成本计划的输出(Project)
《Project2016 企业项目管理实践》张会斌 董方好 编著
所谓“输出”就是把数据摆出来让人看,好吧,这种“看”,可以直接在屏幕上看,也可以打印出来看。
先说直接在屏幕上看,那真没什么可多说的,【甘特图】视图里【任务工作表】上,把【成本】列“祭”出来,不就能看了吗?
好吧,有些大项目,任务特别特别多,那就不是每个被细分的任务的成本都要去一一看过,那就到【视图】选项卡下,把【大纲】的下拉选项拉出来,选一个合适的级别。
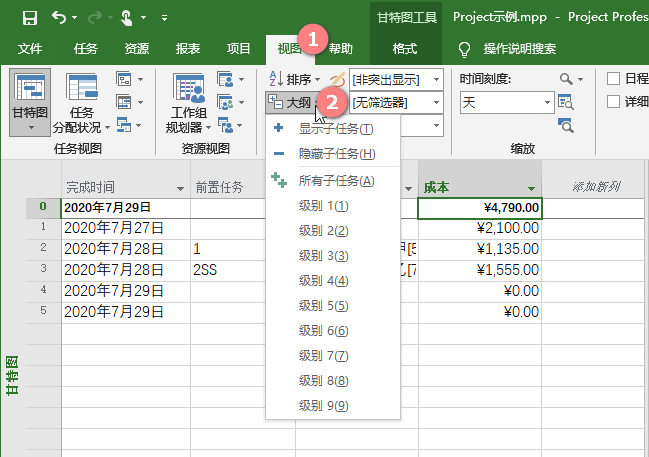
再要想看某个大纲【摘要任务】里的明细,那就把那个【摘要任务】给展开呗。
再说打印,那就是【文件】选项卡下的【打印】,整个熬肥的设置都差不多,不多说了。
以上都是些不新鲜的!
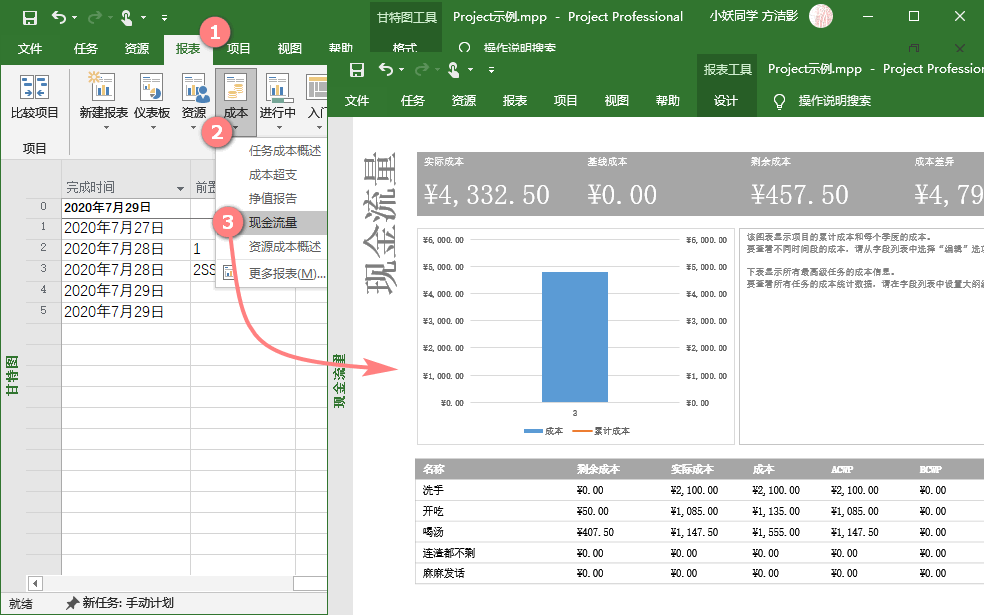
新鲜的是什么呢?是【报表】。
比如想看现金流量表,那就只要选取【报表】选项卡下,【成本】里的【现金流量】就可以了,什么心思都不用操,人家Project同学给整得妥妥的。
成本计划的输出(Project)的更多相关文章
- 与你一起学习MS Project——基础篇:Project基础应用
为了更清晰容易地熟悉掌握Project的基础应用,我们在基础篇中一起来学习掌握在Project中如何做进度计划.资源计划.成本计划以及跟踪项目的执行情况并生成所需的项目报表. 一.进度计划 这里,首先 ...
- 关于 iOS 批量打包的总结
关于 iOS 批量打包的总结 本文作者: 伯乐在线 - Tsui YuenHong .未经作者许可,禁止转载!欢迎加入伯乐在线 专栏作者. 如果你曾经试过做多 target 的项目,到了测试人员要 ...
- idea live template高级知识, 进阶(给方法,类,js方法添加注释)
为了解决用一个命令(宏)给方法,类,js方法添加注释,经过几天的研究.终于得到结果了. 实现的效果如下: 给Java中的method添加方法: /** * * @Method : addMenu * ...
- python redis存入字典序列化存储
在python中通过redis hset存储字典时,必须主动把字典通过json.dumps()序列化为字符串后再存储, 不然hget获取后将无法通过json.loads()反序列化为字典 序列化存储 ...
- iOS 批量打包
如果你曾经试过做多 target 的项目,到了测试人员要测试包的时候,你就会明白什么叫“生不如死”.虽然 Xcode 打包很方便,但是当你机械重复打 N 次包的时候,就会觉得这纯粹是浪费时间的工作.所 ...
- 在单进程单线程或单进程多线程下实现log4cplus写日志并按大小切割
基于脚本配置来过滤log信息 除了通过程序实现对log环境的配置之外.log4cplus通过PropertyConfigurator类实现了基于脚本配置的功能.通过 脚本能够完毕对logger.app ...
- OpenShift 3.11离线环境的jenkins演示
离线安装完成后,一般情况下只装了个基础环境,catalog镜像没有导入,本文主要侧重在jenkins的一些环境设置和演示. 1.导入镜像 首先follow下面链接下载镜像 https://docs.o ...
- Maven的属性,${project.basedir},${project.build.directory}:项目构件输出目录,默认为 target/
内置属性 主要有两个常用内置属性:${basedir}项目的根目录(包含pom.xml文件的目录),${version}项目版本 POM属性 用户可以使用该属性引用POM文件中对应元素的值,常用的PO ...
- Dynemic Web Project中使用servlet的 doGet()方法接收来自浏览器客户端发送的add学生信息形成json字符串输出到浏览器并保存到本地磁盘文件
package com.swift.servlet; import java.io.FileOutputStream;import java.io.IOException;import java.io ...
随机推荐
- [noi34]palindrome
分割实际上就是不断地从两端取出一样的一段,并对剩下的串进行分割.下面我们来证明一下每一次贪心取出最短一段的正确性: 考虑两种分割方式,分别表示成S=A+B+A和S=C+D+C,其中A就是最短的一段,那 ...
- .Net Crank性能测试入门
Crank 是微软新出的一个性能测试框架,集成了多种基准测试工具,如bombardier.wrk等. Crank通过统一的配置,可以转换成不同基准测试工具命令进行测试.可参考Bombardier Jo ...
- poi上传下载
本教程只实现poi简单的上传下载功能,如需高级操作请绕行! <!--poi start--> <dependency> <groupId>org.apache.po ...
- BehaviorTree.CPP行为树BT的选择节点(四)
Fallback 该节点家族在其他框架中被称为"选择器Selector"或"优先级Priority". 他们的目的是尝试不同的策略,直到找到可行的策略. 它们具 ...
- 力扣 - 剑指 Offer 47. 礼物的最大价值
题目 剑指 Offer 47. 礼物的最大价值 思路1 因为是要求最大价值,而且只能移动下方或者右方,因此,每个位置的最大值就是本身的值加上上边 / 左边 中的最大值,然后每次遍历都可以复用上一次的值 ...
- linux中对errno是EINTR的处理
慢系统调用(slow system call):此术语适用于那些可能永远阻塞的系统调用.永远阻塞的系统调用是指调用有可能永远无法返回,多数网络支持函数都属于这一类.如:若没有客户连接到服务器上,那么服 ...
- cmd查看同一个局域网内电脑IP
win+R,cmd #快速打开cmd窗口 net view #查看本地局域网内开启了哪些计算机共享 运行后可以看到已共享的计算机名称 net view ip #查看对方局域网内开启了哪些共享 ...
- C语言中的字符和整数之间的转换
首先对照ascal表,查找字符和整数之间的规律: ascall 控制字符 48 0 49 1 50 2 51 3 52 4 53 5 54 6 55 7 56 8 ...
- Hadoop入门 完全分布式运行模式-准备
目录 Hadoop运行环境 完全分布式运行模式(重点) scp secure copy 安全拷贝 1 hadoop102上的JDK文件推给103 2 hadoop103从102上拉取Hadoop文件 ...
- 【vector+pair】洛谷 P4715 【深基16.例1】淘汰赛
题目:P4715 [深基16.例1]淘汰赛 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 这道题因为数据范围不大,所以做法可以非常简单,使用一个vector加上pair就可以了: ...