Django(69)最好用的过滤器插件Django-filter
前言
如果需要满足前端各种筛选条件查询,我们使用drf自带的会比较麻烦,比如查询书名中包含“国”字,日期大于“2020-1-1”等等诸如此类的请求,Django-filter这个组件就是要解决这样的问题。
1.安装
Django-filter支持的Python版本和Django版本、DRF版本如下:
- Python: 3.5, 3.6, 3.7, 3.8
- Django: 1.11, 2.0, 2.1, 2.2, 3.0
- DRF: 3.10+
在虚拟环境中安装
pip3 install django-filter
在Django的settings.py文件中安装并配置django_filters应用:
INSTALLED_APPS = [
...
'django_filters',
]
REST_FRAMEWORK = {
# 过滤器默认后端
'DEFAULT_FILTER_BACKENDS': (
'django_filters.rest_framework.DjangoFilterBackend',),
}
2.使用流程
我们通过一个简单的图书查询来说明如果在DRF中使用Django-filter过滤器。图书模型如下:
# models.py
class BookInfo(models.Model):
title = models.CharField(max_length=200,verbose_name='标题')
pub_date = models.DateField(blank=True, null=True,verbose_name='出版日期')
read = models.IntegerField(null=True,verbose_name='阅读数量')
comment = models.IntegerField(null=True,verbose_name='评论数量')
image = models.CharField(max_length=200, blank=True, null=True,verbose_name='图片')
class Meta:
db_table = 'bookInfo'
verbose_name = "图书"
序列化类:
# serializers.py
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = BookInfo
fields = '__all__'
自定义过滤器类:
# filters.py
from django_filters import rest_framework as filters
from . models import BookInfo
class BookFilter(filters.FilterSet):
min_read = filters.NumberFilter(field_name="read", lookup_expr='gte')
max_read = filters.NumberFilter(field_name="read", lookup_expr='lte')
class Meta:
model = BookInfo
fields = ['read']
在视图中
# views.py
class BookView(ListAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookSerializer
filter_class = BookFilter
url配置中
app_name = "api"
urlpatterns = [
path('books/', views.BookView.as_view()),
]
现在我们想筛选阅读数为500-1000的图书,测试结果如下
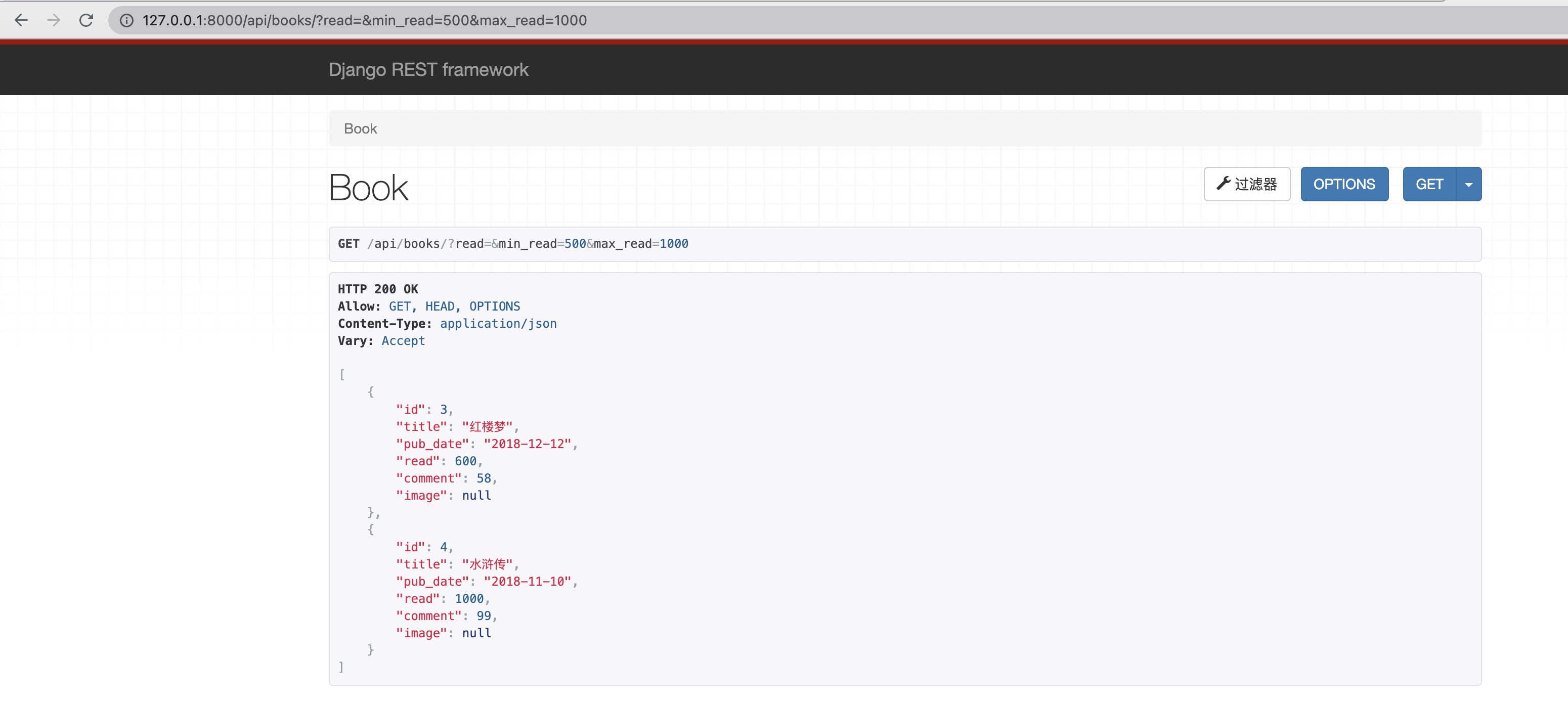
详解过滤器类
过滤器类和Django中表单类极其类似,写法基本一样,目的是指明过滤的时候使用哪些字段进行过滤,每个字段可以使用哪些运算。运算符的写法基本参照Django的ORM中查询的写法,比如:大于等于,小于等于用"gte","lte"等等
可以通过模型快速构建过滤器类
from django_filters import rest_framework as filters
class BookFilter(filters.FilterSet):
class Meta:
model = BookInfo # 模型名
fields = ['title','comment'] # 可以使用的过滤字段
Meta中出现的fields是指过滤条件中可以出现的字段,默认是精确判断相等,查询的时候可以这样用:
http://127.0.0.1:8000/api/books/?comment=20&title=
以上代表查询的是评论条数为20条的书本
如果不是判断相等,可以自定义过滤字段进行过滤:
- 过滤器中常用的字段类型,这些类型要输模型中对应字段类型兼容
CharFilter 字符串类型
BooleanFilter 布尔类型
DateTimeFilter 日期时间类型
DateFilter 日期类型
DateRangeFilter 日期范围
TimeFilter 时间类型
NumberFilter 数值类型,对应模型中IntegerField, FloatField, DecimalField
- 过滤字段参数说明:
field_name: 过滤字段名,一般应该对应模型中字段名
lookup_expr: 查询时所要进行的操作,和ORM中运算符一致
- Meta字段说明
model: 引用的模型,不是字符串
fields:指明过滤字段,可以是列表,列表中字典可以过滤,默认是判断相等;也可以字典,字典可以自定义操作
exclude = ['password'] 排除字段,不允许使用列表中字典进行过滤
自定义过滤字段:
class BookFilter(filters.FilterSet):
title = filters.CharFilter(field_name='title',lookup_expr='icontains') # 标题中包含
pub_year = filters.CharFilter(field_name='pub_date',lookup_expr='year') # 过滤年份相等
pub_year__gt = filters.CharFilter(field_name='pub_date',lookup_expr='year__gt') # 过滤大于年份
read__gt = filters.NumberFilter(field_name='read',lookup_expr="gt") # 最大阅读数
read__lt = filters.NumberFilter(field_name='read',lookup_expr="lt") # 最小阅读数
class Meta:
model = BookInfo
fields = ['title','read','comment']
自定义字段名可以和模型中不一致,但一定要用参数field_name指明对应模型中的字段名
日期查询
定义按年查询
pub_year = filters.CharFilter(field_name='pub_date',lookup_expr='year')
年份应该大于某值
pub_year__gt = filters.CharFilter(field_name='pub_date',lookup_expr='year__gt')
年份应该小于某值
read__lt = filters.NumberFilter(field_name='read',lookup_expr="lt")
查询出版年份大于2019年的书本
http://127.0.0.1:8000/api/books/?title=&read=&comment=&pub_year=&pub_year__gt=2019&read__gt=&read__lt=
查询结果:
[
{
"id": 1,
"title": "钢铁是怎样练成的",
"pub_date": "2020-10-09",
"read": 100,
"comment": 3,
"image": null
}
]
标题查询
title查询的时候可以进行包含查询,icontains在ORM中表示不区分大小的包含
title = filters.CharFilter(field_name='btitle',lookup_expr='icontains')
查询标题中包含三国演义的书籍
http://127.0.0.1:8000/api/books/?title=%E4%B8%89%E5%9B%BD%E6%BC%94%E4%B9%89&read=&comment=&pub_year=&pub_year__gt=&read__gt=&read__lt=
查询结果:
[
{
"id": 2,
"title": "三国演义",
"pub_date": "2019-11-12",
"read": 200,
"comment": 20,
"image": null
}
]
阅读数查询
阅读数大于
read__gt = filters.NumberFilter(field_name='read',lookup_expr="gt")
阅读数小于
read__lt = filters.NumberFilter(field_name='read',lookup_expr="lt")
查询阅读数在100-300之间的书籍
http://127.0.0.1:8000/api/books/?title=&read=&comment=&pub_year=&pub_year__gt=&read__gt=100&read__lt=300
查询结果:
[
{
"id": 2,
"title": "三国演义",
"pub_date": "2019-11-12",
"read": 200,
"comment": 20,
"image": null
}
]
官方文档:https://django-filter.readthedocs.io/en/stable/guide/install.html
Django(69)最好用的过滤器插件Django-filter的更多相关文章
- Django学习(九)---Templates过滤器及Django shell和Admin增强
一.Templates过滤器 过滤器属于django模板语言 修改模板中的变量,从而显示不同内容 {{ value | filter }} 举例:{{ list_nums | length}} ...
- day056-58 django多表增加和查询基于对象和基于双下划线的多表查询聚合 分组查询 自定义标签过滤器 外部调用django环境 事务和锁
一.多表的创建 from django.db import models # Create your models here. class Author(models.Model): id = mod ...
- django基础 -- 4. 模板语言 过滤器 模板继承 FBV 和CBV 装饰器 组件
一.语法 两种特殊符号(语法): {{ }}和 {% %} 变量相关的用{{}},逻辑相关的用{%%}. 二.变量 1. 可直接用 {{ 变量名 }} (可调用字符串, 数字 ,列表,字典,对象等) ...
- django模板中的自定义过滤器
(1)在APP下创建templatetags文件夹,与Models.py.views.py等同级,templatetags文件夹下添加__init__.py文件,可为空,再添加一个模块文件,例如cpt ...
- django下载excel,使用django-excel插件
django下载Excel,使用django-excel插件 由于目前的资料多是使用pandas或xlwt库实现的.其实没有那么的麻烦,因为django有相对应的插件django-excel. 该插件 ...
- python 之 Django框架(模板系统、过滤器、simple_tag、inclusion_tag、Tags、母版、组件)
12.35 Django模板系统 {{ }}和 {% %},变量相关的用{{}},逻辑相关的用{%%} app02/views: # 模板语言测试函数 def template_test(reques ...
- Django框架10 /sweetalert插件、django事务和锁、中间件、django请求生命周期
Django框架10 /sweetalert插件.django事务和锁.中间件.django请求生命周期 目录 Django框架10 /sweetalert插件.django事务和锁.中间件.djan ...
- Django学习系列之captcha 验证码插件
安装部署 安装captcha pip3. install django-simple-captcha== settings.py中引入captcha INSTALLED_APPS = [ 'djang ...
- 学习django就看这本书了!django book 2.0中文版
所属网站分类: 资源下载 > python电子书 作者:熊猫烧香 链接:http://www.pythonheidong.com/blog/article/29/ 来源:python黑洞网 dj ...
- Django 资源 与 知识 Django中自建脚本并使用Django环境 model中的save()方法说明 filter()用法
Django 资源 与 知识 Django中自建脚本并使用Django环境 model中的save()方法说明 filter()用法 2018/11/06 Chenxin 资料说明 Django基础入 ...
随机推荐
- 使用 cmake 来搭建跨平台的应用程序框架:C语言版本
目录 一.前言 二.示例代码说明 1. 功能描述 2. 文件结构 3. cmake 构建步骤 4. Utils 目录说明 5. Application 目录说明 三.Linux 系统下操作步骤 1. ...
- C++ string的size()和length()函数没有区别
C++标准库中的string中两者的源代码如下: size_type __CLR_OR_THIS_CALL length() const { // return ...
- 【BUAA软工】Beta阶段事后分析
设想与目标 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 解决的问题 总体解决的问题:新手编程者配置编程环境难.本地编写的代码跨设备同步难.本地ide安装使用过程 ...
- chardet模块
import chardet chardet.detect(f.read())检测哪种编码
- Cookie&Session-授课
1 会话技术 1.1 会话管理概述 1.1.1 什么是会话 会话:浏览器和服务器之间的多次请求和响应 为了实现一些功能,浏览器和服务器之间可能会产生多次的请求和响应,从浏览器访问服务器开始,到访问服务 ...
- MD5加密以及登录获取设置token
MD5简介 MD5是不可逆的加密算法,基本上是不可破解的,网上有些破解网站,其实是利用了穷举法,因为MD5生成的串是一样的,他们会将常规的密码生成MD5加密串,保存,然后破解的时候去穷举比对.(应对之 ...
- 【转载】Linux命令-自动挂载文件/etc/fstab功能详解[转]
博客园 首页 新随笔 联系 订阅 管理 随笔 - 322 文章 - 0 评论 - 19 Linux命令-自动挂载文件/etc/fstab功能详解[转] 一./etc/fstab文件的作用 ...
- python基础之流程控制(if判断和while、for循环)
程序执行有三种方式:顺序执行.选择执行.循环执行 一.if条件判断 1.语句 (1)简单的 if 语句 (2)if-else 语句 (3)if-elif-else 结构 (4)使用多个 elif 代码 ...
- C语言练习题1(关于快速排序,二分查找与运行时间)
刚刚完成师兄给的一道题目: 随机生成10000位数,进行快速排序后,用二分查找法定位到某个要查询的数(键盘输入某个要查询的数), 结果输出查询的时间,以及是否查到 分享下自己的解题思路: 1,要懂得 ...
- KMP算法中我对获取next数组的理解
之前在学KMP算法时一直理解不了获取next数组的函数是如何实现的,现在大概知道怎么一回事了,记录一下我对获取next数组的理解. KMP算法实现的原理就不再赘述了,先上KMP代码: 1 void g ...