python-scrapy框架学习
Scrapy框架
Scrapy安装
正常安装会报错,主要是两个原因
0x01 升级pip3包
python -m pip install -U pip
0x02 手动安装依赖
需要手动安装 wheel、lxml、Twisted、pywin32
pip3 install wheel
pip3 install lxml
pip3 install Twisted
pip3 install pywin32
0x03 安装Scrapy
pip3 install scrapy
Scrapy 进行项目管理
0x01 使用scrapy创建一个新的爬虫项目
mkdir Scrapy
scrapy startproject myfirstpjt
cd myfirstpjt
0x02 scrapy相关命令
命令分为两种,一种为全局命令,一种为项目命令
全局命令不需要依赖Scrapy项目即可直接与性能,项目命令必须依赖项目
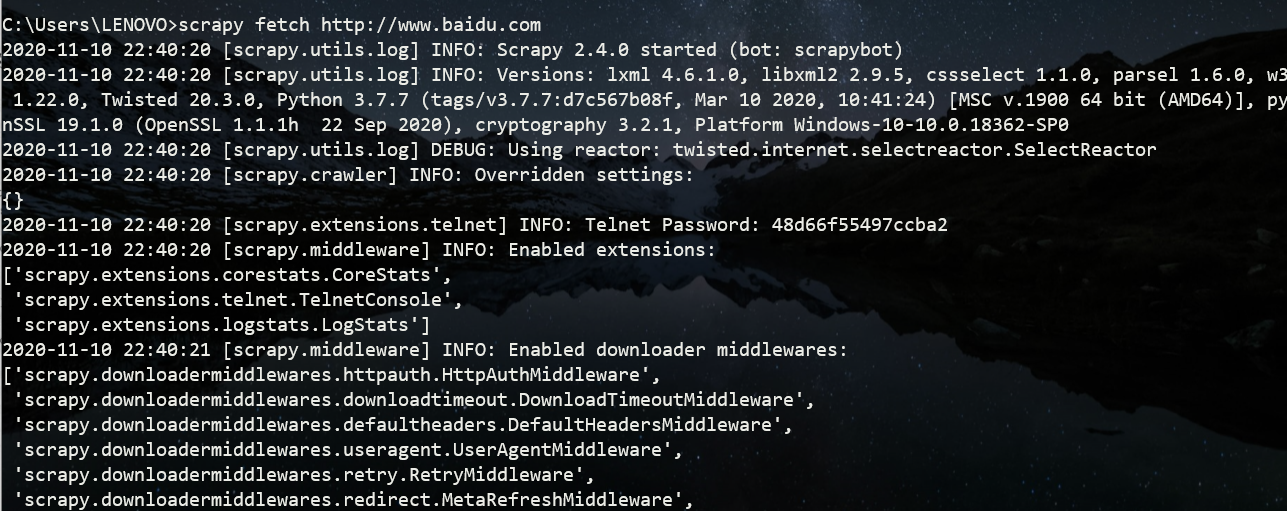
在Scrapy项目所在目录外使用scrapy -h 显示所有全局命令
C:\Users\LENOVO>scrapy -h
Scrapy 2.4.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
commands
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
fetch
fetch命令主要用来显示爬虫爬取过程
0x03 选择器
支持 XPath CSS 选择器
同时XPath选择器还有一个.re()方法用于通过正则表达式来提取数据
,不同于使用.xpath()或者.css()方法,.re()方法返回unicode字符串的 列表,所以无法构造嵌套式的.re()调用
创建Scrapy项目
平常写小脚本或者项目就相当于白纸上写作文,而框架会集成一些经常用的东西将作文题变成填空题,大大减少了工作量
scrapy startproject 项目名称 (例如 todayMovie)
tree todayMovie
D:\pycharm\code\Scrapy>scrapy startproject todayMovie
New Scrapy project 'todayMovie', using template directory 'c:\python3.7\lib\site-packages\scrapy\templates\project', created in:
D:\pycharm\code\Scrapy\todayMovie
You can start your first spider with:
cd todayMovie
scrapy genspider example example.com
D:\pycharm\code\Scrapy>tree todayMovie
文件夹 PATH 列表
卷序列号为 6858-7249
D:\PYCHARM\CODE\SCRAPY\TODAYMOVIE
└─todayMovie
└─spiders
D:\pycharm\code\Scrapy>
0x01 使用 genspider参数新建基础爬虫
新建一个名为wuHanMovieSpider的爬虫脚本,脚本搜索的域为mtime.com
scrapy genspider wuHanMovieSpider mtime.com

0x02 关于框架下的文件
scrapy.cfg
主要声明默认设置文件位置为todayMovie模块下的settings文件(setting.py),定义项目名为todayMovie
items.py文件的作用是定义爬虫最终需要哪些项,
pipelines.py文件的作用是扫尾。Scrapy爬虫爬取了网页中的内容 后,这些内容怎么处理就取决于pipelines.py如何设置
需要修改、填空的只有4个文件,它们 分别是items.py、settings.py、pipelines.py、wuHanMovieSpider.py。
其中 items.py决定爬取哪些项目,wuHanMovieSpider.py决定怎么爬, settings.py决定由谁去处理爬取的内容,pipelines.py决定爬取后的内容怎样处理
0x03 xpath选择器
selector = response.xpath('/html/body/div[@id='homeContentRegion']//text()')[0].extract()
extract() 返回选中内容的Unicode字符串。
关于xpath遍历文档树
| 符号 | 用途 |
|---|---|
| / | 选中文档的根,一般为html |
| // | 选中从当前位置开始所有子孙节点 |
| ./ | 表示从当前节点提取,二次提取数据时会用到 |
| . | 选中当前节点,相对路径 |
| .. | 选中当前节点父节点,相对路径 |
| ELEMENT | 选中子节点中所有ELEMENT元素节点 |
| //ELEMENT | 选中子孙节点所有ELEMENT元素节点 |
| * | 选中所有元素子节点 |
| text() | 选中素有文本子节点 |
| @ATTR | 选中名为ATTR的属性节点 |
| @* | 选中所有属性节点 |
| /@ATTR | 获取节点属值 |
| 方法 | 用途 |
|---|---|
| contains | a[contains(@href,"test")] 查找href属性包含test字符的a标签 |
| start-with | a[start-with(@href,"http")] 查找href属性以http开头的a标签 |
举例
response.xpath('//a/text()') #选取所有a的文本
response.xpath('//div/*/img') #选取div孙节点的所有img
response.xpath('//p[contains(@class,'song')]') #选择class属性中含有‘song’的p元素
response.xpath('//a[contains(@data-pan,'M18_Index_review_short_movieName')]/text()')
response.xpath('//div/a | //div/p') 或者,页面中可能是a可能是p
selector = response.xpath('//a[contains(@href,"http://movie.mtime.com")]/text()').extract()
参考文章
https://www.cnblogs.com/master-song/p/8948210.html
https://blog.csdn.net/loner_fang/article/details/81017202
实例 爬取天气预报
0x01 创建weather项目及基础爬虫
cd Scrapy\code
scrapy startproject weather
scrapy genspider beiJingSpider www.weather.com.cn/weather/101010100.shtml
0x02 修改items.py
class WeatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
cityDate = scrapy.Field() #城市及日期
week = scrapy.Field() #星期
temperature = scrapy.Field() #温度
weather = scrapy.Field() #天气
wind = scrapy.Field() #风力
0x03 scrapy shell
先使用scrapy shell命令来测试获取选择器,主要是看一下网站有没有反爬机制
scrapy shell https://www.tianqi.com/beijing/
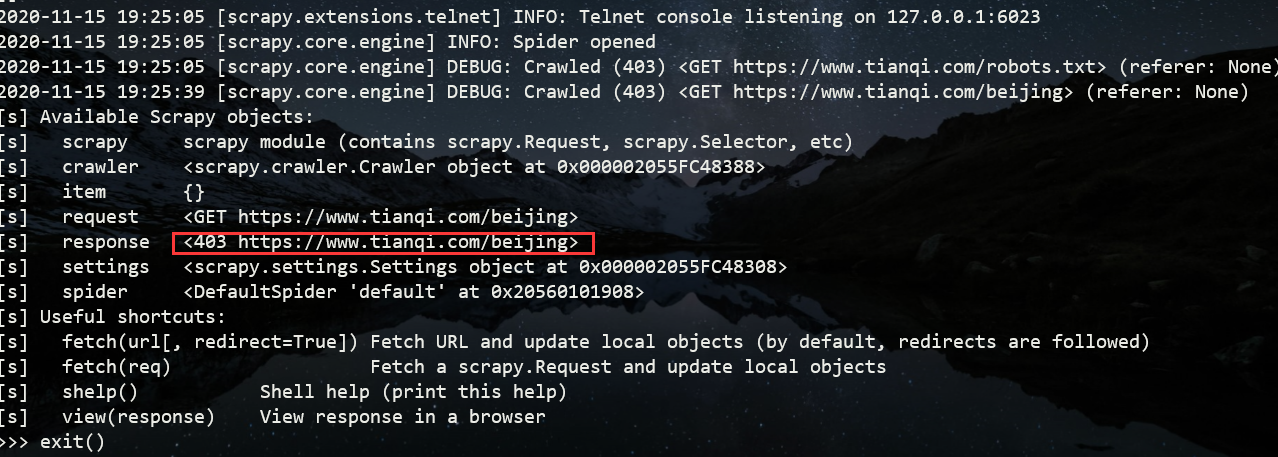
比如403就是禁止读取,而不是页面不存在。
简单的bypass就是添加UA和访问频率
0x04 简单的bypass
先准备一堆User-Agent放到resource.py利用random每次随机选择其中一个即可。
setp1:将准备好的resource.py放在settings.py的同级目录中
resource.py
#-*- coding:utf-8 -*-
UserAgents = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/76.0",
]
step2:修改middlewares.py
导入random,UserAgents,UserAgentMiddleware
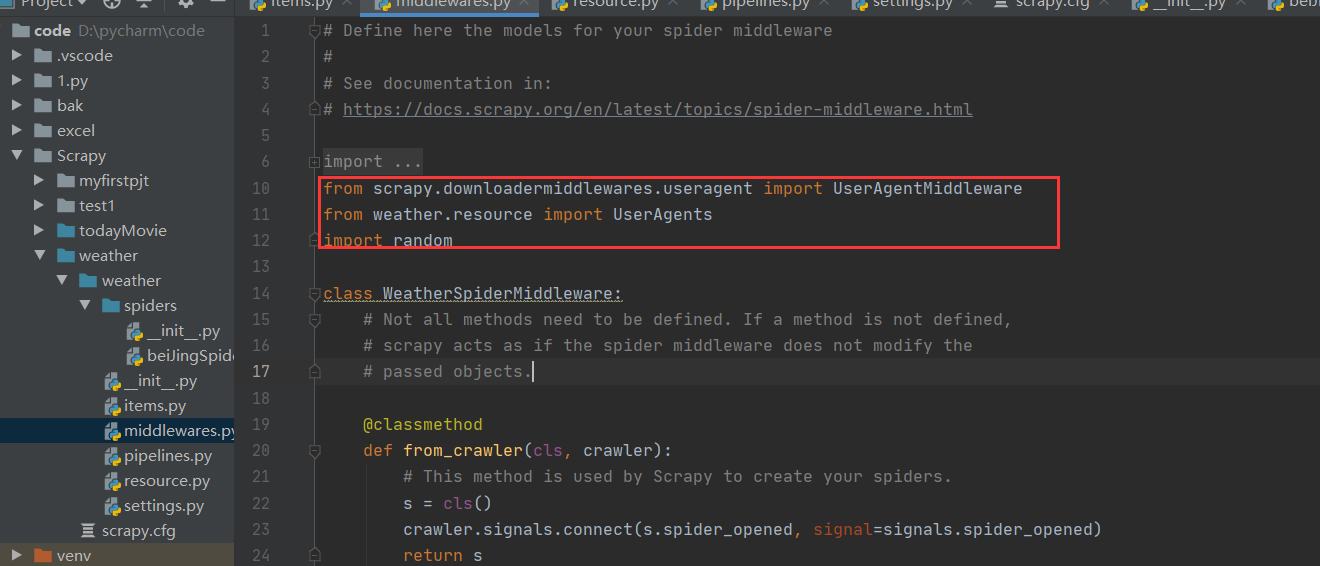
最下面添加一个新类,新类继承于UserAgentMiddleware类
类中大致内容为提供每次请求时随机挑选的UA头
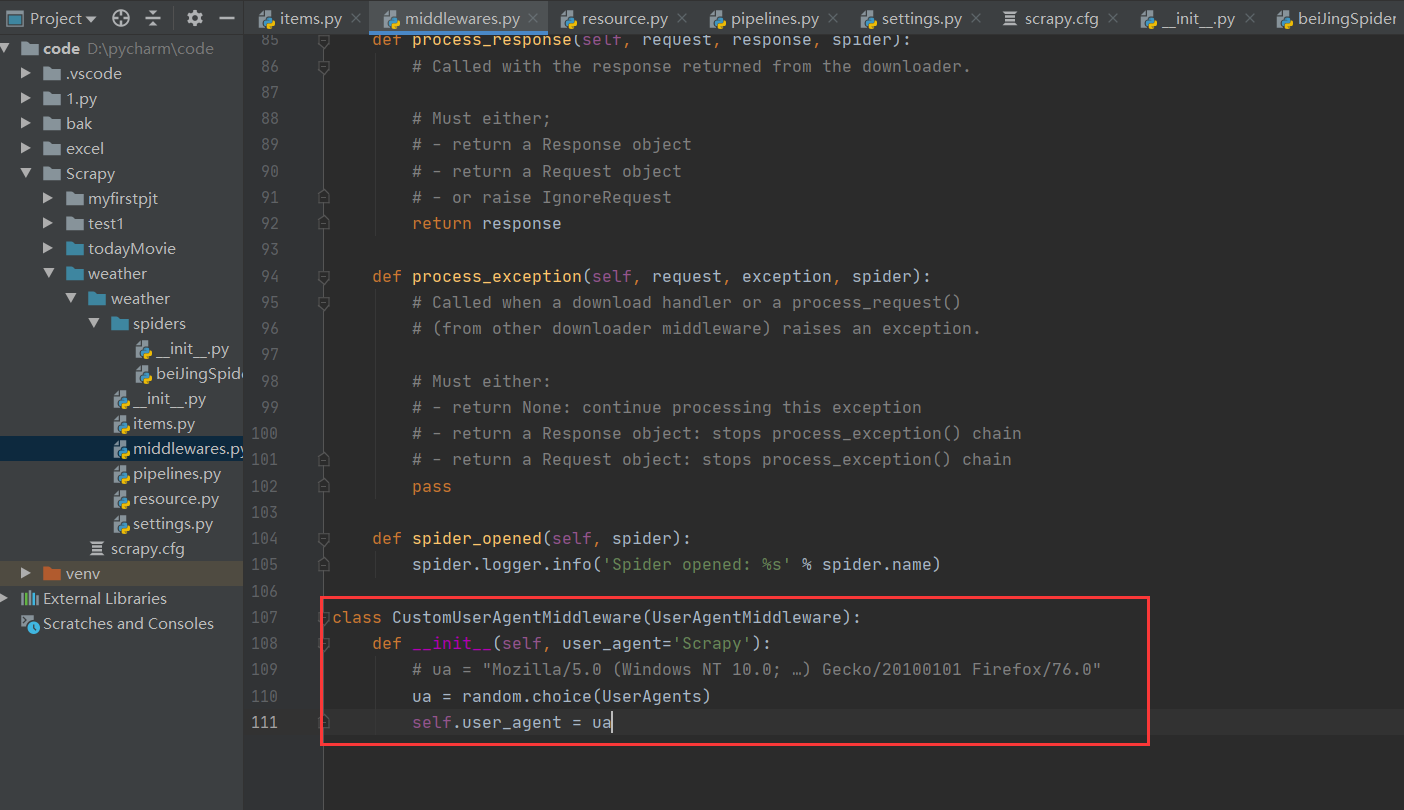
class CustomUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent='Scrapy'):
# ua = "Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/76.0"
ua = random.choice(UserAgents)
self.user_agent = ua
step3:修改settings.py
用CustomUserAgentMiddleware来替代 UserAgentMiddleware。
在settings.py中找到DOWNLOADER_MIDDLEWARES这个选项修改为如下图所示
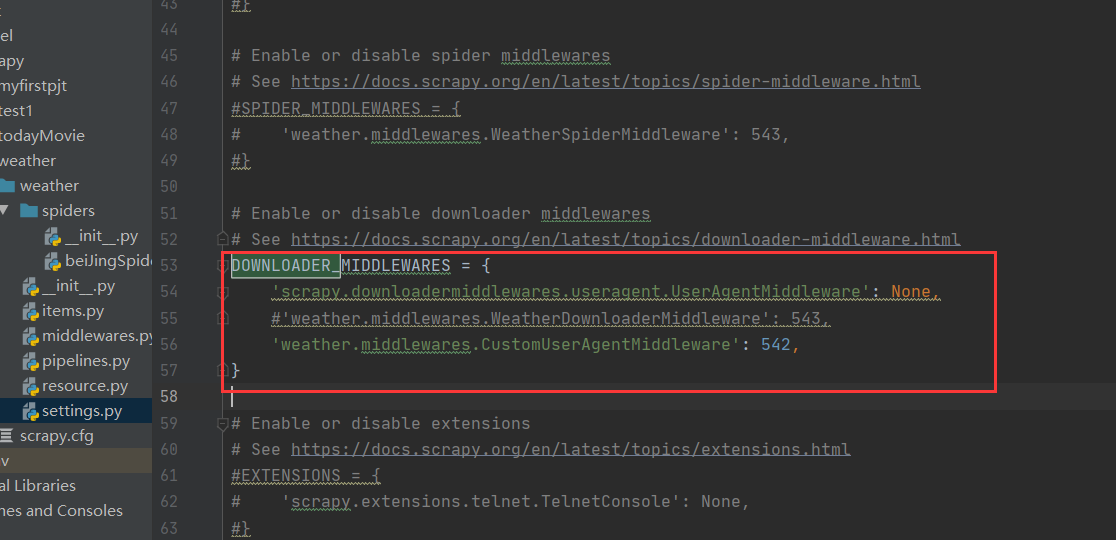
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
#'weather.middlewares.WeatherDownloaderMiddleware': 543,
'weather.middlewares.CustomUserAgentMiddleware': 542,
}
step4:修改请求时间间隔
Scrapy在两次请求之间的时间设置是DOWNLOAD_DELAY,如果不考虑反爬那必然越小越好,值为30就是每隔30s像网站请求一次网页。

ps:一般网站添加UA头即可bypass
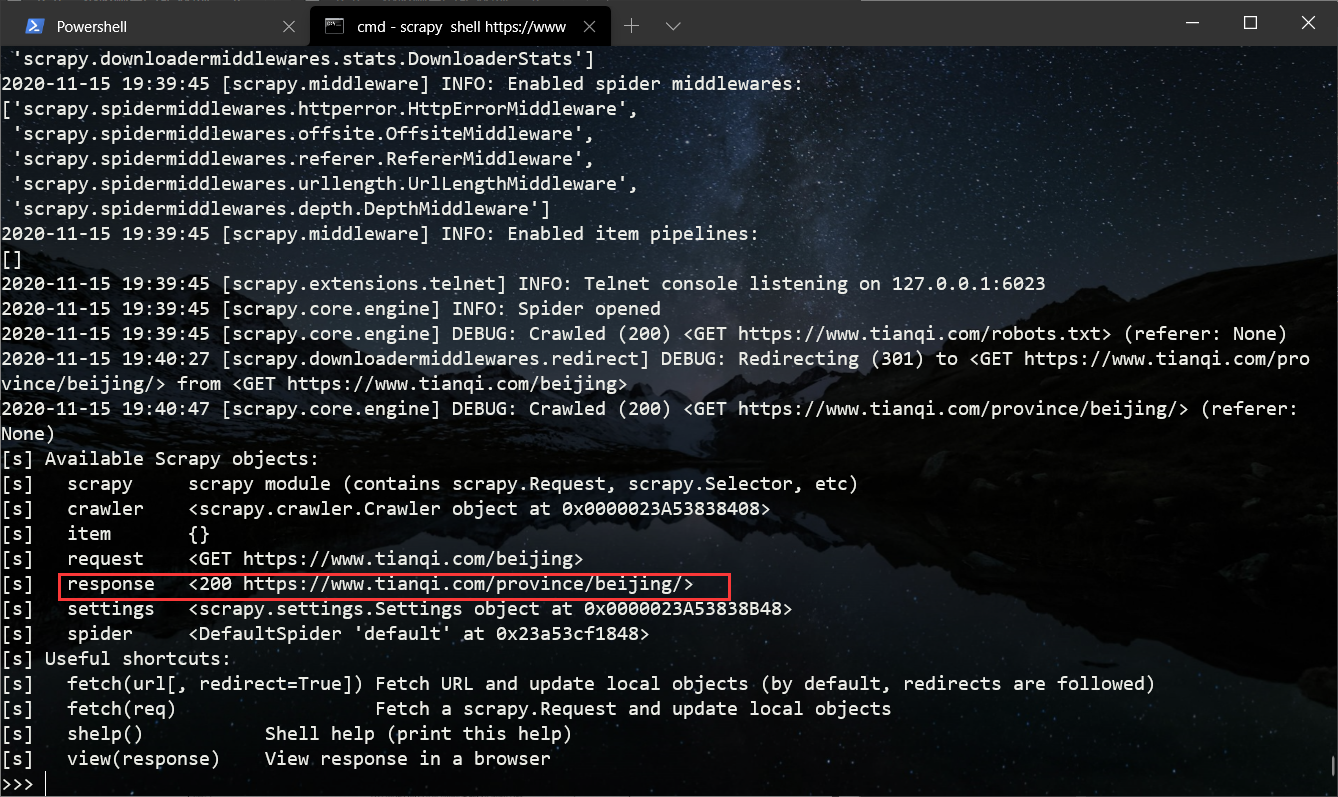
0x05 修改beiJingSpider.py
要获取的内容在class=day7这个div下,在这个div下锚点
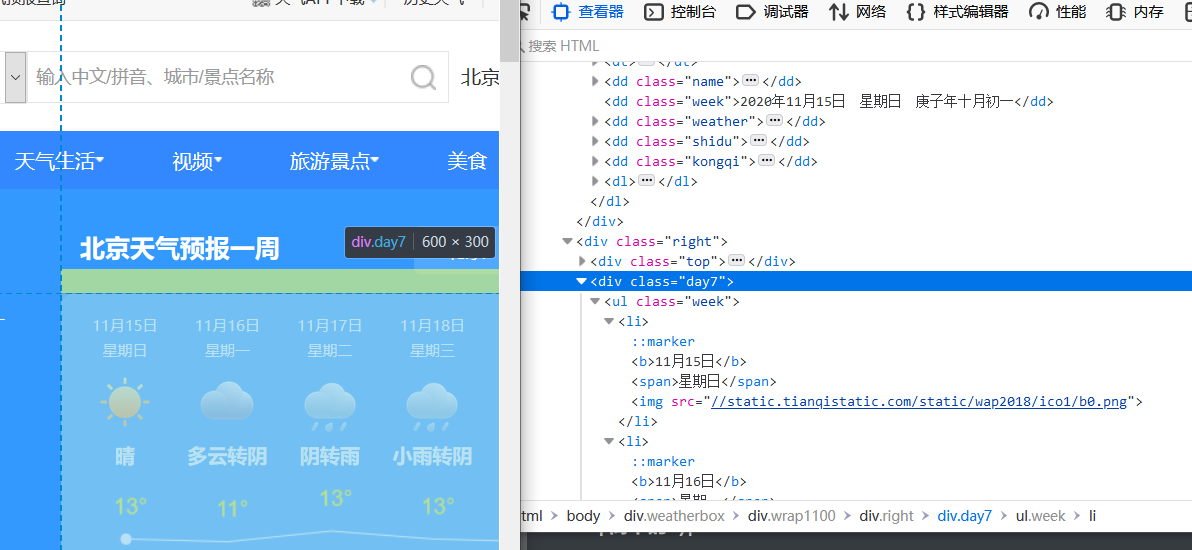
# 注意这里url最后要有/不然获取不到内容
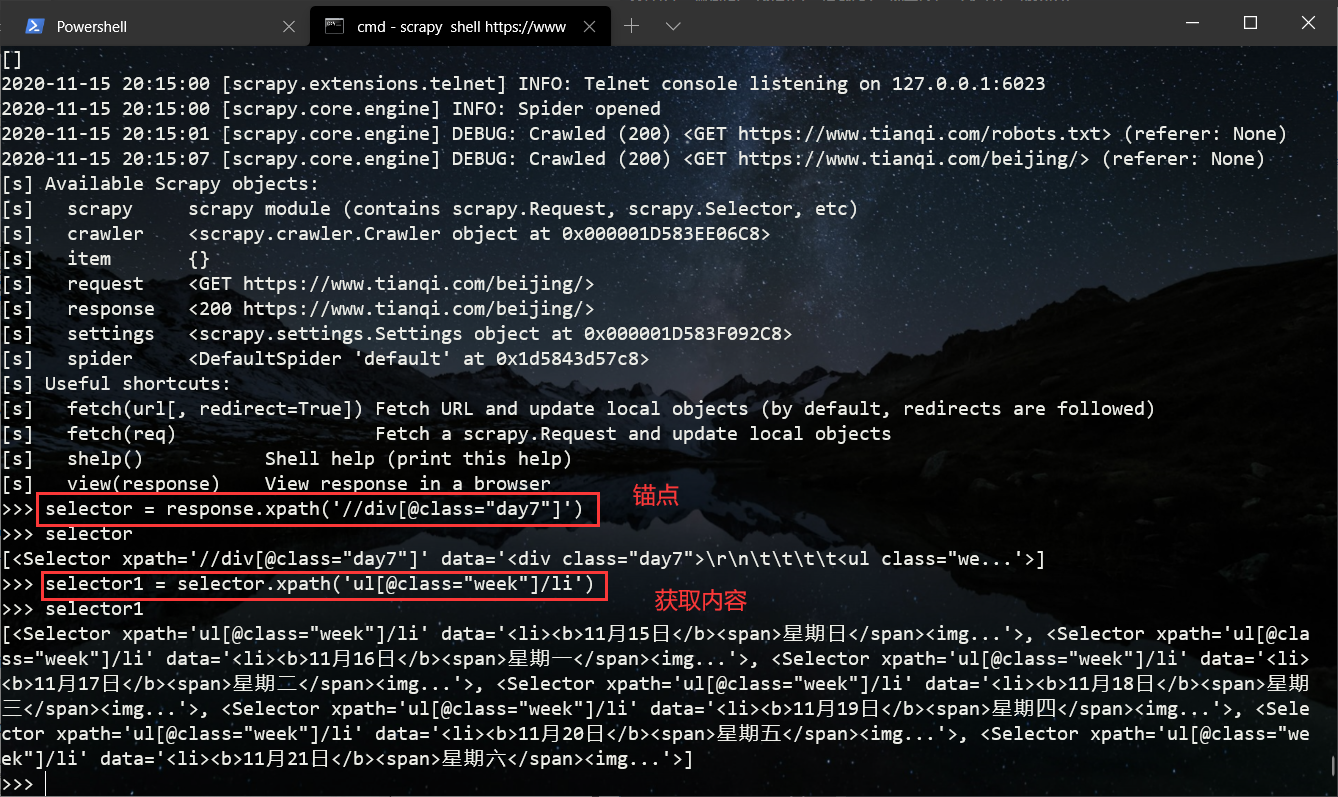
scrapy shell https://tianqi.com/beijing/
selector = response.xpath('//div[@class="day7"]')
selector1 = selector.xpath('ul[@class="week"]/li')
beiJingSpider.py
import scrapy
from weather.items import WeatherItem
class BeijingspiderSpider(scrapy.Spider):
name = 'beiJingSpider'
allowed_domains = ['https://www.tianqi.com/beijing/']
start_urls = ['https://www.tianqi.com/beijing/']
def parse(self, response):
items = []
city = response.xpath('//dd[@class="name"]/h2/text()').extract()
Selector = response.xpath('//div[@class="day7"]')
date = Selector.xpath('ul[@class="week"]/li/b/text()').extract()
week = Selector.xpath('ul[@class="week"]/li/span/text()').extract()
wind = Selector.xpath('ul[@class="txt"]/li/text()').extract()
weather = Selector.xpath('ul[@class="txt txt2"]/li/text()').extract()
temperature1 = Selector.xpath('div[@class="zxt_shuju"]/ul/li/span/text()')
temperature2 = Selector.xpath('div[@class="zxt_shuju"]/ul/li/b/text()').extract()
for i in range(7):
item = WeatherItem()
try:
item['cityDate'] = city + date[i]
item['week'] = week[i]
item['temperature'] = temperature1[i] + ',' + temperature2[i]
item['weather'] = weather[i]
item['wind'] = wind[i]
except IndexError as e:
exit()
items.append(item)
return items
0x06 修改pipelines.py 处理Spider的结果
import time
import codecs
class WeatherPipeline:
def process_item(self, item, spider):
today = timw.strftime('%Y%m%d', time.localtime())
fileName = today + '.txt'
with codecs.open(fileName, 'a', 'utf-8') as fp:
fp.write("%s \t %s \t %s \t %s \r\n"
%(item['cityDate'],
item['week'],
item['temperature'],
item['weather'],
item['wind']))
return item
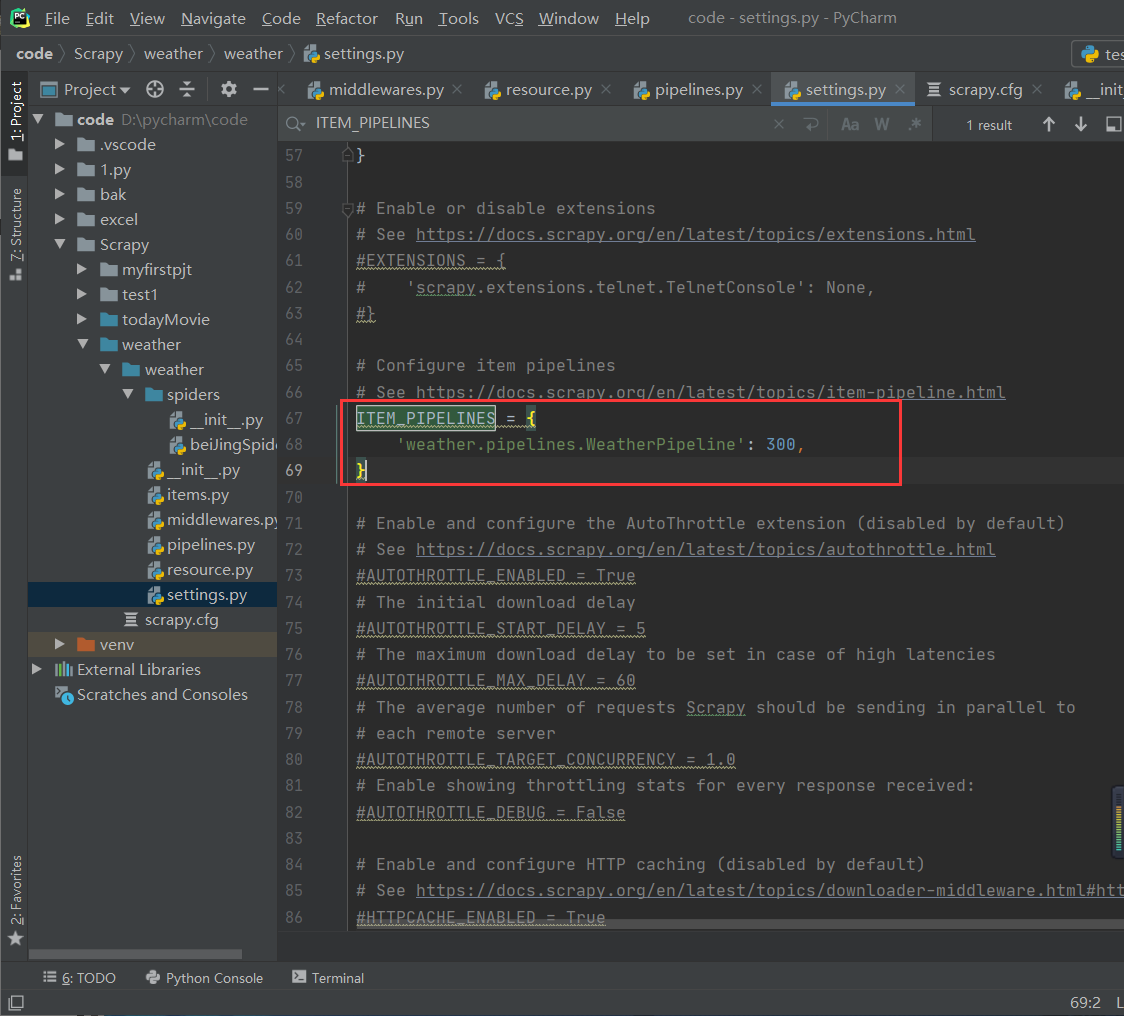
0x07 修改settings.py
找到ITEM_PIPELINES去掉前面的注释
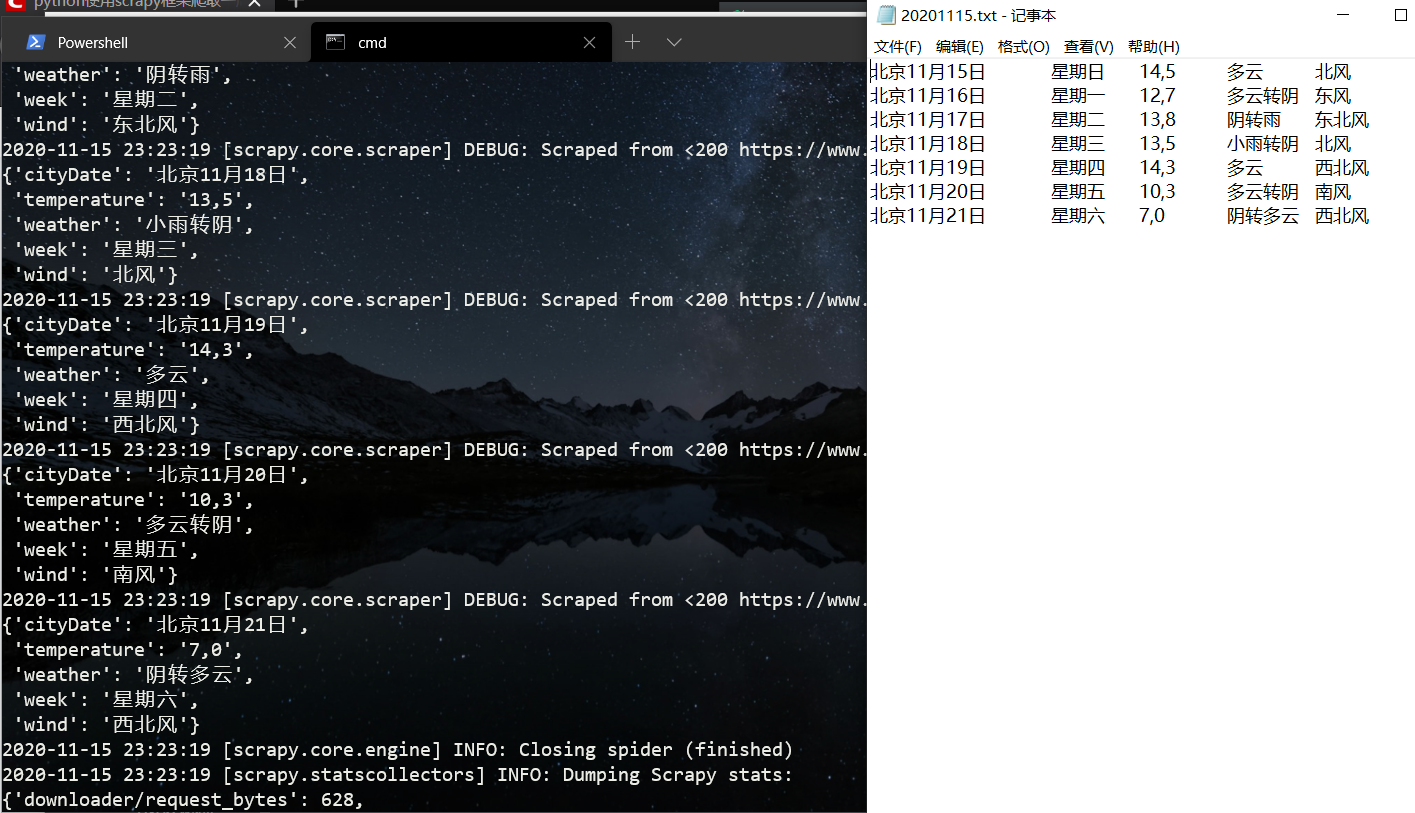
0x08 爬取内容
回到weather项目下执行命令
scrapy crawl beiJingSpider
python-scrapy框架学习的更多相关文章
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- 自己的Scrapy框架学习之路
开始自己的Scrapy 框架学习之路. 一.Scrapy安装介绍 参考网上资料,先进行安装 使用pip来安装Scrapy 在开始菜单打开cmd命令行窗口执行如下命令即可 pip install Scr ...
- 关于Python常用框架学习
我对Python不是特别熟悉,我仅仅只知道它在Web自动化领域挺牛逼的,还有爬虫.当然了,现在的人工智能和机器学习用到它也很多. 记得六月还是七月份的时候,那个时候,突然心血来潮就开始学起了Pytho ...
- scrapy框架学习之路
一.基础学习 - scrapy框架 介绍:大而全的爬虫组件. 安装: - Win: 下载:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted pip3 ...
- python Scrapy 从零开始学习笔记(一)
在之前我做了一个系列的关于 python 爬虫的文章,传送门:https://www.cnblogs.com/weijiutao/p/10735455.html,并写了几个爬取相关网站并提取有效信息的 ...
- [Python][Scrapy 框架] Python3 Scrapy的安装
1.方法(只介绍 pip 方式安装) PS.不清楚 pip(easy_install) 可以百度或留言. cmd命令: (直接可以 pip,而不用跳转到 pip.exe目录下,是因为把所在目录加入 P ...
- Scrapy框架学习 - 使用内置的ImagesPipeline下载图片
需求分析需求:爬取斗鱼主播图片,并下载到本地 思路: 使用Fiddler抓包工具,抓取斗鱼手机APP中的接口使用Scrapy框架的ImagesPipeline实现图片下载ImagesPipeline实 ...
- Scrapy框架学习笔记
1.Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网 ...
- scrapy框架学习
一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- python flask框架学习——开启debug模式
学习自:知了课堂Python Flask框架——全栈开发 1.flask的几种debug模式的方法 # 1.app.run 传参debug=true app.run(debug=True) #2 设置 ...
随机推荐
- PO,VO,BO,POJO,DAO的区别
基本概念 PO:persistant object (持久化对象),可以看成是与数据库中的表相映射的java对象.最简单的PO就是对应数据库中某个表中的一条记录,多个记录可以用PO的集合.PO中应该不 ...
- buu crackRTF
一.无壳,拖入ida,静态编译一下 整体逻辑还是很清晰,这里我的盲区是那个加密函数,是md5,没看出来,内存地址看错了,之前用黑盒动调一下,发现猜不出来,看某位wp发现有的老哥,直接sha1爆破的,狠 ...
- 长按短按控制LED灯-ESP32中断处理
#include <stdio.h> #include <string.h> #include <stdlib.h> #include "freertos ...
- Kubernetes-22:kubelet 驱逐策略详解
为什么要驱逐pod? 在可用计算资源较少时,kubelet为保证节点稳定性,会主动地结束一个或多个pod以回收短缺地资源,这在处理内存和磁盘这种不可压缩资源时,驱逐pod回收资源的策略,显得尤为重要. ...
- [源码解析] 深度学习分布式训练框架 horovod (15) --- 广播 & 通知
[源码解析] 深度学习分布式训练框架 horovod (15) --- 广播 & 通知 目录 [源码解析] 深度学习分布式训练框架 horovod (15) --- 广播 & 通知 0 ...
- python08篇 发邮件和异常处理
一.发邮件 import yamail smtp = yamail.SMTP(host='smtp.qq.com', # 改成自己邮箱的服务器即可,其他的比如smtp.163.com user='65 ...
- PYTHON PIP 快速安装
清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https: ...
- .net core工具组件系列之Redis—— 第一篇:Windows环境配置Redis(5.x以上版本)以及部署为Windows服务
Cygwin工具编译Redis Redis6.x版本是未编译版本(官方很调皮,所以没办法,咱只好帮他们编译一下了),所以咱们先下载一个Cygwin,用它来对Redis进行编译. Cygwin下载地址: ...
- 5Java基础整理
1.API:Application programming interface 举例:System类中的 public static void arraycopy(int[] src,int srcP ...
- Python - 基础数据类型 list 列表
什么是列表 列表是一个有序的序列 列表中所有的元素放在 [ ] 中间,并用逗号分开 一个 列表 可以包含不同类型的元素,但通常使用时各个元素类型相同 特征 占用空间小,浪费内存空间少 声明列表变量 列 ...