓存也就不可用了,还要考虑做高可用。
不过话说回来,只要是能解决问题的都是好技术,有点副作用还是可以忍受的。
不会一致性hash算法,劝你简历别写搞过负载均衡的更多相关文章
- 编程艺术第十六~第二十章:全排列/跳台阶/奇偶调序,及一致性Hash算法
目录(?)[+] 第十六~第二十章:全排列,跳台阶,奇偶排序,第一个只出现一次等问题 作者:July.2011.10.16.出处:http://blog.csdn.net/v_JULY_v. 引言 ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 一致性hash算法详解
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT) ...
- 一致性hash算法简介
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简单哈希 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 一致性 hash 算法( consistent hashing )a
一致性 hash 算法( consistent hashing ) 张亮 consistent hashing 算法早在 1997 年就在论文 Consistent hashing and rando ...
- 一致性hash算法简介与代码实现
一.简介: 一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义: 1.平衡性(Balance) 2.单调性(Monotonicity) 3.分散性(Spread) 4.负 ...
- memcache的一致性hash算法使用
一.概述 1.我们的memcache客户端(这里我看的spymemcache的源码),使用了一致性hash算法ketama进行数据存储节点的选择.与常规的hash算法思路不同,只是对我们要存储数据的k ...
- 一致性Hash算法在Redis分布式中的使用
由于redis是单点,但是项目中不可避免的会使用多台Redis缓存服务器,那么怎么把缓存的Key均匀的映射到多台Redis服务器上,且随着缓存服务器的增加或减少时做到最小化的减少缓存Key的命中率呢? ...
随机推荐
- Django中提示消息messages的设置
1. 引入messages模块 1 from django.contrib import messages 2. 把messages写入view中 1 @csrf_exempt 2 def searc ...
- 贪心——122.买卖股票的最佳时机II
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格. 设计一个算法来计算你所能获取的最大利润.你可以尽可能地完成更多的交易(多次买卖一支股票). 注意:你不能同时参与多笔交易(你必须在再次 ...
- java 多线程 :ThreadLocal 共享变量多线程不同值方案;InheritableThreadLocal变量子线程中自定义值,孙线程可继承
ThreadLocal类的使用 变量值的共享可以使用public static变量的形式,所有的线程都是用同一个public static变量.如果想实现每一个线程都有自己的值.该变量可通过Thr ...
- C++11新特性:enable_shared_from_this
enable_shared_from_this是一个模板类,定义于头文件<memory>,其原型为:template< class T > class enable_share ...
- 关于Marshal 类的整理
在两个不同的实体(两个线程或者进程甚至机器.在Managed和Unmanaged之间)进行方法调用和参数传递的时候,具体的调用方法和参数的内存格式可能需要一定的转换,这个转换的过程叫做Marshal. ...
- git clone 报错:SSL certificate prob lem: self signed certificate
先执行: git config --global http.sslVerify false 然后重新执行git clone 命令即可
- SpringBoot项目使用Caffeine本地缓存
环境配置:(或以上版本,必须) JDK 版本:1.8 Caffeine 版本:2.8.0SpringBoot 版本:2.2.2.RELEASE 也可以不与SpringBoot结合 1.添加maven ...
- 【LeetCode】5685. 交替合并字符串 Merge Strings Alternately (Python)
作者: 负雪明烛 id: fuxuemingzhu 公众号:每日算法题 本文关键词:LeetCode,力扣,算法,算法题,交替合并字符串,Merge Strings Alternately,刷题群 目 ...
- 【LeetCode】910. Smallest Range II 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- ZFNet: Visualizing and Understanding Convolutional Networks
目录 论文结构 反卷积 ZFnet的创新点主要是在信号的"恢复"上面,什么样的输入会导致类似的输出,通过这个我们可以了解神经元对输入的敏感程度,比如这个神经元对图片的某一个位置很敏 ...