kafka之一:kafka简介
现在从事java开发的同学,不论是在面试过程中还是在日常的工作中,肯定会碰到消息队列的情况,市面上消息队列有很多:kafka、rocketMQ、rabbitMQ、zeroMQ等,从本篇博客起计划分享一些kafka方面的知识。
消息队列基础知识
所谓消息队列很好理解,把它拆开来看就是消息和队列,消息这里不是一般意义上的消息,这里是广义的,你可以理解为一个个的订单信息、学生信息、一个个的短信等;队列就很好理解了,学过计算机的人都知道就是一个先进先出的线性数据结构。好了,理解了消息队列下面看下消息队列的其他内容。
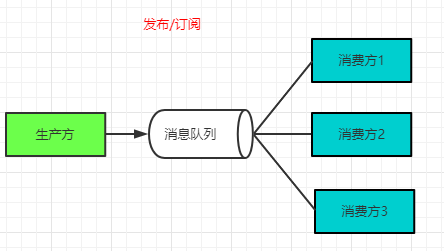
一个消息队列应该包含三部分,分别是生成方、消息队列、消费方,

推/拉模型
何为推/拉模型,这是对于消费方来说的,上面的图细心的读者会发现在“消息队列”和“消费方”之间我用的是不带箭头的实线。消息队列把消息推给消费方称为推模型,消费方主动去消息队列拉取消息称为拉模型。
推/拉模型的优缺点,推模型的话就是无法考虑到消费方的消费能力,有可能消费方消费不过来,造成消息丢失;拉模型消费方主动拉取消息,可以控制消费的速度,但是要主要消息队列中消息的积压问题。
点对点/发布订阅模式
这里说的是生成方和消费方的关系,点对点即一个生成方有一个消费方,所有的消息均有该消费方自己消费;发布订阅讲的是一个生成方有多个消费方,每个订阅了该消息队列的消费方都可以消费到生成方的全部消息。

使用消息队列的优点
在系统中引入消息队列的好处有很多,总的来说有下面三点
- 异步,这里把生产方和消费方看成是两个系统,两个系统间存在调用关系,加入消息队列后,之前的同步调用关系变成了异步调用,可以减少系统的等待时间;
- 削峰,在高并发、大流量系统中,可以把要处理的消息放到队列中,慢慢去消费,不至于把系统打死;
- 解耦,把对消息的业务处理放在同一个系统中,会造成系统的庞大,增加维护难度,引入消息队列,拆成多个系统可以做到系统间的解耦;
使用消息队列的缺点
上面说了那么多优点,消息队列就没有缺点了吗
- 增加系统复杂度,由于引入了消息队列,必然造成系统间调用的复杂;服务调用链增长;排查问题难度加大;
- 增加维护成本,消息队列使系统解耦的同时,带来了维护的成本,要维护多个项目,而且要熟悉服务间的调用关系;
上面对消息队列大体有了一个了解,下面看kafka.
kafka初始
引用官网上的一句话,kafka是一个分布式流处理平台。说到分布式,自然想到分布式系统中的CAP理论,以及副本等概念,这里仅仅提下这些概念。对于kafka的简介,这里看官网未免不是更好的选择,

作为一款消息队列,kafka使用发布订阅模式,采取拉模型消费消息。
kafka概念
对kafka有了一定的了解后,看下其中的一些概念
broker
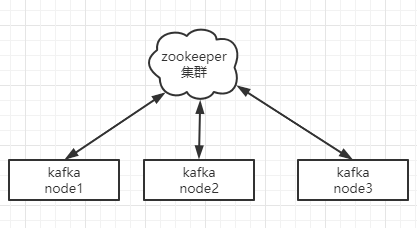
kafka是一个分布式的系统意味着是多节点的,在这个系统中的每个节点就称为一个broker。
leader
上面说到每个节点都是一个broker,在分布式系统中必须要有一个主节点,来处理和管理其他节点,那么由zookeeper从多个broker中选举出来的主节点称为leader
follower
除了leader之外的broker称为follower
topic
topic叫做数据主题相当于生产方发送消息的目的地,消费方消费消息的数据源。消息通过topic进行存储。
分区(partition)
分区是最终存放消息地方,分区属于topic,一个topic可以有多个分区。一个消息进入到topic后,由topic决定消息存放在哪个分区,一般是通过轮询的方式决定消息的存放分区,在一个分区内消息是有序的。消息落到分区后会有分配一个唯一消息id,此id称为offset。
副本(replication)
分布式系统为了保证系统的可用性,往往要把保存的数据存多个副本,也就是同样的数据存多份。
消费者群组
一个topic可以有多个消费者,那么所有的消费者可以接受到topic中的全部消息,为了提高消费者的处理能力,在消费者中使用多线程共同消费消息不是更好,消费者群组就是这样一个概念,多个消费者组成一个群组共同去消费topic。消费者群组中的消费线程(或者服务)根据分区去消费消息。
offset
offset翻译过来叫偏移量,在消费端会记录当前这个时刻消费的消息id,这个id就是offset。在消费过程中重置该offset,可以消费之前的消息(重复消费)或者跳过某些消息从最新的开始消费。
kafka架构
kafka是分布式集群架构,使用zookeeper作为管理组件,协调集群中每个节点的关系,也就是选举leader,管理topic和partition。
简单介绍了消息队列和kafka的基本概念,下面准备开始kafka的安装及使用,敬请关注。
推荐一个kafka的中文网站:https://kafka.apachecn.org/

kafka之一:kafka简介的更多相关文章
- Kafka记录-Kafka简介与单机部署测试
1.Kafka简介 kafka-分布式发布-订阅消息系统,开发语言-Scala,协议-仿AMQP,不支持事务,支持集群,支持负载均衡,支持zk动态扩容 2.Kafka的架构组件 1.话题(Topic) ...
- [转帖]kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建 http://www.aboutyun.com/thread-9341-1-1.html 还没看完 感觉挺好的. 问题导读: 1.zook ...
- Kafka 探险 - 架构简介
Kafka 探险 - 架构简介 这个 Kafka 的专题,我会从系统整体架构,设计到代码落地.和大家一起杠源码,学技巧,涨知识.希望大家持续关注一起见证成长! 我相信:技术的道路,十年如一日!十年磨一 ...
- CentOS 7部署Kafka和Kafka集群
CentOS 7部署Kafka和Kafka集群 注意事项 需要启动多个shell脚本交互客户端进行验证,运行中的客户端不要停止. 准备工作: 安装java并设置java环境变量,在`/etc/prof ...
- Kafka(3)--kafka消息的存储及Partition副本原理
消息的存储原理: 消息的文件存储机制: 前面我们知道了一个 topic 的多个 partition 在物理磁盘上的保存路径,那么我们再来分析日志的存储方式.通过 [root@localhost ~]# ...
- Apache Kafka安全| Kafka的需求和组成部分
1.目标 - 卡夫卡安全 今天,在这个Kafka教程中,我们将看到Apache Kafka Security 的概念 .Kafka Security教程包括我们需要安全性的原因,详细介绍加密.有了这 ...
- kafka - Confluent.Kafka
上个章节我们讲了kafka的环境安装(这里),现在主要来了解下Kafka使用,基于.net实现kafka的消息队列应用,本文用的是Confluent.Kafka,版本0.11.6 1.安装: 在NuG ...
- kafka实战教程(python操作kafka),kafka配置文件详解
kafka实战教程(python操作kafka),kafka配置文件详解 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是 ...
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建(转)
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行"随机读写"的原因是什么? 3.kafka集群consumer和producer状 ...
- Kafka官方文档翻译——简介
简介 Kafka擅长于做什么? 它被用于两大类应用: 在应用间构建实时的数据流通道 构建传输或处理数据流的实时流式应用 几个概念: Kafka以集群模式运行在1或多台服务器上 Kafka以topics ...
随机推荐
- C语言-字符串函数的实现(二)之strcpy
C语言中的字符串函数有如下这些 获取字符串长度 strlen 长度不受限制的字符串函数 strcpy strcat strcmp 长度受限制的字符串函数 strncpy strncat strncmp ...
- JDBC_14_使用JDBC工具类实现模糊查询
使用JDBC工具类实现模糊查询 代码: import java.sql.*; /** * 模糊查询 * 测试DBUtils */ public class JDBCTest09 { public st ...
- Day05_21_Constructor构造器
Constructor 构造器 构造方法(构造函数,构造器) 构造方法又被称为 构造函数/构造器/Constructor 构造方法的语法结构: [修饰符列表] 构造方法名 (形式参数列表){ 构造方法 ...
- 支持移远EC600S的SmartDtu平台,基于QuecPython
前言 本文的主要目的是说明青石SmartDtu到底做了哪些工作?我们在移远硬件平台EC600S上做了哪些支持?为什么说这套平台是硬件开发者的福音?我们的初衷是解放广大硬件开发者的双手,提供一套成熟的嵌 ...
- POJ1149 PIGS(最大流)
题意: 有一个人,他有m个猪圈,每个猪圈里面有一定数量的猪,但是每个猪圈的门都是锁着的,他自己没有钥匙,只有顾客有钥匙,一天依次来了n个顾客,(记住是依次来的)他们每个人都有一些钥匙,和他 ...
- 【python】Leetcode每日一题-螺旋矩阵2
[python]Leetcode每日一题-螺旋矩阵2 [题目描述] 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix . ...
- CentOS运行多个Tomcat操作步骤
一:修改环境变量 在/et/profile文件追加以下内容 # tomcat1 env ( 第一个tomcat 的环境变量) export CATALINA_HOME=/usr/local/apach ...
- Linux下查看在线用户及用户进程
#该服务器下的所有用户运行进程的情况 ps -ax -u #查看java程序下用户的进程情况 ps -ax -u |grep java 或 ps aux|grep java cat /etc/p ...
- SQL必知必会 —— 性能优化篇
数据库调优概述 数据库中的存储结构是怎样的 在数据库中,不论读一行,还是读多行,都是将这些行所在的页进行加载.也就是说,数据库管理存储空间的基本单位是页(Page). 一个页中可以存储多个行记录(Ro ...
- github图文入门教程
目录 1.注册,安装git 2.初始化git 3.git本地仓库结构 4.初始化第一个git仓库 5.远程仓库的修改 6.总结 1.注册,安装git ①.注册一个github账号 并建立一个仓库 ②. ...