Yarn 集群环境 HA 搭建
环境准备
确保主机搭建 HDFS HA 运行环境
步骤一:修改 mapred-site.xml 配置文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop/
[root@node-01 hadoop]# vim mapred-site.xml
<configuration>
<!-- 配置MapReduce程序运行模式 为 yarn(不配置默认为 local 模式) -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 设置 hadoop 路径 -->
<property>
<name>mapreduce.application.classpath</name>
<value>/root/apps/hadoop-3.2.1/etc/hadoop:/root/apps/hadoop-3.2.1/share/hadoop/common/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/common/*:/root/apps/hadoop-3.2.1/share/hadoop/hdfs:/root/apps/hadoop-3.2.1/share/hadoop/hdfs/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/hdfs/*:/root/apps/hadoop-3.2.1/share/hadoop/mapreduce/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/mapreduce/*:/root/apps/hadoop-3.2.1/share/hadoop/yarn:/root/apps/hadoop-3.2.1/share/hadoop/yarn/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/yarn/*</value>
</property>
</configuration>
步骤二:修改yarn-env.sh 配置文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop
[root@node-01 hadoop]# echo 'export JAVA_HOME=${JAVA_HOME}' >> yarn-env.sh
步骤三:修改 yarn-site.xml 配置文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop/
[root@node-01 hadoop]# vim yarn-site.xml
<configuration>
<!-- 配置 NodeManager上运行的附属服务(指定 MapReduce 中 reduce 读取数据方式) -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置 yarn 集群标识 id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarncluster</value>
</property>
<!-- 启用 yarn HA(高可用) -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 配置 resourcemanager 逻辑 ids 名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置 resourcemanager1 启动主机名-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node-01</value>
</property>
<!-- 配置 resourcemanager2 启动主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node-02</value>
</property>
<!-- 配置 resourcemanager1 web 浏览器地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node-01:8088</value>
</property>
<!-- 配置 resourcemanager2 web 浏览器地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node-02:8088</value>
</property>
<!--配置 zk 集群地址-->
<property>
<name>hadoop.zk.address</name>
<value>node-01:2181,node-02:2181,node-03:2181</value>
</property>
<!-- 启用 resourcemanager 重启自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 有三种StateStore,分别是基于 zookeeper, HDFS, leveldb, HA 高可用集群必须用 ZKRMStateStore -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置自动检测硬件(默认关闭) -->
<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>
<!-- 配置 nodemanager 启动要求的最低配置-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
步骤四:scp 这个 yarn-site.xml 到其他节点
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop/
[root@node-01 ~]# scp mapred-site.xml node-02:$PWD
[root@node-01 ~]# scp mapred-site.xml node-03:$PWD
[root@node-01 ~]# scp yarn-env.sh node-02:$PWD
[root@node-01 ~]# scp yarn-env.sh node-03:$PWD
[root@node-01 ~]# scp yarn-site.xml node-02:$PWD
[root@node-01 ~]# scp yarn-site.xml node-03:$PWD
步骤五:启动 yarn 集群
[root@node-01 ~]# start-yarn.sh
stop-yarn.sh :停止 yarn 集群
步骤六:用 jps 检查 yarn 的进程
[root@node-01 ~]# jps
16800 ResourceManager
12050 NameNode
11878 JournalNode
12362 DFSZKFailoverController
11739 QuorumPeerMain
16941 NodeManager
12174 DataNode
[root@node-02 ~]# jps
11616 JournalNode
13492 ResourceManager
11926 DataNode
11803 NameNode
11452 QuorumPeerMain
12046 DFSZKFailoverController
# 手动启动 node-02 和 node-03 nodemanger 进程
[root@node-02 ~]# yarn --daemon start nodemanager
[root@node-03 ~]# yarn --daemon start nodemanager
yarn --daemon stop nodemanager 停止nodemanger进程
步骤七:用 web 浏览器查看 yarn 的网页
node-01:http://192.168.229.21:8088/cluster/cluster
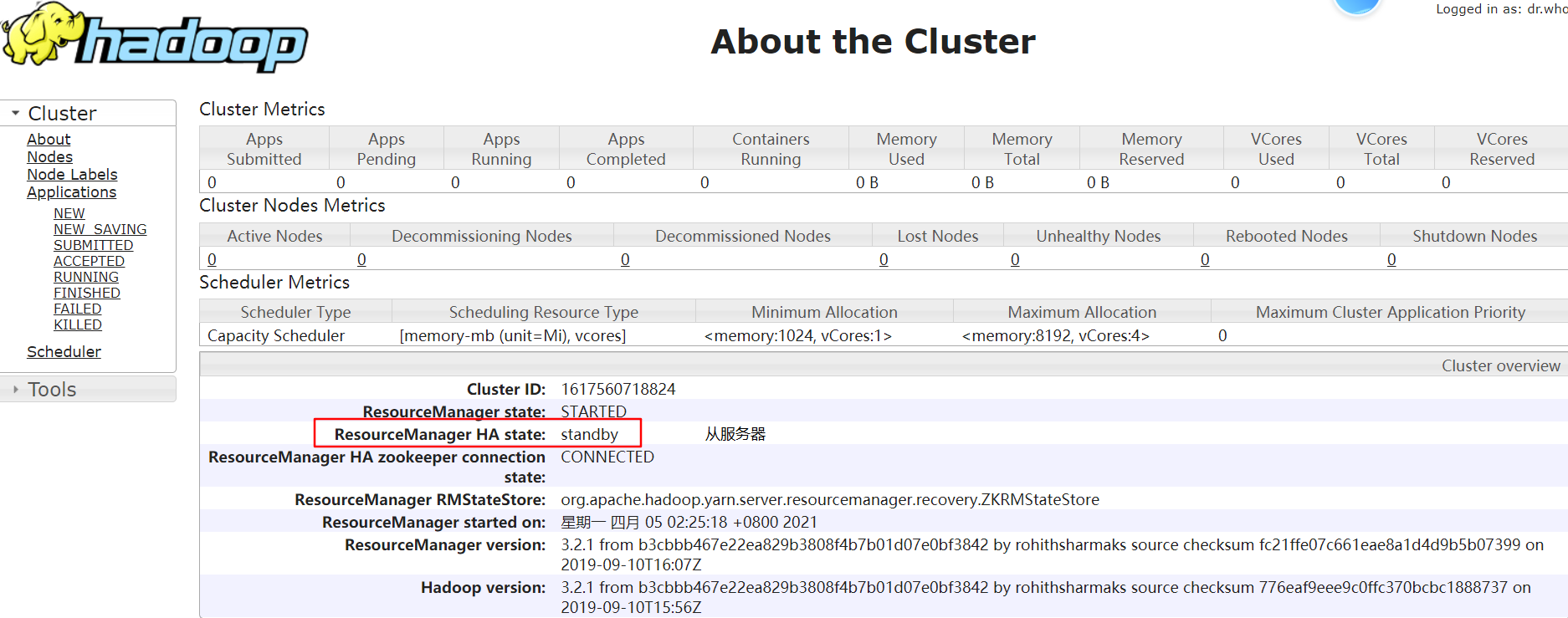
node-02:http://192.168.229.22:8088/cluster/cluster
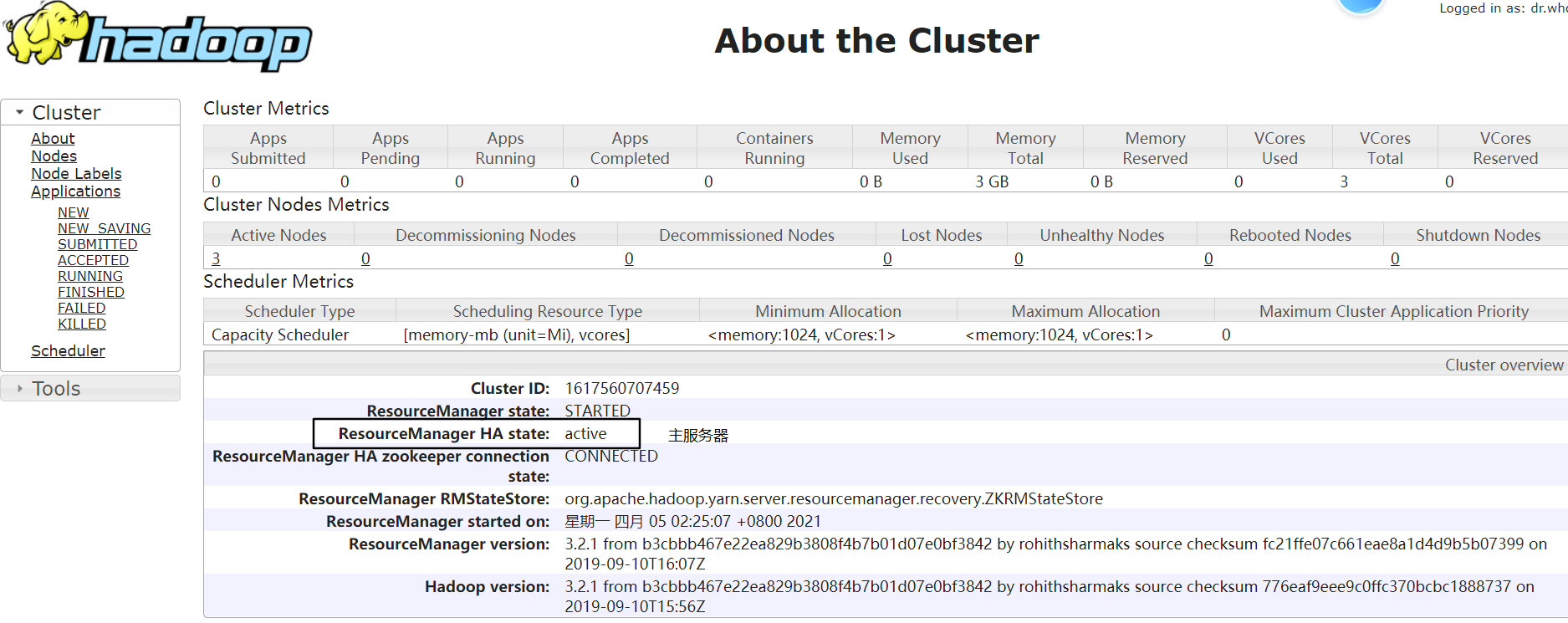
步骤八:测试 ResourceManager 故障转移
# node-02 上关闭 resourcemanager 进程
[root@node-02 logs]# yarn --daemon stop resourcemanager
查看 node-01:http://192.168.229.21:8088/cluster/cluster,发现状态由 standby 变为 active,说明已经进行故障转移
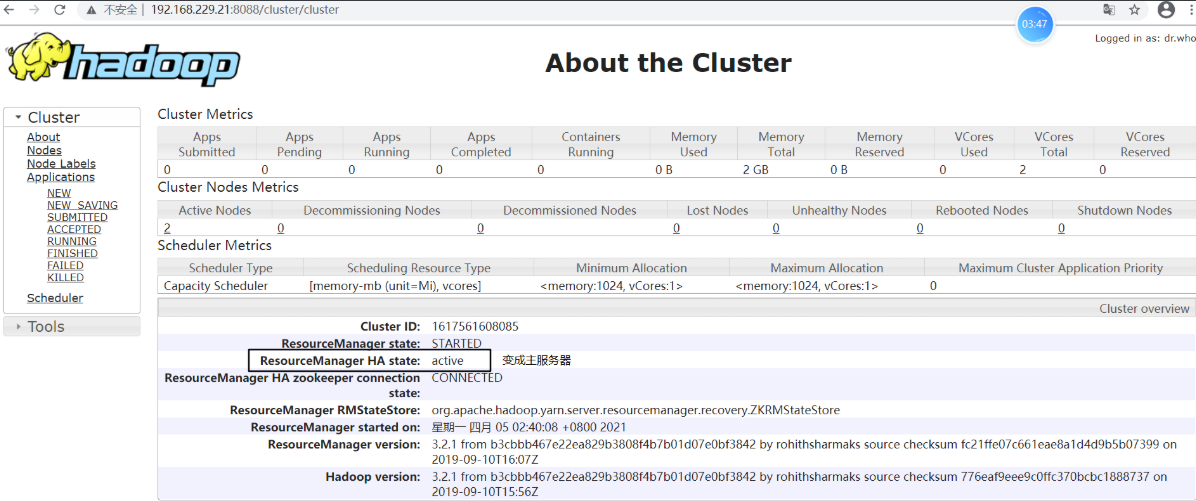
将 node-02 上 resourcemanager 进程再次启动
[root@node-02 logs]# yarn --daemon start resourcemanager
这时,node-02 上的 resourcemanager 则变为 standby 状态,故障转移测试完成:)
步骤九:测试 Yarn 集群运行 wordcount 程序
将 wordcount 程序进行 Jar 打包并上传,执行 wordcount 程序
执行 MapReduce 程序命令格式:hadoop jar xxxx.jar 类全名(main 方法的类名和包名)
[root@node-01 ~]# ll
总用量 138368
drwxr-xr-x. 5 root root 69 4月 4 23:36 apps
-rw-r--r--. 1 root root 6870038 4月 8 13:12 MapReduceDemo-1.0-SNAPSHOT.jar
[root@node-01 hadoop]# hadoop jar MapReduceDemo-1.0-SNAPSHOT.jar wordcount.JobSubmitterLinuxToYarn
2021-04-08 20:00:17,739 INFO mapreduce.Job: Job job_1617883180833_0001 completed successfully #表示 Job 执行成功
Yarn 集群环境 HA 搭建的更多相关文章
- Linux下Hadoop2.7.3集群环境的搭建
Linux下Hadoop2.7.3集群环境的搭建 本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 基础环境 JDK的安 ...
- hadoop集群环境的搭建
hadoop集群环境的搭建 今天终于把hadoop集群环境给搭建起来了,能够运行单词统计的示例程序了. 集群信息如下: 主机名 Hadoop角色 Hadoop jps命令结果 Hadoop用户 Had ...
- Nacos集群环境的搭建与配置
Nacos集群环境的搭建与配置 集群搭建 一.环境: 服务器环境:CENTOS-7.4-64位 三台服务器IP:192.168.102.57:8848,192.168.102.59:8848,192. ...
- redis集群环境的搭建和错误分析
redis集群环境的搭建和错误分析 redis集群时,出现的几个异常问题 09 redis集群的搭建 以及遇到的问题
- ElasticSearch 5.2.2 集群环境的搭建
在之前 ElasticSearch 搭建好之后,我们通过 elasticsearch-header 插件在查看 ES 服务的时候,发现 cluster-health 显示的是 YELLOW. Why? ...
- zookeeper3台机器集群环境的搭建
三台机器zookeeper的集群环境搭建 Zookeeper 集群搭建指的是 ZooKeeper 分布式模式安装. 通常由 2n+1台 servers 组成. 这是因为为了保证 Leader 选举(基 ...
- 基于原生态Hadoop2.6 HA集群环境的搭建
hadoop2.6 HA平台搭建 一.条件准备 软件条件: Ubuntu14.04 64位操作系统, jdk1.7 64位,Hadoop 2.6.0, zookeeper 3.4.6 硬件条件 ...
- Linux下Hadoop2.6.0集群环境的搭建
本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 基础环境 JDK的安装与配置 现在直接到Oracle官网(http:/ ...
- Linux下Hadoop2.7.1集群环境的搭建(超详细版)
本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 一.基础环境 ...
随机推荐
- editorconfig、eslint、prettier三者的区别、介绍及使用
每次搭建新项目都少不了这些工具,但时间一久就忘记了,下次搭新项目时又要四处查官方文档,因此特此记录,主要内容是对这三个工具的理解,以及具体使用方式 editorconfig 理解 先看官网的定义: E ...
- 实现Web请求后端Api的Demo,实现是通过JQuery的AJAX实现后端请求,以及对请求到的数据的解析处理,实现登录功能
本篇实现Web请求后端Api的Demo,实现是通过JQuery的AJAX实现后端请求,以及对请求到的数据的解析处理,实现登录功能需求描述:1. 请求后端Api接口地址2. 根据返回信息进行判断处理前端 ...
- SpringBoot中的自动代码生成 - 基于Mybatis-Plus
作者:汤圆 个人博客:javalover.cc 前言 大家好啊,我是汤圆,今天给大家带来的是<SpringBoot中的自动代码生成 - 基于Mybatis-Plus>,希望对大家有帮助,谢 ...
- SpringIOE-以xml方式实现
SpringIOC框架简单实现 简单介绍 依赖注入( Dependency Injection ,简称 DI) 与控制反转 (IoC) 的含义相同,只不过这两个称呼是从两个角度描述的同一个概念,具体如 ...
- 浅谈程序设计和C语言
学前必备知识 程序:一组计算机能识别和执行的指令. 计算机语言:计算机工作基于二进制,计算机只能识别和接受由0和1组成的指令. 计算机能直接识别和接受的二进制代码称为机器指令.机器指令的集合就是该计算 ...
- 从苏宁电器到卡巴斯基(后传)第03篇:我与鱼C论坛的是是非非
前言与铺垫 当我刚读研一的时候,对自己的未来还是非常迷茫的.尽管我读的是数字媒体技术专业,但是我对这一行根本就不感兴趣,对于平面设计.三维建模以及游戏引擎的使用这一类知识根本就不会,也不太想学(由于我 ...
- Linux中grep工具的使用
Grep grep(Globel Search Regular Expression and Printing out the line)全面搜索正则表达式并把行打印出来,是一种强大的文本搜索工具,是 ...
- xposed结合Zygote分析
android中zygote相信大家都很熟悉,它执行的函数是app_main.cpp,而xposed主要实现的就是替换app_main.cpp.所以在分析xposed时有必要来认识下zygote.好了 ...
- C#-Socket(TCP)
//提示,线程里面不要给控件赋值 LinkSocket.Send(result, length, 0); 自己挂起 private void button1_Click(object sender, ...
- WinDBG 调试命令大全
转载收藏于:http://www.cnblogs.com/kekec/archive/2012/12/02/2798020.html #调试命令窗口 ++++++++++++++++++++++++ ...