python网络爬虫-解析网页(六)
解析网页
主要使用到3种方法提取网页中的数据,分别是正则表达式、beautifulsoup和lxml。
使用正则表达式解析网页
正则表达式是对字符串操作的逻辑公式
.代替任意字符 、 *匹配前0个或多个 、 + 匹配前1个或多个 、 ?前0次或1次 、
^开头 、 $ 结尾 、()匹配括号里面的表达式表示一组 、 []表示一组字符 、
\s匹配空白字符 、 \S 匹配非空白字符 、 \d[0-9] 、 \D[^0-9] 、
\w匹配字母数字[A-Z,a-z,0-9] 、 \W匹配不是字母数字
re.match方法:从字符串其实位置匹配一个模式,从起始位置匹配不了,match()就返回none
语法:re.match(pattern,string,flags=0)
pattern是正则表达式
string为要匹配的字符串
flags控制正则表达式的匹配方式,是否需要区分大小写、多行匹配
m = re.match('www', 'www.baidu.com')
re.search方法:扫描整个字符串,找到第一个成功的匹配内容
m_search = re.search('com', 'www.baidu.com')
re.findall:可以找到所有的匹配
m_findall = re.findall('[0-9+]', '123156 www.baidu.com')
使用BeautifulSoup解析网页
BeautifulSoup安装
pip install bs4
解析器
python标准库 BeautifulSoup(r.text, 'html.parser')
lxmlHTML BeautifulSoup(r.text, 'lxml')
lxmlXML BeautifulSoup(r.text, 'xml')
# CSS选择器
print(suop.select("div div header h1"))
print(suop.select("div>a"))
使用lxml解析网页
Xpath语法,是效率比较高的解析方法
lxml安装
pip install bs4
使用lxml
print("解析lxml")
# 解析lxml
html1 = html.etree.HTML(r.text)
title_list = html1.xpath('//h2[@class="dYInr JOzNE z2wCE"]/span/text()')
print(title_list)
提取网页源码数据也有三种方法,即XPath选择器、CSS选择器、BeautifulSoup的find()方法
Xpath的选取方法
选取节点
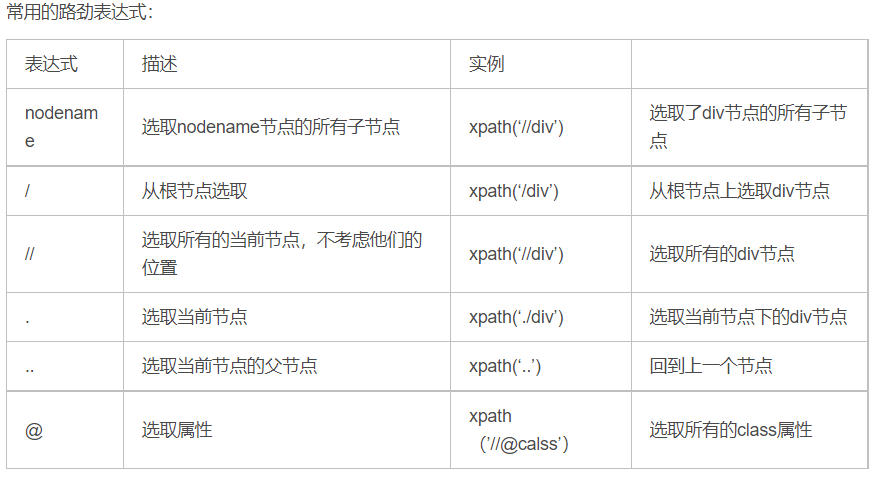
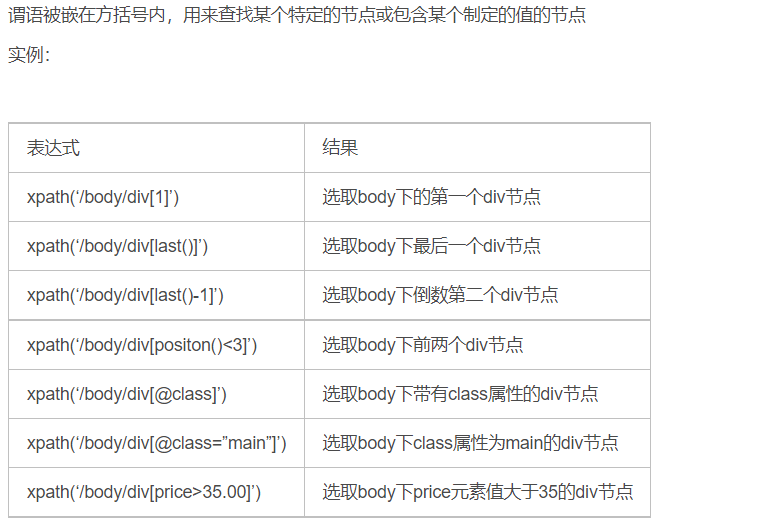
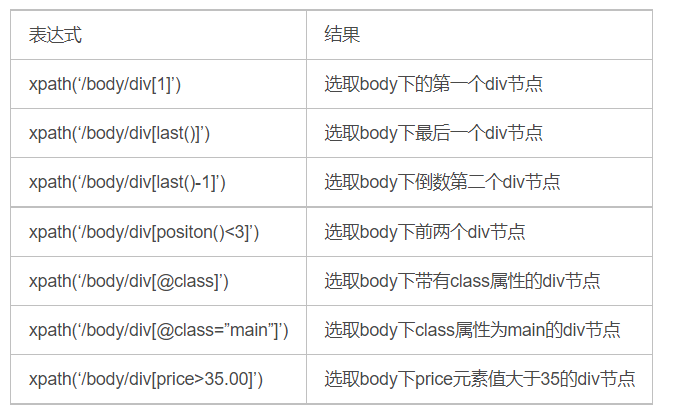
谓语
通配符

取多个路径

Xpath轴


功能函数

总结
推荐使用beautifulsoup的find方法,熟悉xpath的可以选择lxml,面对复杂的网页使用正则表达比较浪费时间
beautifulsoup爬虫时间:房屋价格数据
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/87.0.4280.88 Safari/537.36"
}
link = 'https://cs.anjuke.com/sale/?from=navigation'
r = requests.get(link, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
hoouse_list = soup.find('div', property)
for house in hoouse_list:
house_name = house.find('h3', class_="property-content-title-name").text.strip()
house_price = house.find('span', class_="property-price-total-text").text.strip()
house_junjia = house.find('p', class_="property-price-average").text.strip()
house_jushi = house.find('p', class_="property-content-info-text property-content-info-attribute").text.strip()
house_mianji = house.find('p', class_="property-content-info-text").contents[0].text
house_loucen = house.find('p', class_="property-content-info-text").contents[1].text
print('楼层:', house_loucen)
print('面积:', house_mianji)
print('居室:', house_jushi)
print('均价:', house_junjia)
print('名称:', house_name)
print('价格:', house_price)python网络爬虫-解析网页(六)的更多相关文章
- python网络爬虫-静态网页抓取(四)
静态网页抓取 在网站设计中,纯HTML格式的网页通常被称之为静态网页,在网络爬虫中静态网页的数据比较容易抓取,因为说有的数据都呈现在网页的HTML代码中.相对而言使用Ajax动态加载的玩个的数据不一定 ...
- python网络爬虫-动态网页抓取(五)
动态抓取的实例 在开始爬虫之前,我们需要了解一下Ajax(异步请求).它的价值在于在与后台进行少量的数据交换就可以使网页实现异步更新. 如果使用Ajax加载的动态网页抓取,有两种方法: 通过浏览器审查 ...
- python网络爬虫笔记(六)
1.获取属性如果不存在就返回404,通过内置一系列函数,我们可以对任意python对象进行剖析,拿到其内部数据,但是要注意的是,只是在不知道对象信息的时候,我们可以获得对象的信息. 2.实例属性和类属 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- 假期学习【六】Python网络爬虫2020.2.4
今天通过Python网络爬虫视频复习了一下以前初学的网络爬虫,了解了网络爬虫的相关规范. 案例:京东的Robots协议 https://www.jd.com/robots.txt 说明可以爬虫的范围 ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
随机推荐
- LeetCode解题报告汇总! All in One!
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 把自己刷过的所有题目做一个整理,并且用简洁的语言概括了一下思路,汇总成了一个表格. 题目 ...
- 【LeetCode】388. Longest Absolute File Path 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述: 题目大意 解题方法 日期 题目地址:https://leetcode. ...
- Fast Matrix Operations(UVA)11992
UVA 11992 - Fast Matrix Operations 给定一个r*c(r<=20,r*c<=1e6)的矩阵,其元素都是0,现在对其子矩阵进行操作. 1 x1 y1 x2 y ...
- GCD(hdu1695)
GCD Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submiss ...
- A New Defense Against Adversarial Images: Turning a Weakness into a Strength
目录 概 主要内容 准则1 准则2 总策略 Hu S, Yu T, Guo C, et al. A New Defense Against Adversarial Images: Turning a ...
- 动态规划题 HDU-1024
http://acm.hdu.edu.cn/showproblem.php?pid=1024 Now I think you have got an AC in Ignatius.L's " ...
- Java初学者作业——编写 Java 程序,让用户输入指定数字实现产生随机数。
返回本章节 返回作业目录 需求说明: 编写 Java 程序,让用户输入指定数字实现产生随机数.运行效果如下: 实现思路: 定义两个变量start和end来保存起始和结束值. 通过结束值减起始值得到变化 ...
- 编写Java程序,用户在网上购买商品(good),当用户买了一本书(book)、一顶帽子(hat)或者买了一双鞋子(shoe),卖家就会通过物流将商品邮寄给用户,使用简单工厂模式模拟这一过程。
查看本章节 查看作业目录 需求说明: 编写Java程序,用户在网上购买商品(good),当用户买了一本书(book).一顶帽子(hat)或者买了一双鞋子(shoe),卖家就会通过物流将商品邮寄给用户, ...
- Java高级程序设计笔记 • 【第6章 设计模式】
全部章节 >>>> 本章目录 6.1 设计模式 6.1.1 设计模式概述和分类 6.1.2 单列模式介绍 6.1.3 单例模式的实现 6.1.4 实践练习 6.2 单例模式 ...
- 啥是Gossip协议?
你好呀,我是歪歪. 元旦的时候我看到一个特别离谱的谣言啊,具体是什么内容我就不说了,我怕脏了大家的眼睛. 但是,我看到一个群里传的那叫一个绘声绘色,大家讨论的风生水起的,仿佛大家就在现场似的. 这事吧 ...