FlinkSQL使用自定义UDTF函数行转列-IK分词器
一、背景说明
本文基于IK分词器,自定义一个UDTF(Table Functions),实现类似Hive的explode行转列的效果,以此来简明开发过程。
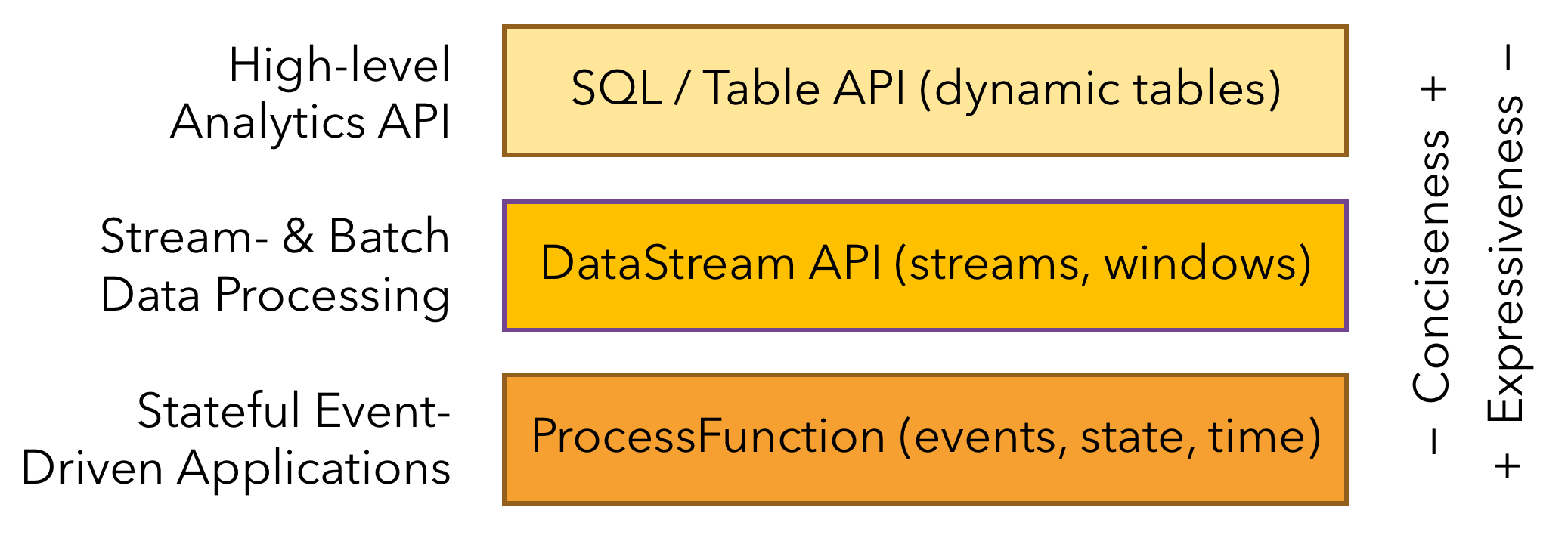
如下图Flink三层API接口中,Table API的接口位于最顶层也是最易用的一层,可以套用SQL语法进行代码编写,对于有SQL基础的能很快上手,但是不足之处在于灵活度有限,自有函数不能满足使用的时候,需要通过自定义函数实现,类似Hive的UDF/UDTF/UDAF自定义函数,在Flink也可以称之为Scalar Functions/Table Functions/Aggregate Functions。
二、效果预览
Kafka端建立生产者发送json片段:

IDEA侧消费数据处理后效果:

如上所示,形成类似Hive的exploed炸裂函数实现行转列的效果,当然也可以不用IK分词器,直接按空格进行split实现逻辑是一样的。
三、代码过程
由于Flink一般在流式环境使用,故这里数据源使用Kafka,并建立动态表的形式实现,以更好的贴近实际的业务环境。
- 工具类:
package com.test.UDTF;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
/**
* @author: Rango
* @create: 2021-05-04 16:50
* @description: 建立函数,继承TableFunction并建立eval方法
**/
@FunctionHint(output = @DataTypeHint("ROW<word STRING>"))
public class KeywordUDTF extends TableFunction<Row> {
//按官方文档说明,须按eval命名
public void eval(String value){
List<String> stringList = analyze(value);
for (String s : stringList) {
Row row = new Row(1);
row.setField(0,s);
collect(row);
}
}
//自定义分词方式
public List<String> analyze(String text){
//字符串转文件流
StringReader sr = new StringReader(text);
//建立分词器对象
IKSegmenter ik = new IKSegmenter(sr,true);
//ik分词后对象为Lexeme
Lexeme lex = null;
//分词后转入列表
List<String> keywordList = new ArrayList<>();
while(true){
try {
if ((lex = ik.next())!=null){
keywordList.add(lex.getLexemeText());
}else{
break;
}
} catch(IOException e) {
e.printStackTrace();
}
}return keywordList;
}
}
- 实现类
package com.test.UDTF;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* @author: Rango
* @create: 2021-05-04 17:11
* @description:
**/
public class KeywordStatsApp {
public static void main(String[] args) throws Exception {
//建立环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
//注册函数
tableEnv.createTemporaryFunction("ik_analyze", KeywordUDTF.class);
//建立动态表
tableEnv.executeSql("CREATE TABLE wordtable (" +
"word STRING" +
") WITH ('connector' = 'kafka'," +
"'topic' = 'keywordtest'," +
"'properties.bootstrap.servers' = 'hadoop102:9092'," +
"'properties.group.id' = 'keyword_stats_app'," +
"'format' = 'json')");
//未切分效果
Table wordTable = tableEnv.sqlQuery("select word from wordtable");
//利用自定义函数对文本进行分切,切分后计为1,方便后续统计使用
Table wordTable1 = tableEnv.sqlQuery("select splitword,1 ct from wordtable," +
"LATERAL TABLE(ik_analyze(word)) as T(splitword)");
tableEnv.toAppendStream(wordTable, Row.class).print("原格式>>>");
tableEnv.toAppendStream(wordTable1, Row.class).print("使用UDTF函数效果>>>");
env.execute();
}
}
- 补充下依赖
<properties>
<java.version>1.8</java.version>
<flink.version>1.12.0</flink.version>
<scala.version>2.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
学习交流,有任何问题还请随时评论指出交流。
FlinkSQL使用自定义UDTF函数行转列-IK分词器的更多相关文章
- solr添加中文IK分词器,以及配置自定义词库
Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置,而且附带了一个基于H ...
- hive自定义UDTF函数叉分函数
hive自定义UDTF函数叉分函数 1.介绍 从聚合体日志中需要拆解出来各子日志数据,然后单独插入到各日志子表中.通过表生成函数完成这一过程. 2.定义ForkLogUDTF 2.1 HiveUtil ...
- 在论坛中出现的比较难的sql问题:19(row_number函数 行转列、sql语句记流水)
原文:在论坛中出现的比较难的sql问题:19(row_number函数 行转列.sql语句记流水) 最近,在论坛中,遇到了不少比较难的sql问题,虽然自己都能解决,但发现过几天后,就记不起来了,也忘记 ...
- Spark基于自定义聚合函数实现【列转行、行转列】
一.分析 Spark提供了非常丰富的算子,可以实现大部分的逻辑处理,例如,要实现行转列,可以用hiveContext中支持的concat_ws(',', collect_set('字段'))实现.但是 ...
- 31.IK分词器配置文件讲解以及自定义词库
主要知识点: 知道IK默认的配置文件信息 自定义词库 一.ik配置文件 ik配置文件地址:es/plugins/ik/config目录 IKAnalyzer.cfg.xml:用 ...
- 30.IK分词器配置文件讲解以及自定义词库
主要知识点: 知道IK默认的配置文件信息 自定义词库 一.ik配置文件 ik配置文件地址:es/plugins/ik/config目录 IKAnalyzer.cfg.xml:用 ...
- 利用IK分词器,自定义分词规则
IK分词源码下载地址:https://code.google.com/p/ik-analyzer/downloads/list lucene源码下载地址:http://www.eu.apache.or ...
- SqlServer PIVOT函数快速实现行转列,UNPIVOT实现列转行
我们在写Sql语句的时候没经常会遇到将查询结果行转列,列转行的需求,拼接sql字符串,然后使用sp_executesql执行sql字符串是比较常规的一种做法.但是这样做实现起来非常复杂,而在SqlSe ...
- SqlServer PIVOT函数快速实现行转列,UNPIVOT实现列转行(转)
我们在写Sql语句的时候没经常会遇到将查询结果行转列,列转行的需求,拼接sql字符串,然后使用sp_executesql执行sql字符串是比较常规的一种做法.但是这样做实现起来非常复杂,而在SqlSe ...
随机推荐
- ajax传数组后台GO语言接收
js代码如下: function PostHandle(url,data,callback) { $.ajax({ type: "Post", url:url, data:data ...
- python中对类的方法中参数self的理解
我们通过下面的代码来对参数self进行理解 #coding:utf-8 2 class washer(): 3 def wash(self): 4 print("洗衣服") 5 p ...
- 走进docker-初识
什么是Docker容器? 容器是打包代码及其所有依赖项的软件的标准单元,因此应用程序可以从一个计算环境快速可靠地运行到另一个计算环境.Docker容器映像是一个轻量级的,独立的,可执行的软件软件包,其 ...
- 92反转链表II
# Definition for singly-linked list.# 这道题还是有点复杂的,但是是有套路的,套用反转链表的想法class ListNode: def __init__(self, ...
- Java例题_31 逆序输出数组的值
1 /*31 [程序 31 数组逆序] 2 题目:将一个数组逆序输出. 3 程序分析:用第一个与最后一个交换. 4 */ 5 6 /*分析 7 * 第一种方法:找到这个数组的中间下标,然后交换两端的数 ...
- 日志文件删除shell脚本
大日志文件切割shell脚本 #!/bin/bash # --------------------------------------------------------------------- # ...
- 开源组件编排引擎LiteFlow发布里程碑版本2.5.0
介绍 LiteFlow作为一款轻量级组件编排框架,自开源来,获得了挺多人的关注.社区群也扩展到了接近200人. 早期版本因为疏忽打理,有一些BUG,迭代也不及时.距离上一个稳定版本2.3.3,已经有超 ...
- Ansible 教程
[注]本文译自:https://www.edureka.co/blog/ansible-tutorial/ 在阅读本文之前,你应该已经知道,Ansible 构成了 DevOps 认证的关键部分,它 ...
- 【pytest系列】- assert断言的使用
unittest断言方式是用过框架自己实现的,即self.assertEqual()等,当我们使用pytest框架后,这种断言方式是不可用的,因为测试类不会再继承unittest.TestCase类, ...
- Visual Studio 2015 无法加载.Net FrameWork4.6.2
默认的VS2015是没有.Net Framework4.6.2的 需要我们去到微软官网下载对应的.NET Framework 4.6.2的安装包 安装包分两种,一种是应用级别的还一种是开发级别的,如果 ...