MapReduce06 MapReduce工作机制
5 MapReduce工作机制(重点)
5.1 MapTask工作机制
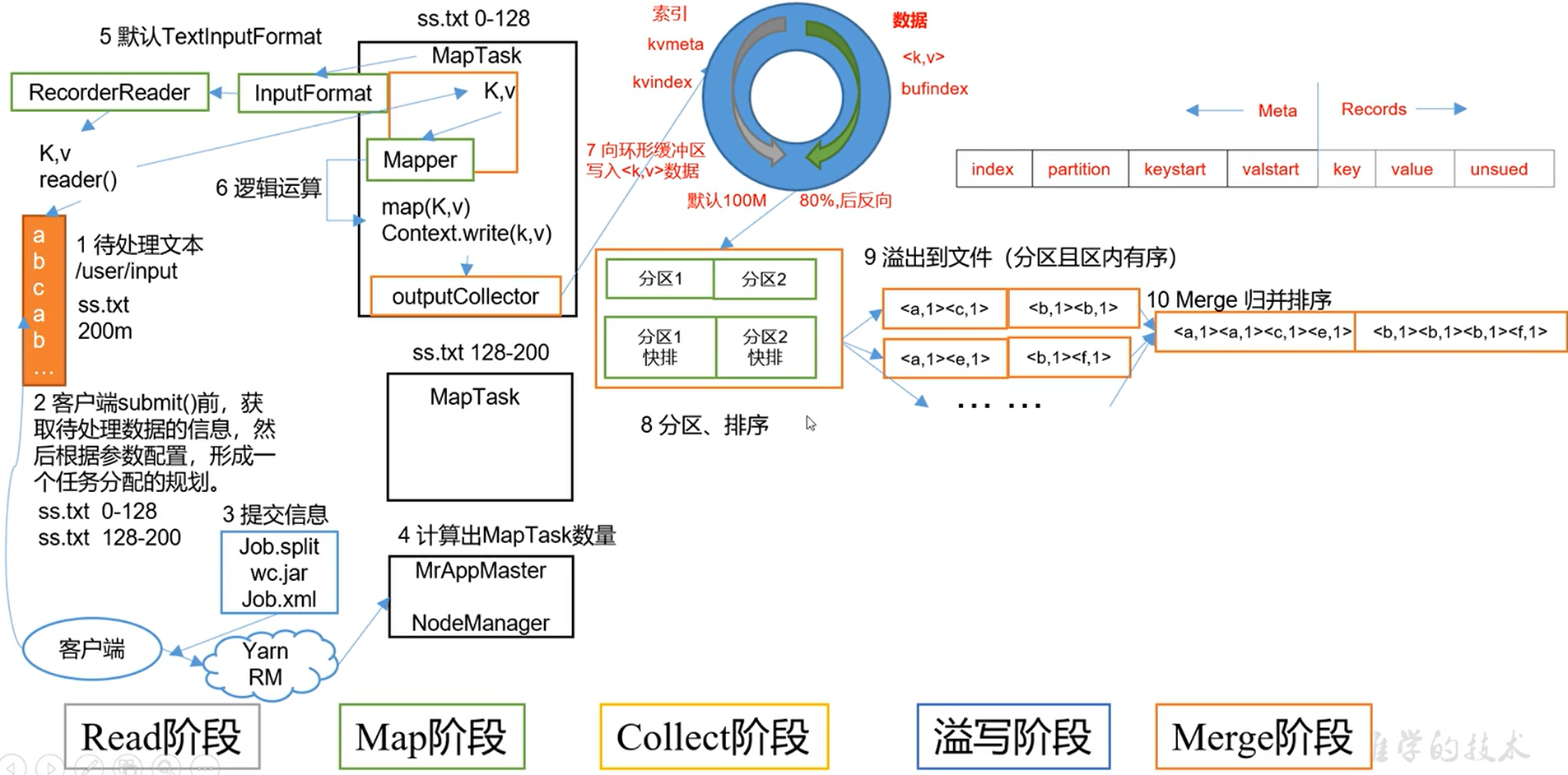
Read阶段
主要是Job的提交流程
1.切片划分
2.提交给Yarn
Job.split 切片信息
wc.jar 集群模式会提交,本地模式不会提交
Job.xml 配置信息
3.Yarn开启NodeManager(单个节点服务器资源老大) AppMaster(单个任务运行的老大) AppMaster开启对应的MapTask进入Map阶段
4.由InputFormat读取数据,默认TextInputFormat,读完之后返回给map,进入用户自己写的Mapper。一个MapTask产生一个文件
5.2 ReduceTask工作机制
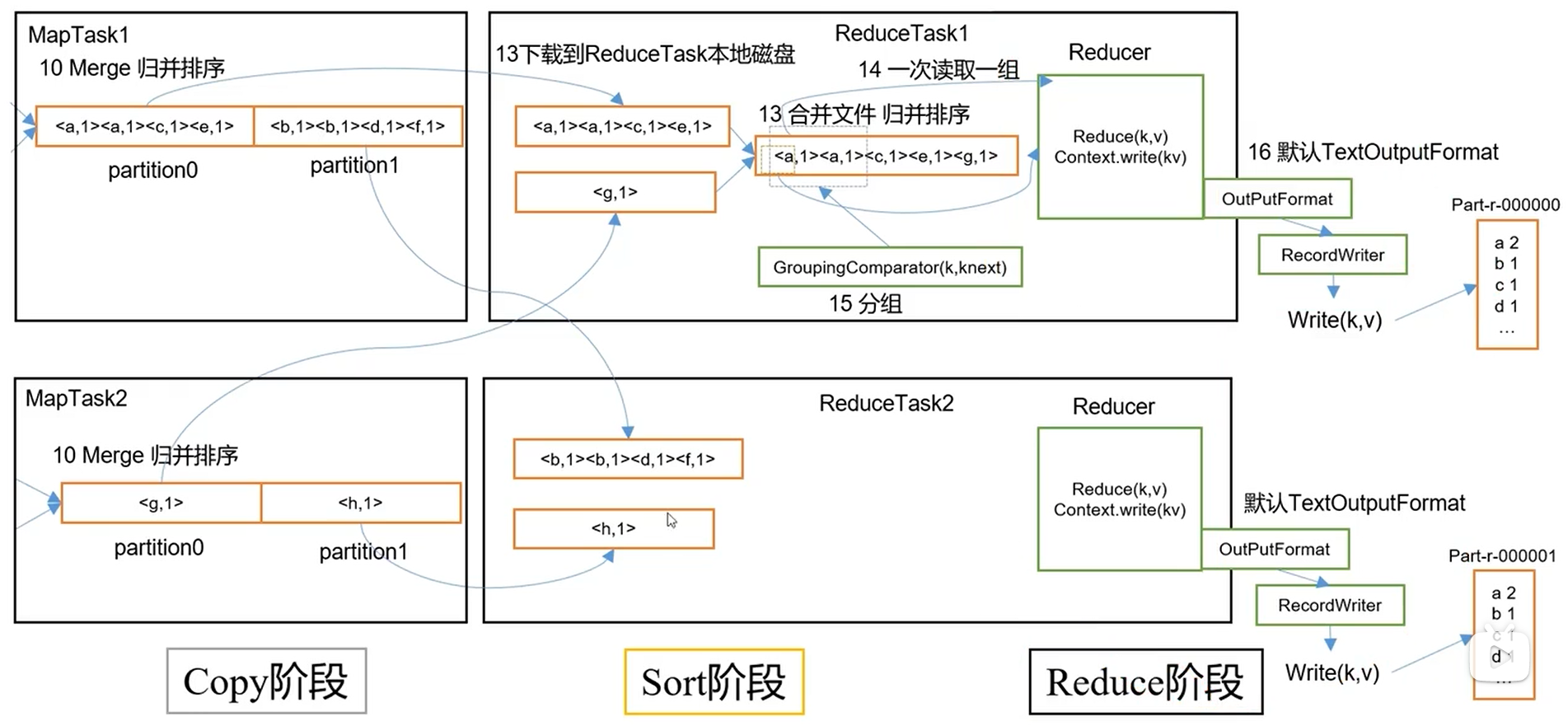
ReduceTask主动去抓取数据
5.3 ReduceTask并行度决定机制
MapTask并行度由切片个数决定,切片个数由输入文件和切片规则决定。
computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))
ReduceTask并行度由谁决定?
手动设置ReduceTask数量
//设置ReduceTasks的个数
job.setNumReduceTasks(5);
测试ReduceTask多少合适
注意事项
1.ReduceTask=0,表示没有Reduce阶段,输出文件个数和Map个数一致。
2.ReduceTask默认值就是1,所以输出文件个数为一个。
3.如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜(如136 1亿个,其他1个)
4.ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask。
5.具体多少个ReduceTask,需要根据集群性能而定。
6.如果分区数不是1,但是ReduceTask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。
MapReduce06 MapReduce工作机制的更多相关文章
- hadoop MapReduce 工作机制
摸索了将近一个月的hadoop , 在centos上配了一个伪分布式的环境,又折腾了一把hadoop eclipse plugin,最后终于实现了在windows上编写MapReduce程序,在cen ...
- MapReduce工作机制——Word Count实例(一)
MapReduce工作机制--Word Count实例(一) MapReduce的思想是分布式计算,也就是分而治之,并行计算提高速度. 编程思想 首先,要将数据抽象为键值对的形式,map函数输入键值对 ...
- hadoop知识点总结(一)hadoop架构以及mapreduce工作机制
1,为什么需要hadoop 数据分析者面临的问题 数据日趋庞大,读写都出现性能瓶颈: 用户的应用和分析结果,对实时性和响应时间要求越来越高: 使用的模型越来越复杂,计算量指数级上升. 期待的解决方案 ...
- 浅谈MapReduce工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- [hadoop读书笔记] 第五章 MapReduce工作机制
P205 MapReduce的两种运行机制 第一种:经典的MR运行机制 - MR 1 可以通过一个简单的方法调用来运行MR作业:Job对象上的submit().也可以调用waitForCompleti ...
- MapReduce工作机制
MapReduce是什么? MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,MapReduce程序本质上是并行运行的,因此可以解决海量数据的计算问题. MapReduce ...
- yarn/mapreduce工作机制及mapreduce客户端代码编写
首先需要知道的就是在老版本的hadoop中是没有yarn的,mapreduce既负责资源分配又负责业务逻辑处理.为了解耦,把资源分配这块抽了出来,形成了yarn,这样不仅mapreudce可以用yar ...
- 图文详解MapReduce工作机制
job提交阶段 1.准备好待处理文本. 2.客户端submit()前,获取待处理数据的信息,然后根据参数配置,形成一个任务分配的规划. 3.客户端向Yarn请求创建MrAppMaster并提交切片等相 ...
- MapReduce的工作机制
<Hadoop权威指南>中的MapReduce工作机制和Shuffle: 框架 Hadoop2.x引入了一种新的执行机制MapRedcue 2.这种新的机制建议在Yarn的系统上,目前用于 ...
随机推荐
- copy-list-with-random-pointer leetcode C++
A linked list is given such that each node contains an additional random pointer which could point t ...
- sort-list leetcode C++
Sort a linked list in O(n log n) time using constant space complexity. C++ /** * Definition for sing ...
- shell脚本 PHP+swoole的安装
#!bin/bash set -e # Check if user is root if [ $(id -u) != "0" ]; then echo "Error: p ...
- java 三大特性_继承、封装、多态_day005
一.继承: java的三大特性之一.两个类之间通过extends关键字来描述父子关系,子类便可拥有父类的公共方法和公共属性.子类可以继承父类的方法和属性,子类也可以自己定义没有的方法或者通过覆盖父类的 ...
- 设计模式学习-使用go实现原型模式
原型模式 定义 代码实现 优点 缺点 适用场景 参考 原型模式 定义 如果对象的创建成本比较大,而同一个类的不同对象之间差别不大(大部分字段都相同),在这种情况下,我们可以利用对已有对象(原型)进行复 ...
- SpringCloud 2020.0.4 系列之 Sleuth + Zipkin
1. 概述 老话说的好:安全不能带来财富,但盲目的冒险也是不可取的,大胆筹划,小心实施才是上策. 言归正传,微服务的特点就是服务多,服务间的互相调用也很复杂,就像一张关系网,因此为了更好的定位故障和优 ...
- Kali-Linux 2020如何设置中文
话不多说,直接上步骤 首先,想要修改系统默认语言普通用户是办不到的,这个时候就需要切换为root用户在终端输入 sudo su(切换用户指令,后面不加用户名就默认切换为root) 输入管理员密码后就像 ...
- HTML基本使用
HTML初识 (Hyper Text Markup Language): 超文本标记语言 「HTML骨架格式」 <!-- 页面中最大的标签 根标签 --> <html> < ...
- linux 入门系列-基础性知识
1:初探linux-基于centos7 运维和服务器硬件组合 两种登录方式:(1)-------root:管理员登录权限较高,不建议初学者使用格式: [root@centos7 jinlong]# ( ...
- 1组-Alpha冲刺-1/6
一.基本情况 队名:震震带着六菜鸟 组长博客:https://www.cnblogs.com/Klein-Wang/p/15526531.html 小组人数:7人 二.冲刺概况汇报 王业震 过去两天完 ...